版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_37050372/article/details/83218680
数据如下:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"1193","rate":"4","timeStamp":"978300760","uid":"1"}
{"movie":"1193","rate":"2","timeStamp":"978300760","uid":"1"}
{"movie":"1193","rate":"1","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"3114","rate":"4","timeStamp":"978302174","uid":"1"}
{"movie":"608","rate":"4","timeStamp":"978301398","uid":"1"}
{"movie":"1246","rate":"4","timeStamp":"978302091","uid":"1"}
{"movie":"1245","rate":"2","timeStamp":"978299200","uid":"2"}
{"movie":"1246","rate":"5","timeStamp":"978299418","uid":"2"}
{"movie":"3893","rate":"1","timeStamp":"978299535","uid":"2"}
{"movie":"1247","rate":"5","timeStamp":"978298652","uid":"2"}
{"movie":"3421","rate":"4","timeStamp":"978298147","uid":"3"}
{"movie":"1641","rate":"2","timeStamp":"978298430","uid":"3"}
{"movie":"648","rate":"3","timeStamp":"978297867","uid":"3"}
{"movie":"1394","rate":"4","timeStamp":"978298147","uid":"3"}
{"movie":"3534","rate":"3","timeStamp":"978297068","uid":"3"}
{"movie":"1968","rate":"4","timeStamp":"978297068","uid":"3"}
{"movie":"1136","rate":"5","timeStamp":"978298079","uid":"3"}
{"movie":"2081","rate":"4","timeStamp":"978298504","uid":"3"}
{"movie":"3468","rate":"5","timeStamp":"978294008","uid":"4"}
