一.哈希表基础
1. LeetCode上387号问题
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
案例:
s = "leetcode"
返回 0.
s = "loveleetcode",
返回 2.
注意事项:您可以假定该字符串只包含小写字母。
思路:
我们用数组记录26个字符对应出现的次数, 然后按目标单词中字母顺序遍历,第一个出现值为1的位置即答案。
解答:
class Solution {
public int firstUniqChar(String s) {
int[] freq = new int[26];
for(int i = 0 ; i < s.length() ; i ++)
freq[s.charAt(i) - 'a'] ++;
for(int i = 0 ; i < s.length() ; i ++)
if(freq[s.charAt(i) - 'a'] == 1)
return i;
return -1;
}
}
2. 引出哈希表的概念
答案中 int[26] freq 就是一个哈希表
每一个字符都和一个索引相对应
a -> 0
b -> 1 ----->>>>> index = ch - 'a' 即为 ---->>>>>O(1)复杂度的查找操作
c -> 2 哈希函数: f(ch) = ch - 'a'
...
z -> 25
3. 哈希表的难点
难点在于哈希函数: “键”转换为“索引”的过程
举例:
原始的键为 身份证号:110108198512166666
非常占用空间,我们希望将它转换为占用空间更小的索引
|
| 导致新问题
\|/
很难保证每一个"键"通过哈希函数的转换对应不同的索引
|
|
\|/
出现哈希冲突
|
|
\|/
在哈希表中解决哈希冲突
4. 本节概括:
1. 哈希表充分体现了算法设计领域的经典思想: 空间换时间
2. 哈希表是时间和空间之间的平衡
3. 哈希函数的设计是很重要的
4. “键”通过哈希函数得到的“索引”分布越均匀越好
二.哈希函数的设计
概括
“键”通过哈希函数得到的“索引”分布越均匀越好
对于一些特殊的领域, 有特殊领域的哈希函数设计方式甚至有专门的论文
这里主要关注一般的哈希函数的设计原则
处理整型
1. 小范围正整数直接使用
2. 小范围负整数进行偏移 -100~100 ---> 0~200
3. 大整数
比如身份证号:110108198512166666 ---> 11010819851216'6666'
通常做法: 取模 比如 取后四位。 等同于 mod 10000
但是如果 取后六位 mod 10000 ---> 110108198512'166666'
存在的问题1:
1216是生日,也就是说166666中前两位数
最大只能到31, 就会造成'分布不均匀'
所以需要 具体问题具体分析
存在的问题2:
没有利用其他位上的数字
一个简单的解决办法: 模一个素数 背后的数学理论超出博文范畴,不予讨论
网站: http://planetmath.org/goodhashtableprimes 可以查到对应整数范围该取的素数

处理浮点数
在计算机中都是32位或者64位的二进制表示,只不过计算机解析成了浮点数
我们可以将浮点数转为整型处理
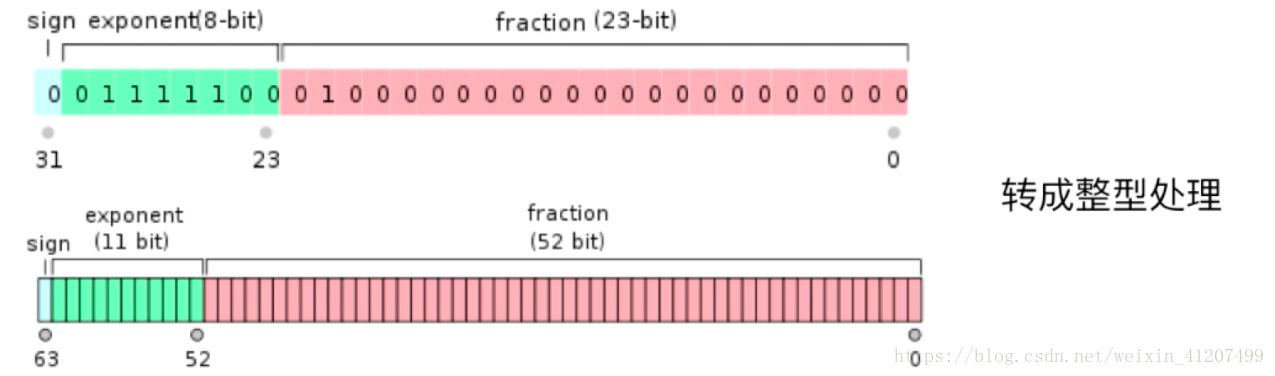
字符串
字符串依然可以 转为整型处理
举例:
166 = 1 * 10^2 + 6 * 10^1 + 6 * 10^0
'code' = 'c'* 26^3 + 'o'* 26^2 + 'd'* 26^1 + 'e'* 26^0
字符串看作26进制的大整型(进制可以选, 比如加入了大写字母就可以扩大进制)
这样哈希函数就是:
B表示进制 M表示素数
hash(code) = (c*B^3 + o*B^2 + d*B^1 + e*B^0) % M
hash(code) = ((((c*B) + o)*B + d)*B + e) % M
防止整型溢出,在做等价变换(模运算的性质):
hash(code) = ((((c%M) *B + o)%M *B + d)%M *B + e) % M
对应伪代码
int hash = 0
for(int i = 0; i < s.length(); i++)
hash = (hash * B + s.charAt(i)) % M
复合类型
依然可以 转为整型处理
举例 Date: year, moth, day
可以类比字符串的转换方式:
hash(date) = (((date.year%M)*B + date.month)%M*B + date.day)%M
哈希函数的设计原则
1. 一致性: 如果 a==b, 则hash(a) == hash(b)
