版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shuiliusheng/article/details/83213441
Pushing the Limits of Accelerator Efficiency While Retaining Programmability
-
摘要:
- DSAs(domain specific accelerators)为了提高性能,牺牲了可编程性。DSAs由于适用领域得不稳定,很容易过时,而且会出现重复设计和重复验证的成本。当一个设备需要多个DSA时,面积成本会很大。
- 论文探讨了在可编程的结构下,能够得到接近于DSA的性能,能效和面积效率
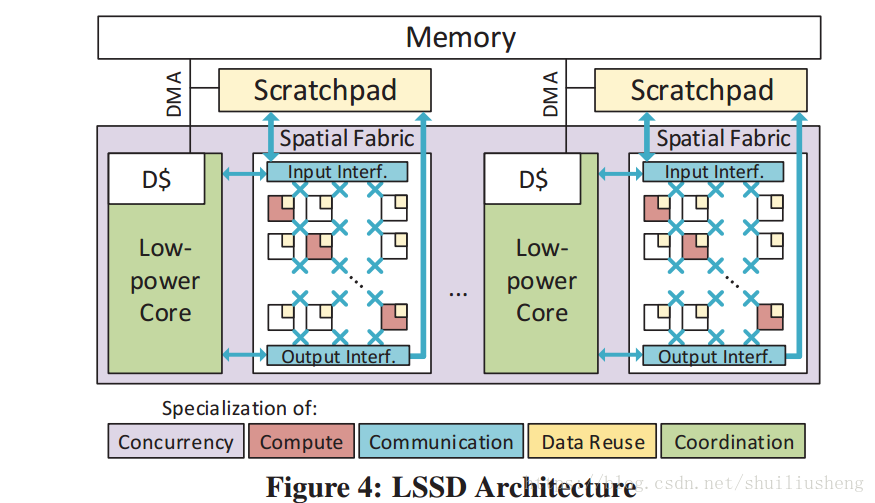
- 论文提出了一种名为LSSD的架构,它由许多低功耗和微型核组成,每一个core都具有可配置的空间架构,暂存器和DMA
- 结果表明:可编程的,专门的体系结构确实可以与特定领域的方法相竞争
-
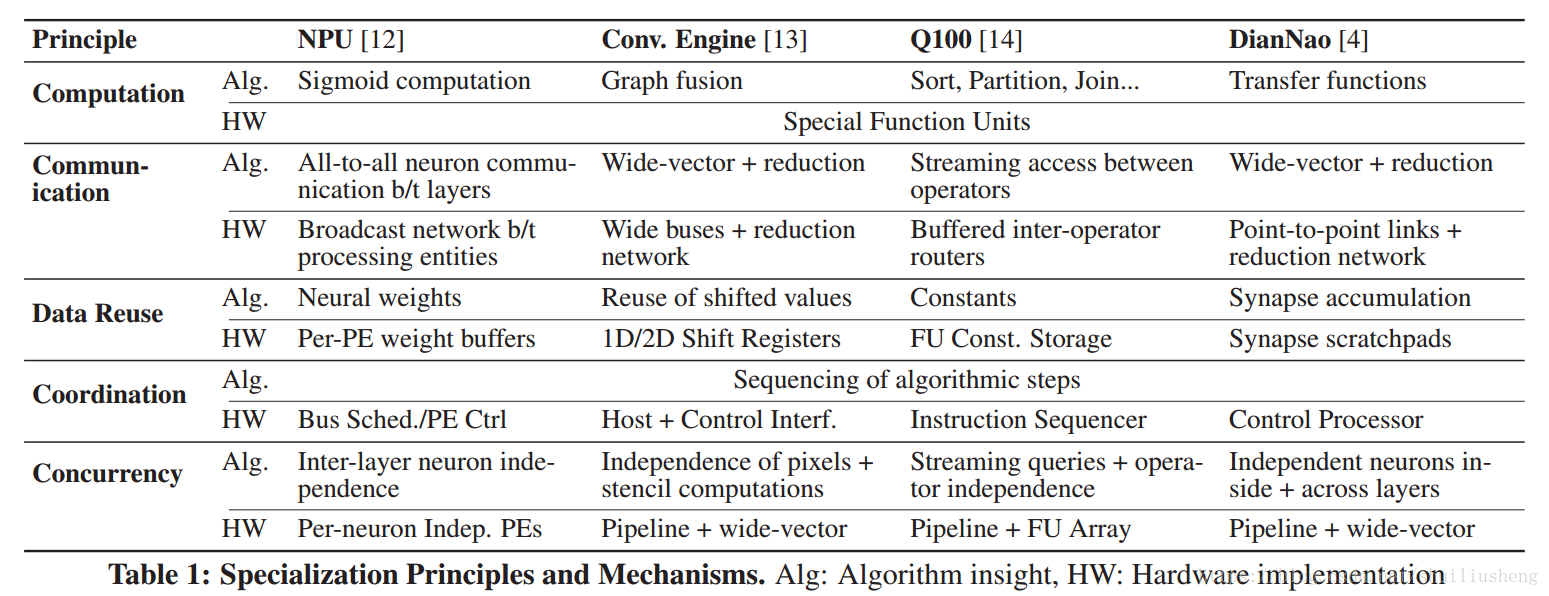
论文的观察:尽管DSAs在设计选择上有很大的差异,但是它们都采用了类似的一套特定的原则:
- 将硬件的并发性和巨大的加速算法中的并行性进行匹配
- 用于计算的特定问题的功能单元
- 单元之间的显式数据通信,而不是类似于通用ISA中的利用共享REG/MEM的隐式通信
- 为数据重用定制的结构
- 其他硬件单元的协调控制采用低功耗、简单的硬件
-
如何通过组合传统的可编程和可配置的微体系结构机制来到达DSAs设计时的原则
- 为了充分利用算法中典型的巨大的并发性,最直观的策略是适用许多微小的,低功耗的内核
- 为了提高core的高度计算能力,为每一个核增加一个空间结构,空间的网络结构专用于操作数通信,功能单元FUs可以专用于算法的专用计算