{"movie":"1210","rate":"3","timeStamp":"978293924","uid":"4"}
{"movie":"2951","rate":"4","timeStamp":"978294282","uid":"4"}
{"movie":"2987","rate":"4","timeStamp":"978243170","uid":"5"}
{"movie":"1466","rate":"3","timeStamp":"978245695","uid":"5"}
{"movie":"860","rate":"2","timeStamp":"978244493","uid":"5"}
{"movie":"1683","rate":"3","timeStamp":"978246108","uid":"5"}
{"movie":"3565","rate":"4","timeStamp":"978238288","uid":"6"}
{"movie":"1028","rate":"4","timeStamp":"978237767","uid":"6"}
{"movie":"34","rate":"4","timeStamp":"978237444","uid":"6"}
{"movie":"648","rate":"4","timeStamp":"978234737","uid":"7"}
{"movie":"1270","rate":"4","timeStamp":"978234581","uid":"7"}
{"movie":"457","rate":"5","timeStamp":"978234786","uid":"7"}
{"movie":"1573","rate":"4","timeStamp":"978234874","uid":"7"}
{"movie":"861","rate":"4","timeStamp":"978234874","uid":"7"}1.将数据使用flume导入hdfs
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /root/flumedata/
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://marshal:9000/moviedata/
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize = 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = Text
agent1.sinks.sink1.hdfs.rollSize = 1024
agent1.sinks.sink1.hdfs.rollCount = 100
agent1.sinks.sink1.hdfs.rollInterval = 20
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 1
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1导入语句:
