字典显示:
1)、tang.keys() #显示键值
2)、tang.values() #显示值
3)、tang.items() #显示键值:值;返回列表
tang.iteritems() #显示键值:值;返回迭代器
一、字典显示,items()与iteritems()区别。
字典的items()方法和iteritems()方法,是python字典的内建函数,分别会返回Python列表和迭代器。
python字典的items方法作用:是可以将字典中的所有项,以列表方式返回。因为字典是无序的,所以用items方法返回字典的所有项,也是没有顺序的。
python字典的iteritems方法作用:与items方法相比作用大致相同,只是它的返回值不是列表,而是一个迭代器。
补充迭代器,迭代对象于生成器关系:
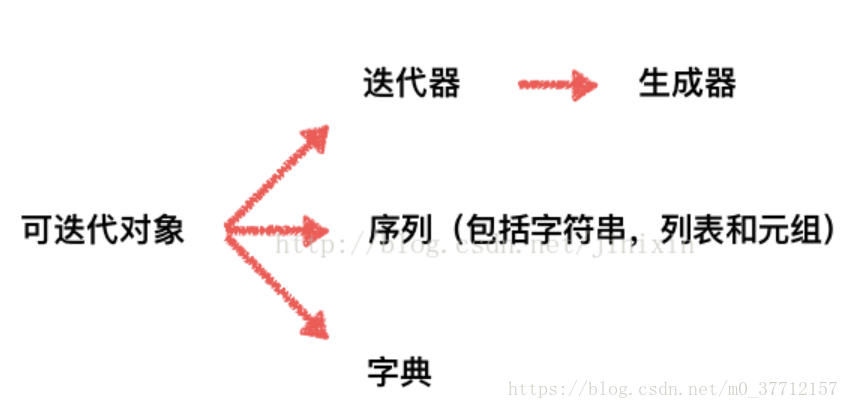
字典items()操作方法:
x = {'title':'python web site','url':'www.iplaypy.com'}
>>> x.items()
[('url', 'www.iplaypy.com'), ('title', 'python web site')]
a=x.items()
>>> a
[('url', 'www.iplaypy.com'), ('title', 'python web site')]
>>> type(a)
<type 'list'>从结果中可以看到,items()方法是将字典中的每个项分别做为元组,添加到一个列表中,形成了一个新的列表容器。如果有需要也可以将返回的结果赋值给新变量,这个新的变量就会是一个列表数据类型。
dict iteritems()操作方法:
f = x.iteritems()
>>> f <dictionary-itemiterator object at 0xb74d5e3c>
>>> type(f)
<type 'dictionary-itemiterator'> #字典项的迭代器
>>> list(f)
[('url', 'www.iplaypy.com'), ('title', 'python web site')]字典.iteritems()方法在需要迭代结果的时候使用最适合,而且它的工作效率非常的高。
二、operator.itemgetter函数
operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号(即需要获取的数据在对象中的序号),下面看例子。
a = [1,2,3]
b=operator.itemgetter(1) //定义函数b,获取对象的第1个域的值>
print b(a) //2
b=operator.itemgetter(1,0) //定义函数b,获取对象的第1个域和第0个的值
print b(a) //(2, 1)要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。
用 operator 函数进行多级排序
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10),]
>>> sorted(students, key=itemgetter(1,2)) # sort by grade then by age
[('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
## 对字典排序
>>> d = {'data1':3, 'data2':1, 'data3':2, 'data4':4}
>>> sorted(d.iteritems(), key=itemgetter(1), reverse=True)
[('data4', 4), ('data1', 3), ('data3', 2), ('data2', 1)]三、sorted和sort
sort() 是Python列表的一个内置的排序方法,list.sort() 方法排序时直接修改原列表,返回None;
sorted() 是Python内置的一个排序函数,它会从一个迭代器返回一个排好序的新列表。
相比于 sort(),sorted() 使用的范围更为广泛,但是如果不需要保留原列表,sort更有效一点。另外,sort() 只是列表的一个方法,只适用于列表,而sorted() 函数接受一切迭代器,返回新列表。
两者的函数形式分别如下:
sorted(iterable[, key][, reverse])
list.sort(*, key=None, reverse=None)这两个方法有以下 2 个共同的参数:
key 是带一个参数的函数,返回一个值用来排序,默认为 None。这个函数只调用一次,所以fast。
reverse 表示排序结果是否反转
看例子:
a = (1,2,4,2,3) # a 是元组,故不能用sort() 排序
>>> a.sort()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple' object has no attribute 'sort'
>>> sorted(a) # sorted() 可以为元组排序,返回一个新有序列表
[1, 2, 2, 3, 4]
>>> a=['1',1,'a',3,7,'n']
>>> sorted(a)
[1, 3, 7, '1', 'a', 'n']
>>> a # sorted() 不改变原列表
['1', 1, 'a', 3, 7, 'n']
>>> print a.sort()
None
>>> a # a.sort()直接修改原列表
[1, 3, 7, '1', 'a', 'n']因此如果实际应用过程中需要保留原有列表,使用 sorted() 函数较为适合,否则可以选 择 sort() 函数,因为 sort() 函数不需要复制原有列表,消耗的内存较少,效率也较高。
sorted() 函数功能非常强大,它可以方便地针对不同的数据结构进行排序,从而满足不同需求。例子如下:
对字典进行排序:
>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'}) # 根据字典键排序
[1, 2, 3, 4, 5]
>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'}.values()) # 根据字典值排序
['A', 'B', 'B', 'D', 'E']对多维列表排序:
>>> student_tuples = [('john', 'A', 15),('jane', 'B', 12),('dave', 'B', 10)]
>>> sorted(student_tuples, key = lambda student: student[0]) # 对姓名排序
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
>>> sorted(student_tuples, key = lambda student: student[2]) # 年龄排序
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]调用operator模块中的 itemgetter() 可以实现根据多个参数排序:
>>> sorted(student_tuples, key = itemgetter(2)) # 根据年龄排序
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
>>> sorted(student_tuples, key = itemgetter(1, 2)) # 根据成绩和年龄排序
[('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
>>> sorted(student_tuples, key = itemgetter(1, 2), reverse=True) # 反转排序结果
[('jane', 'B', 12), ('dave', 'B', 10), ('john', 'A', 15)]