- 为了实现特定的数据重新,增加锁存器
- 为了特定的memory之间的通信,增加DMA进行管理
- 为了协调各种硬件资源,使用一个低功耗核来进行管理
-
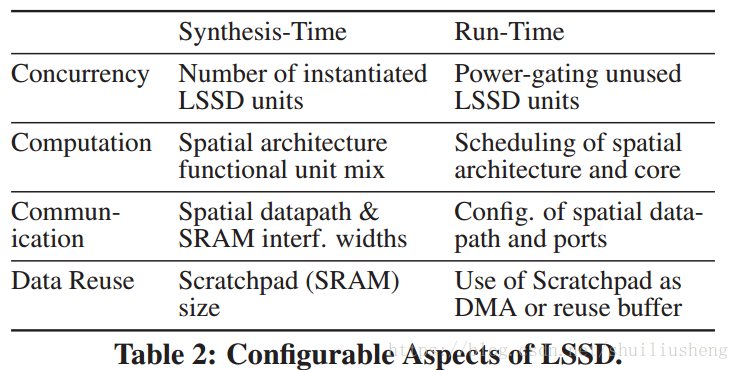
论文提出的上述的体系结构称为LSSD。LSSD的设计和使用分为三个阶段:
- synthesis(综合):确定了所选域的性能、功率和区域约束,以决定FU的类型和数量,锁存器的大小等
- programming(编程):使用带有注释的标准编程语言来指定每种算法
- run-time:根据不同的需求,重新配置硬件特征
-
适用于DSAs的工作负载的特征
- 负载有很高的并行性,包括数据级或者线程级
- 有一定的计算工作
- 有较粗粒度的工作单元
- 存储访问具有一定的规律
-
DSAs的高效设计中的五个专门化原则
- 并发的专门化:工作负载的并发是指能够同时操作的程度。对于高度并发的专门化是指通过产生较低的开销结构来组织硬件并行执行工作。例如采用多个独立的PU和控制器。使用硬件提高并发性,可以提高性能和效率,同时功耗也会随着线性增长
- 计算专门化:使用特定的硬件构成的功能单元FUs来加速算法中的某些计算,例如Sigmoid函数的计算。这种FUs一般是很少的输入,一个输出。这种方式能够改善性能和功耗
- 通信的专门化:通信是指在存储和功能部件之间的数据传输。专门的通信即为硬件单元之间的通信通道和潜在的buffer,以此来加快FUs的数据获取。专门的通信会减少功耗和面积
- 数据重用的专门化:数据重用是一个算法属性,用于表示中间结果可以被使用多次。专门化的数据重用意味着使用存储结构保存中间结果。这种方式对性能和功耗都有好处
- 协调专有化:硬件单元和其工作时间管理。例如指令排序,控制流,信号解码,地址生成等都是协调的工作。
-
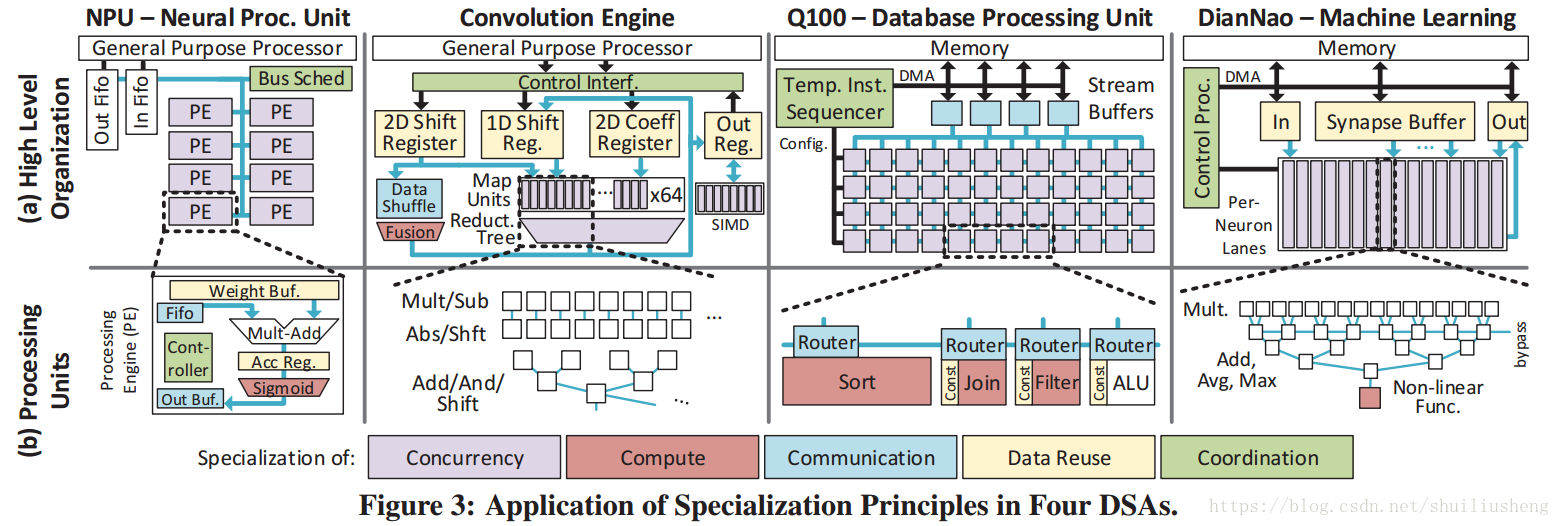
四种加速器介绍