bin/flume-ng agent -c conf -f myconf/file-hdfs.conf -n agent1 -Dflume.root.logger=INFO,console首先创建表并将原始数据导入hive表:
#创建表
create table first_movie(str string);
#将hdfs中的数据导入hive表
load data inpath '/moviedata/*' into table first_movie;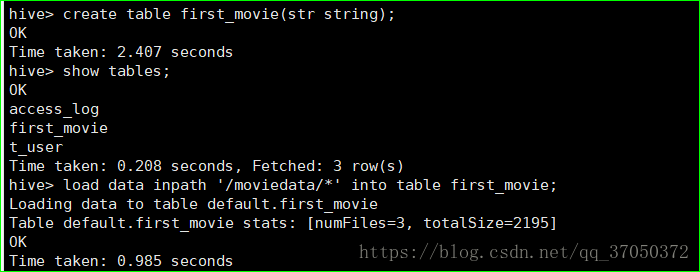
数据清洗:
用hive的自定义函数将json串进行转换,转换为标准的表:
然后写自定义函数的Java程序:
Movie类:
package com.test.hive.udf;
public class Movie {
private String movie;
private int rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public int getRate() {
return rate;
}
public void setRate(int rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public Movie(String movie, int rate, String timeStamp, String uid, int counts) {
super();
this.movie = movie;
this.rate = rate;
this.timeStamp = timeStamp;
this.uid = uid;
}
public Movie() {
super();
// TODO Auto-generated constructor stub
}
@Override
public String toString() {
return movie +"," + rate + "," + timeStamp + "," + uid;
}
}
自定义函数类:
package com.test.hive.udf;
import java.io.IOException;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.JsonParseException;
import org.codehaus.jackson.map.JsonMappingException;
import org.codehaus.jackson.map.ObjectMapper;
public class MovieInfoParser extends UDF{
//重写evaluate方法
//数据:zhangsan:18:beijing|male|it
public String evaluate(String line,int index) throws Exception{