2. 高效性: 计算高效方便
3. 均匀性: 哈希值均匀分布
三. Java中的hashCode方法
简单地使用java中自带地hashCode(只要是对象,默认都可以调用)
Main.java
public class Main {
public static void main(String[] args) {
int a = 42;
System.out.println(((Integer)a).hashCode());//a需要转化为 对象类Integer
int b = -42;
System.out.println(((Integer)b).hashCode());// hashCode与我们之前说的有些不同, 负整数哈希函数变换后不一定为正
double c = 3.1415926;
System.out.println(((Double)c).hashCode());
String d = "imooc";
System.out.println(d.hashCode());//String本来就是类 不用转换
System.out.println(Integer.MAX_VALUE + 1);
}
}
运行结果
42
-42
219937201
100327135
-2147483648
自定义对象Student.java
public class Student {
int grade;
int cls;
String firstName;
String lastName;
Student(int grade, int cls, String firstName, String lastName){
this.grade = grade;
this.cls = cls;
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public int hashCode(){
int B = 31;//B表示进制, 这里随便取
int hash = 0;
hash = hash * B + ((Integer)grade).hashCode();
hash = hash * B + ((Integer)cls).hashCode();
hash = hash * B + firstName.toLowerCase().hashCode();//可以直接食用String的hashCode
hash = hash * B + lastName.toLowerCase().hashCode();//逻辑上,大小写都表示一个人,所以转为小写字母
return hash;
}
}
在Main.java中调用student地hashCode
Main.java
...
Student student = new Student(3, 2, "jianeng", "shen");
System.out.println(student.hashCode());
...
结果
1638260971
还可以使用java自带地哈希数据结构 HashSet和HashMap
Main.java
import java.util.HashSet;//java提供的两个哈希相关的数据结构
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
...
HashSet<Student> set = new HashSet<>();
set.add(student);//哈希set的使用
HashMap<Student, Integer> scores = new HashMap<>();
scores.put(student, 100);//哈希map的使用
...
}
}
如果我们Student.java中没有重写hashCode, 依然可以对student类调用hashCode,默认会作为整型处理
我们注释掉 重写地hashCode, 再次运行Main.java, 此时student.hashCode()地打印值为
1550089733
而原来的,重写hashCode得到的值为1638260971
四. 链地址法 Seperate Chaining
哈希冲突的处理 : 链地址法
过程描述:
1. '键'经过 哈希函数处理之后,再去掉符号位就可以作为索引来存储数据
(hashCode(键) & 0x7fffffff) % M
2. 出现哈希冲突时, 同一位置上的数据将用链表的方式连起来。(这就是链地址法)
在java8之后,当哈希冲突达到一定程度后,会把链表转化为红黑树(即java中的TreeMap)



五. 实现属于我们自己的哈希表
为了测试的方便,我又搬来了以前常使用的一些程序,目录结构如下
.
