对象的创建
对象的创建,当虚拟机接收到new指令,会去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查该引用是否已经被加载、解析和初始化过,如果没有则必须经历该过程。当类加载检查通过后,对象创建所需的堆内存空间在类加载期间就已经完全确定,接下来在堆中以指针碰撞、空闲表格等方式来划下对象在堆中的存储块。然后将虚拟机会将对象分配到的内存空间都初始化为零。最后将对象进行必要的设置,比如该对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄。
对象内存布局
上一部分我们讲到了对象的对象头,对象头是什么东西呢?下面我们讲解下对象在内存中的布局。以HotSpot虚拟机为例,对象在内存中的布局可以分为三部分:对象头、实例数据、对齐填充。
-
对象头
对象头包括两部分:第一部分用于存储对象自身的运行时数据:哈希码、GC分代、线程持有锁等信息;另一部分就是指类型指针,就是对象指向它的类元数据的指针,虚拟机通过这个指针来判断这个对象属于哪个类的实例。java数据对象的话,在头中还有一块记录数组长度的数据。 -
实例数据
该部分就是对象真正存储的有效数据区域,也就是我们在代码里面所定义的各种类型的字段内容。无论从父类继承下来的还是在子类中定义的,都需要记录下来。 -
对齐填充
不是必然存在的,也没特别的含义,仅仅是占位符的作用。由于hotspot的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,对象的大小必须是8字节倍数,而对象头的大小刚好是8字节的倍数(一倍或者二倍),因此,当对象实例数据部分没有对齐时,可以通过对齐填充进行补全。
对象访问定位
对象创建在java堆上,我们如何才能访问他们呢?其实,java程序需要通过栈上的一个reference字段数据来操作堆上的具体对象,即栈上的reference字段指向堆上的具体对象。目前主流的访问方式有两种:
-
使用句柄
如果使用句柄进行访问,那么java堆会划出一部分内存来作为句柄池,reference存储的对象就是句柄池中的句柄地址。句柄中包含了对象实例数据与类型数据各自的具体地址信息。 -
直接访问
如果是直接访问,那么java堆中就要包含一个指向方法区的该对象类型数据的指针(引用),而reference中包含的就直接是对象地址。
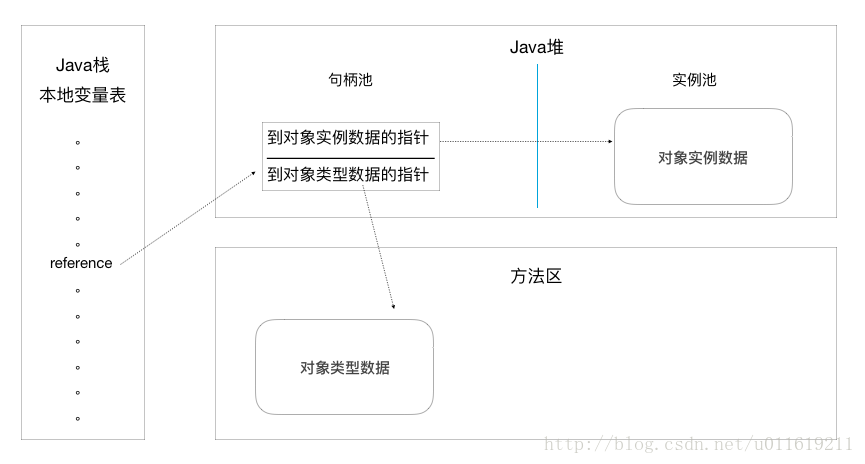
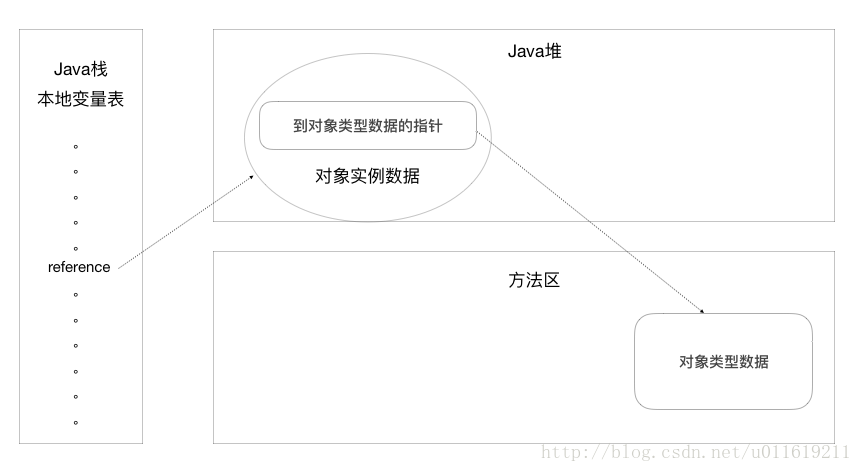
以上的这两种方式来说,使用句柄的好处就是reference中存储的是一个稳定的地址,在对象被移动的过程中,只会更新句柄中的实例数据指针,并不会改变reference中的数据;使用直接访问方式的话,它的访问速度就是更快。因为减少了一次指针的定位,这样节省了时间。因为对象的访问在java堆中十分频繁,所以这样的节省操作一直积累也会成为一个很可观的减少时间成本的操作。