ObjectMapper o = new ObjectMapper();
Movie movie = o.readValue(line, Movie.class);
String str = movie.toString();
String[] split = str.split(",");
return split[index-1];
}
public static void main(String[] args) {
}
}打成jar包,并在hive中添加jar包的环境:
add jar /root/udf.jar;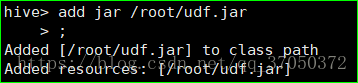
使用这个jar包的环境创建临时函数:
create temporary function mparse as 'com.test.hive.udf.MovieInfoParser';
使用这个临时函数,对原始数据进行操作,将操作后的数据生成一张新表。
create table second_movie
as
select mparse(str,1) as movie,
mparse(str,2) as rate,
mparse(str,3) as time,
mparse(str,4) as uid
from first_movie;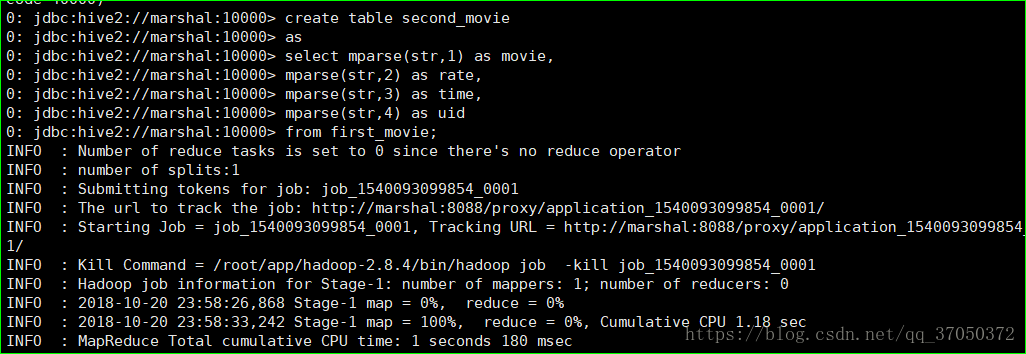
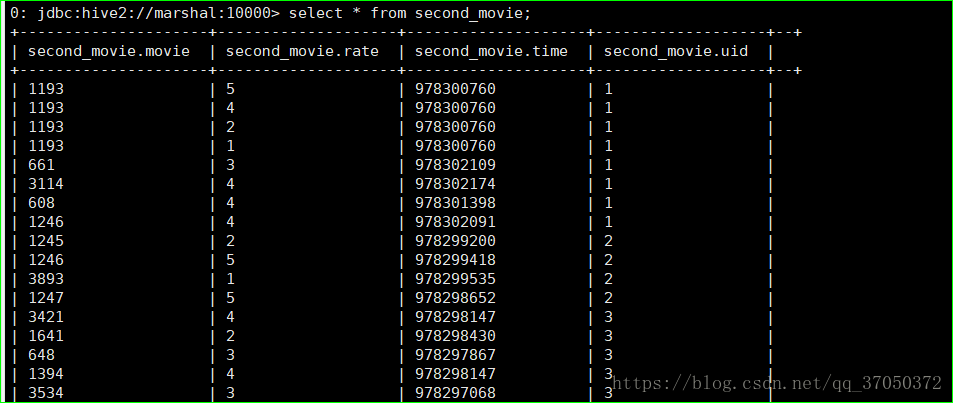
第一个维度分析:
求评分最高的前五个:
将查询出来的结果存入新表top5:
create table top5 as select movie,rate from second_movie order by 'rate' desc limit 5;查询结果:
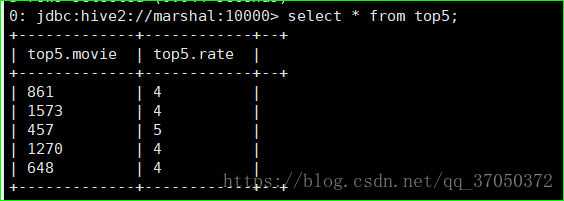
第二个维度分析:
求每个用户的评分的平均分
create table avg_movie as select uid,avg(rate) as rate_avg from second_movie group by uid;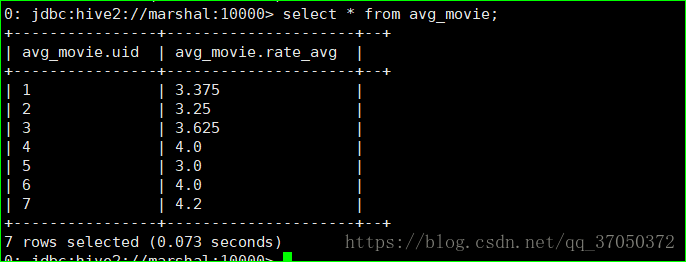
用sqoop将分析的数据导出:
bin/sqoop export
--connect jdbc:mysql://marshal:3306/sqooptest
--username root
--password 123456
--export-dir /user/hive/warehouse/top5
--table top5
--input-fields-terminated-by '\001' --m 1bin/sqoop export
--connect jdbc:mysql://marshal:3306/sqooptest
--username root
--password 123456
--export-dir /user/hive/warehouse/avg_movie
--table avg_movie