├── pride-and-prejudice.txt
└── src
├── AVLTree.java
├── BST.java
├── FileOperation.java
├── HashTable.java
├── Main.java
└── RBTree.java
HahTable.java
import java.util.TreeMap;
public class HashTable<K, V> {
private TreeMap<K, V>[] hashtable;
private int size;//哈希表已存的元素个数
private int M;//哈希表具体有多少个位置, 可以自己定义
public HashTable(int M){
this.M = M;
size = 0;
hashtable = new TreeMap[M];
for(int i = 0 ; i < M ; i ++)
hashtable[i] = new TreeMap<>();
}
public HashTable(){
this(97);// M默认97
}
// 去掉符号位, 得到一个真正的索引
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % M;
}
public int getSize(){
return size;
}
public void add(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key)) //遇到传入重复的键, 我们更新数据
map.put(key, value);
else{
map.put(key, value);
size ++;
}
}
public V remove(K key){
V ret = null;
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key)){
ret = map.remove(key);
size --;
}
return ret;
}
public void set(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(!map.containsKey(key))
throw new IllegalArgumentException(key + " doesn't exist!");
map.put(key, value);
}
public boolean contains(K key){
return hashtable[hash(key)].containsKey(key);
}
public V get(K key){
return hashtable[hash(key)].get(key);
}
}
在Main.java中测试hashTable
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
System.out.println("Pride and Prejudice");
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("Total words: " + words.size());
// Collections.sort(words);
// Test BST
...
// Test AVL
...
// Test RBTree
...
// Test HashTable
startTime = System.nanoTime();
// HashTable<String, Integer> ht = new HashTable<>();
HashTable<String, Integer> ht = new HashTable<>(131071);
for (String word : words) {
if (ht.contains(word))
ht.set(word, ht.get(word) + 1);
else
ht.add(word, 1);
}
for(String word: words)
ht.contains(word);
endTime = System.nanoTime();
time = (endTime - startTime) / 1000000000.0;
System.out.println("HashTable: " + time + " s");
}
System.out.println();
}
}
结果
Pride and Prejudice
Total words: 125901
BST: 0.33005387 s
AVL: 0.31779805 s
RBTree: 0.402379367 s
HashTable: 0.271602422 s
哈希表开的空间M会严重影响到它的速度, 我们应该根据数据量的不同来设置M值。
我们需要改进哈希表, 使得M可以自适应数据量的大小。
六. 哈希表的动态空间处理与复杂度分析

要是哈希表时间复杂度变为O(log(1)), 我们需要将M变为自适应。
思路:
平均每个地址承载的元素多过一定程度,即扩容 N/M >= upperTol
平均每个地址承载的元素少过一定程度,即缩容 N/M <= lowerTol
而扩容的原理与之前的关于动态数组博文中的方法类似
代码编写
HashTable.java
import java.util.Map;
import java.util.TreeMap;
public class HashTable<K, V> {
private static final int upperTol = 10; //平均每个位置哈希冲突的上界
private static final int lowerTol = 2; //平均每个位置哈希冲突的下界
private static final int initCapacity = 7;//初始的容量
private TreeMap<K, V>[] hashtable;
private int size;
private int M;
public HashTable(int M){
this.M = M;
size = 0;
hashtable = new TreeMap[M];
for(int i = 0 ; i < M ; i ++)
hashtable[i] = new TreeMap<>();
}
public HashTable(){
this(initCapacity);
}
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % M;
}
public int getSize(){
return size;
}
public void add(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key))
map.put(key, value);
else{
map.put(key, value);
size ++;
if(size >= upperTol * M) //为了防止浮点化 由size/m >= upperTol变化而来
resize(2 * M);
}
}
public V remove(K key){
V ret = null;
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key)){