- NPU:利用神经网络算法进行近似计算的DSA,通过FIFO接口集成到主机内核中。
- NPU在设计时主要利用神经网络的每一层的并发性,通过使用多个并行的处理实体(PEs)来同时流水化处理器八个神经元的计算。
- NPU通过增加累加寄存器和PE的权重缓冲来利用数据重用
- 在通信方面,NPU采用广播的方式处理神经网络中的通信。
- 在计算方面,NPU专门化了sigmoid计算单元
- 在协调方面,通过使用bus调度器和PE控制器来完成
- Convolution引擎:加速模板(卷积模板)的(stencil-like)计算。主机core通过控制接口协调硬件的控制。
- 在并发性方面,采用向量和流水线的并行性来实现
- 在数据重用方面,使用自定义的内存来存储像素和系数
- 在通信方面,和其他更宽的总线一起完成
- 在计算方面,提供了特定的graph-fusion单元
- Q100:使用DSAs加速流数据库的查询操作,主要特带在于数据库操作的流水线并发上和中间的输出
- 使用stream buffers预取需要使用的数据库的列
- 通信方面,在FU之间提供动态的路由通道,以防止内存的溢出
- 计算方面,提供定制的数据库操作的功能单元,类似于Join,sort和partition
- 数据重用方面,在FU内部存储常量,同时重用中间结果
- 使用指令定序器(instruction sequencer)来协调管理通信网络的配置和流缓冲器
- DianNao:为深度神经网络加速的DSA
- 使用非常宽的向量计算模型来提供高并发性
- 使用更宽的存储结构来重用神经元,累加值,突触
- 特殊的计算单元sigmoid
- FUs之间的点对点通信
- 使用特殊的控制处理器来协调工作
- NPU:利用神经网络算法进行近似计算的DSA,通过FIFO接口集成到主机内核中。
-
LSSD的设计(low-power cores, spatial architecture, scratchpad, DMA)
