版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shuiliusheng/article/details/82634584
Bootstrapping: Using SMT Hardware to Improve Single-Thread Performance(2018)
摘要:解耦前瞻性(DLA)体系结构已被证明是提高单线程性能的有效方法。然而,默认实现需要一个额外的核心。虽然SMT风格是可能的,但是简单的实现是低效的,因此很慢。在本文中,我们提出了一种优化的实现,称为Bootstrapping,它使得DLA在单个(SMT)核上的效率与使用两个核一样高。虽然融合两个核心可以提高1.23x的单线性能,但是Bootstrapping加速1.51
处理器核的设计瓶颈:虽然有更多的核心,特点核更大的结构,但是基本的乱序执行的设计与20多年前没有什么不同,IPC也停滞不前。因此对于通用处理器而言,提高单线程性能仍然是核心设计目标
DLA:(decoupled look-ahead)为期望的预取或者分支预测,执行一个单独的,持续的前瞻线程
- DLA更加通用,因为它不依赖于特定的访问模式来发出预取
- 由于所需要的资源是另一个线程的上下文,因此可以灵活地分配资源,以改进单个线程或执行不同的线程
Bootstrapping对DLA设计进行一些简单的调整
- 调整cache的控制逻辑,允许cache有效地包含这两个上下文
- 通过资源分配,最大化线程对的性能
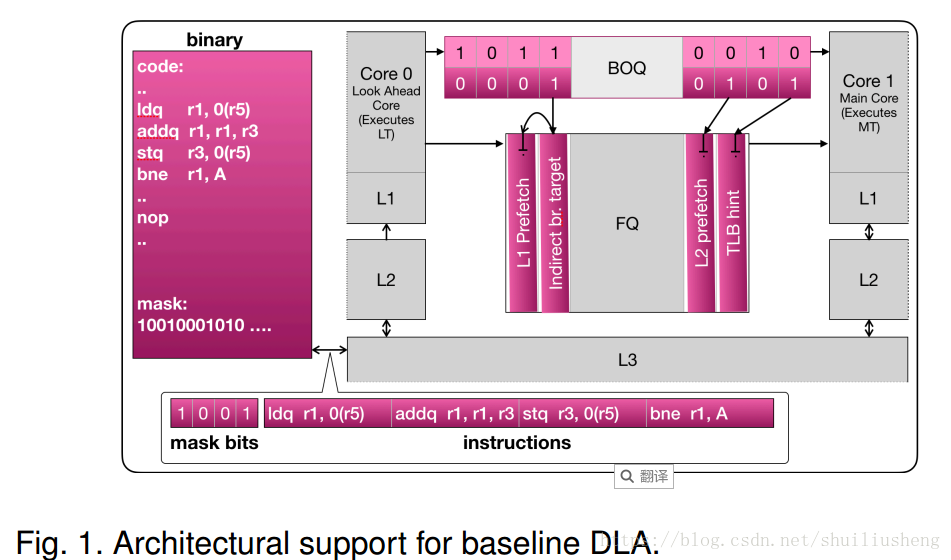
基本的DLA结构设计:利用自动二进制分析离线生成原始程序二进制文件的骨架结构。骨架中包括所有的控制指令和它们的向后依赖链,同时还包含了一部分内存指令,作为预取有效负载以及它们的向后依赖链。执行时,这个框架形成的LT线程在不同的内核上运行,传递相关信息,从而加速主线程MT的执行
- Containment of speculation(遏制推测执行):保持LT的私有cache state在系统的其它部分是不可见的
- Communication of look-ahead results:构建一种机制来明确传递前瞻执行的结果。使用两个FIFO队列,一个用于分支预测方向的分支结果队列(BOQ,branch outcome queue),另一个是用于较不频繁但更宽的数据的Footnote queue(FQ)
- 支持指令屏蔽:LT的框架结构表示为一组bits,用于屏蔽不需要的指令。
The key challenge in DLA design is to keep LT fast and yet accurate in order to achieve deep, sustained look-ahead
Bootstrapping in SMT
- Cache Control:尽管SMT支持同时执行多个线程,但是LT线程执行得到的数据是推测性数据,系统其它部分不应该使用。此时最小的支持是在LT所写的行中添加一个speculative bit,将它们与其他行区分开来
- Adaptive Resource Allocation :控制每个线程占用的重新排序缓冲区(ROB)条目的数量。我们以容量的1/16的增量来做。fetch阶段将以循环方式从两个线程中获取,跳过已经达到指定容量的线程。
- 更好的分配硬件资源:根据程序行为,将执行过程划分为可识别的代码段的执行,并针对每个段进行不同的资源分配的调整。一个简单有效的方法:识别某些backward branches,称为特征分支。要决定最佳的资源分配,我们只需对所有配置进行试错。我们使用有限状态机和一个表来跟踪试验过程和迄今为止的最佳配置。当一个特征分支的试验完成时,在稳定状态下,我们使用最好的配置。
优化DLA在SMT的基础上执行的方法:
- Fast reboot:当LT执行到错误的方向时,LT需要reboot。在SMT总,初始化寄存器状态能够非常的快,因此能够极大的加快reboot
- Prioritization:为分配更多资源的线程分配更高的优先级。但是性能优势很小
- Register utilization:LT没有正确性约束,因此可以尽早回收寄存器以更好地利用。