ret = map.remove(key);
size --;
if(size < lowerTol * M && M / 2 >= initCapacity) //太小会 缩容 但不会小于initCapacity
resize(M / 2);
}
return ret;
}
public void set(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(!map.containsKey(key))
throw new IllegalArgumentException(key + " doesn't exist!");
map.put(key, value);
}
public boolean contains(K key){
return hashtable[hash(key)].containsKey(key);
}
public V get(K key){
return hashtable[hash(key)].get(key);
}
private void resize(int newM){
TreeMap<K, V>[] newHashTable = new TreeMap[newM];
for(int i = 0 ; i < newM ; i ++)
newHashTable[i] = new TreeMap<>();
int oldM = M;
this.M = newM;
for(int i = 0 ; i < oldM ; i ++){ //这里M的变化 需要注意,容易出错
TreeMap<K, V> map = hashtable[i];
for(K key: map.keySet())
newHashTable[hash(key)].put(key, map.get(key));
}
this.hashtable = newHashTable;
}
}
再次运行Main.java进行测试
Pride and Prejudice
Total words: 125901
BST: 0.3300964512 s
AVL: 0.320891094 s
RBTree: 0.305721141 s
HashTable: 0.183768075 s
现在哈希表性能明显更高。
七. 哈希表更复杂的动态空间处理方法
之前代码存在的问题:
扩容后 M -> 2*M
2*M不是素数
解决方案:
将素数提前存好,需要扩容或缩容时调用
HashTable.java
import java.util.TreeMap;
public class HashTable<K extends Comparable<K>, V> {
// 素数存放好,扩容或缩容时调用,1610612741差不多是整型哈希表可以承载的极限
private final int[] capacity
= {53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469,
12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741};
private static final int upperTol = 10;
private static final int lowerTol = 2;
private int capacityIndex = 0;
private TreeMap<K, V>[] hashtable;
private int size;
private int M;
public HashTable(){
this.M = capacity[capacityIndex]; //所有容量都从素数的数组中取, 包括初始值
size = 0;
hashtable = new TreeMap[M];
for(int i = 0 ; i < M ; i ++)
hashtable[i] = new TreeMap<>();
}
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % M;
}
public int getSize(){
return size;
}
public void add(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key))
map.put(key, value);
else{
map.put(key, value);
size ++;
if(size >= upperTol * M && capacityIndex + 1 < capacity.length){ //防止越界
capacityIndex ++;
resize(capacity[capacityIndex]);
}
}
}
public V remove(K key){
V ret = null;
TreeMap<K, V> map = hashtable[hash(key)];
if(map.containsKey(key)){
ret = map.remove(key);
size --;
if(size < lowerTol * M && capacityIndex - 1 >= 0){//缩容即 索引剪1, 也要防止越界
capacityIndex --;
resize(capacity[capacityIndex]);
}
}
return ret;
}
public void set(K key, V value){
TreeMap<K, V> map = hashtable[hash(key)];
if(!map.containsKey(key))
throw new IllegalArgumentException(key + " doesn't exist!");
map.put(key, value);
}
public boolean contains(K key){
return hashtable[hash(key)].containsKey(key);
}
public V get(K key){
return hashtable[hash(key)].get(key);
}
private void resize(int newM){
TreeMap<K, V>[] newHashTable = new TreeMap[newM];
for(int i = 0 ; i < newM ; i ++)
newHashTable[i] = new TreeMap<>();
int oldM = M;
this.M = newM;
for(int i = 0 ; i < oldM ; i ++){
TreeMap<K, V> map = hashtable[i];
for(K key: map.keySet())
newHashTable[hash(key)].put(key, map.get(key));
}
this.hashtable = newHashTable;
}
}
哈希表的效率高: 均摊复杂度O(1)
但也有代价: 牺牲了顺序性
在java中 集合set和映射map
基于平衡树的是 TreeSet和TreeMap
基于哈希表的是 HashSet和HashMap
我们自己实现的哈希表的Bug:
哈希表本身不需要传入的key是可比较的, 但当哈希冲突时采用了TreeMap是需要可比较的key。
导致我们的哈希表其实是只能传入可比较的key