- 如何利用并发性:高并发和可编程性的要求——一系列微小的低功耗核,通过内存进行通信(并行单元之间一般几乎没有通信,所以使用内存进行通信是合理的)
- 如何管理相互之间的通信:使用显式路由网络(ISA可见,以消除动态路由的硬件开销)。该网络设计为一种空间体系结构。同时这种空间体系结构的其他用处在于定义FU的位置,辅助计算相关的常量值的重用。另一方面,增加DMA和可配置的锁存器,以及空间架构的矢量接口(输入和输出),以管理全局的内存之间的通信
- 协调硬件的机制:例如配置空间架构,管理DMA和计算之间的同步等。使用低功耗的core本身来管理
- 总结:每一个LSSD单元:一个低功耗核,一个空间结构,一个锁存器和一个DMA
-
LSSD在实际中的使用:设计综合+代码设计
- 设计综合(design synthesis):根据需要使用的领域,选择硬件参数
- 通过检查一个或者多个工作负载或者是相应的领域,选择适当的功能单元,数据通路,暂存器大小和宽度,核心的个数等
- 主要的设计约束是性能,同时包括吞吐量目标,功耗和面积的最小化,同时保持一定的通用性和可编程性
- LSSD的设计过程:1. 选择最通用的单输出的FUs,来适配算法;2. 决定FU的个数,根据期望的吞吐量;3. 将FUs划分为组,每个组每周期只访问一部分数据。数据的每周期的访问上限为64B,此时锁存器的大小对于大多数算法都很合理。划分的组数即为LSSD的个数;4. 如果算法在一个小的工作集中具有重用性,则重新更改SRAM条目的个数进行匹配
- 代码设计(programing):生成程序和空间上的数据通路配置来实现算法
- 为core设计协调代码,为空间的数据通路生成配置数据以匹配可用的硬件资源
- 在协调代码中,会插入通信指令和 控制DMA访问流输入数据的指令
- 设计综合(design synthesis):根据需要使用的领域,选择硬件参数