--input-fields-terminated-by '\001' --m 1导出结果:
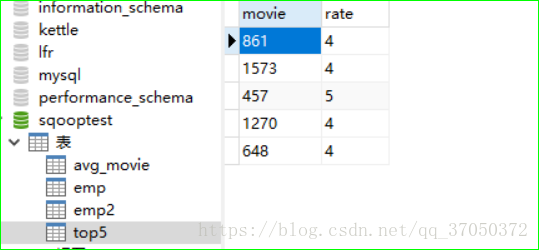
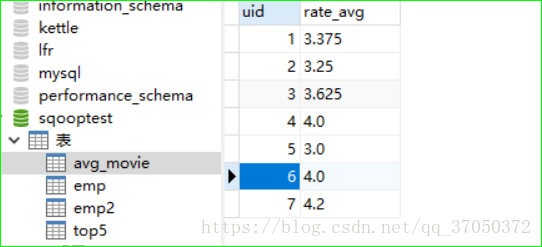
可视化:
top5可视化:
代码如下:
"""
可视化评分最高的电影top5
"""
import pymysql
from pyecharts import Bar
from pyecharts import Pie
from pyecharts import Page
# 创建数据库连接
db = pymysql.connect("marshal", "root", "123456", "sqooptest")
cursor = db.cursor()
# SQL语句
sql = "select * from top5"
# 定义横坐标
movie_id = list()
# 定义纵坐标
movie_rate = list()
#获取数据据数据
def get_dataSet():
# 执行SQL语句
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有数据
results = cursor.fetchall()
except:
print("Error")
return results
if __name__ == '__main__':
results = get_dataSet()
for item in results:
movie_id.append(item[0])
movie_rate.append(item[1])
print(movie_id)
print(movie_rate)
# 定义一个页
page = Page()
# 生成柱状图
bar_movie_top = Bar("movie_top5柱状图", height=600, width=1200)
bar_movie_top.add("movie", movie_id, movie_rate, mark_point=['max', 'min', 'average'], is_more_utils=True)
# 生成饼图
pie_movie_top = Pie("movie_top5饼图", title_pos="center", title_top="50", height=600, width=1200)
pie_movie_top.add("movie", movie_id, movie_rate, is_random=True, radius=[30, 70], is_more_utils=True)
page.add(bar_movie_top)
page.add(pie_movie_top)
page.render("movie_top.html")执行结果:
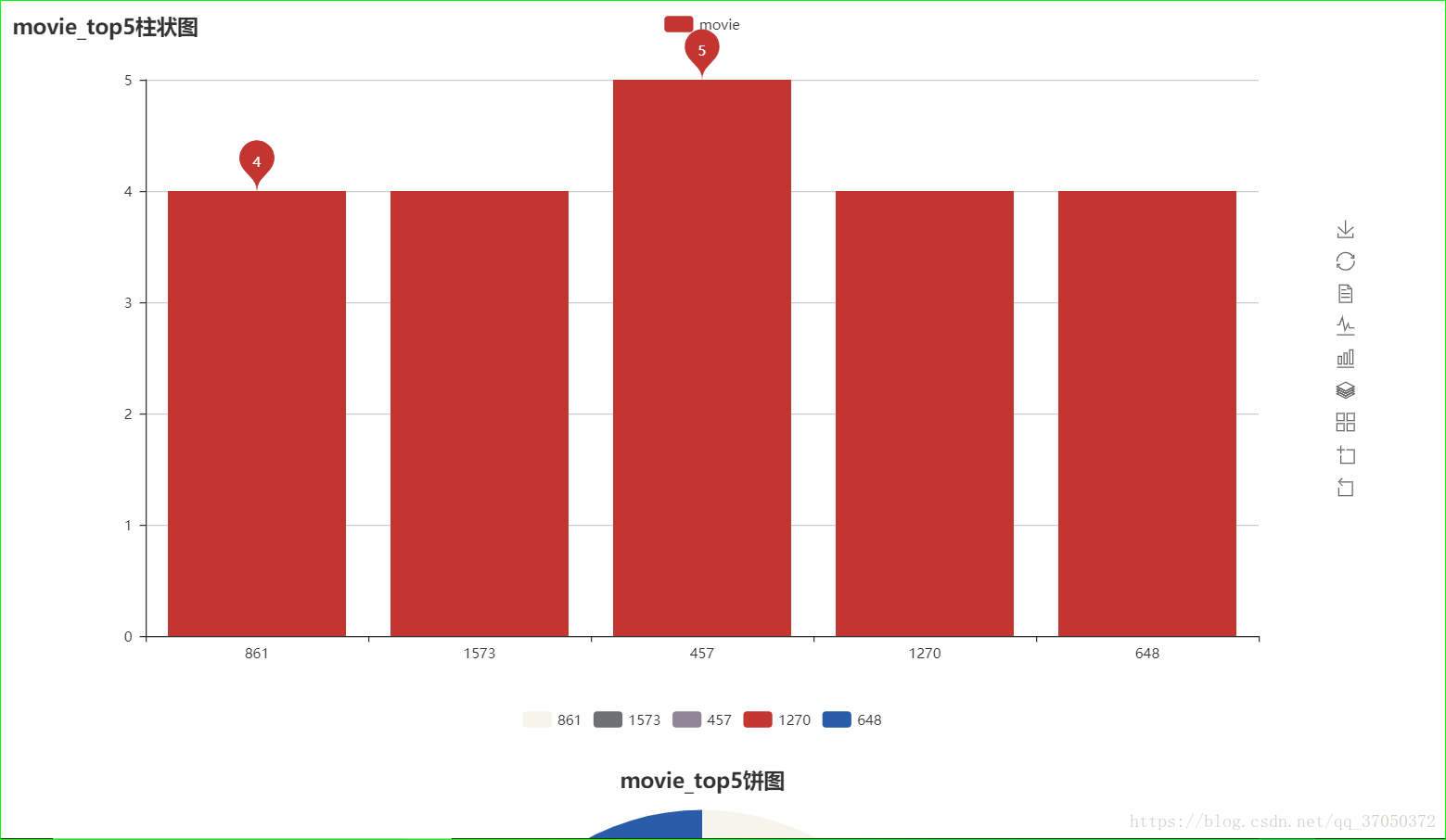
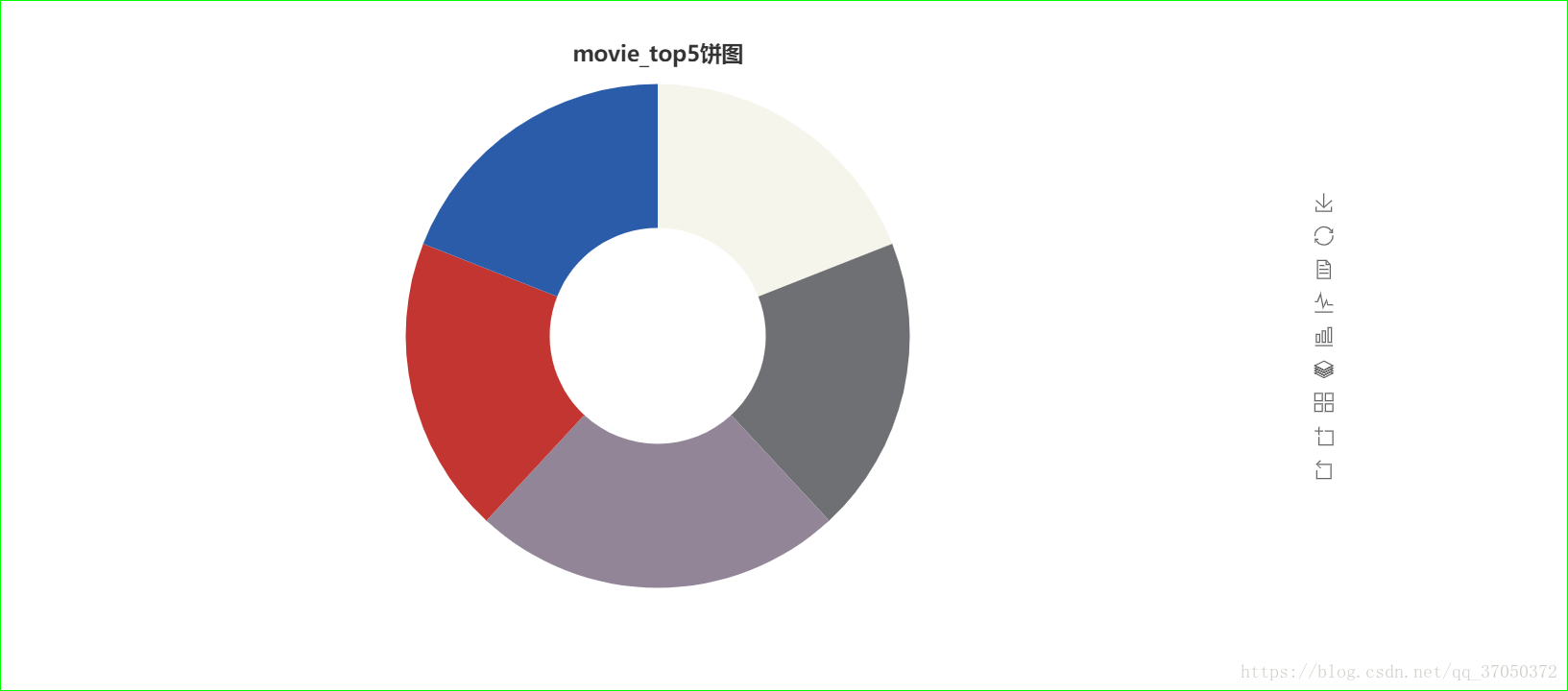
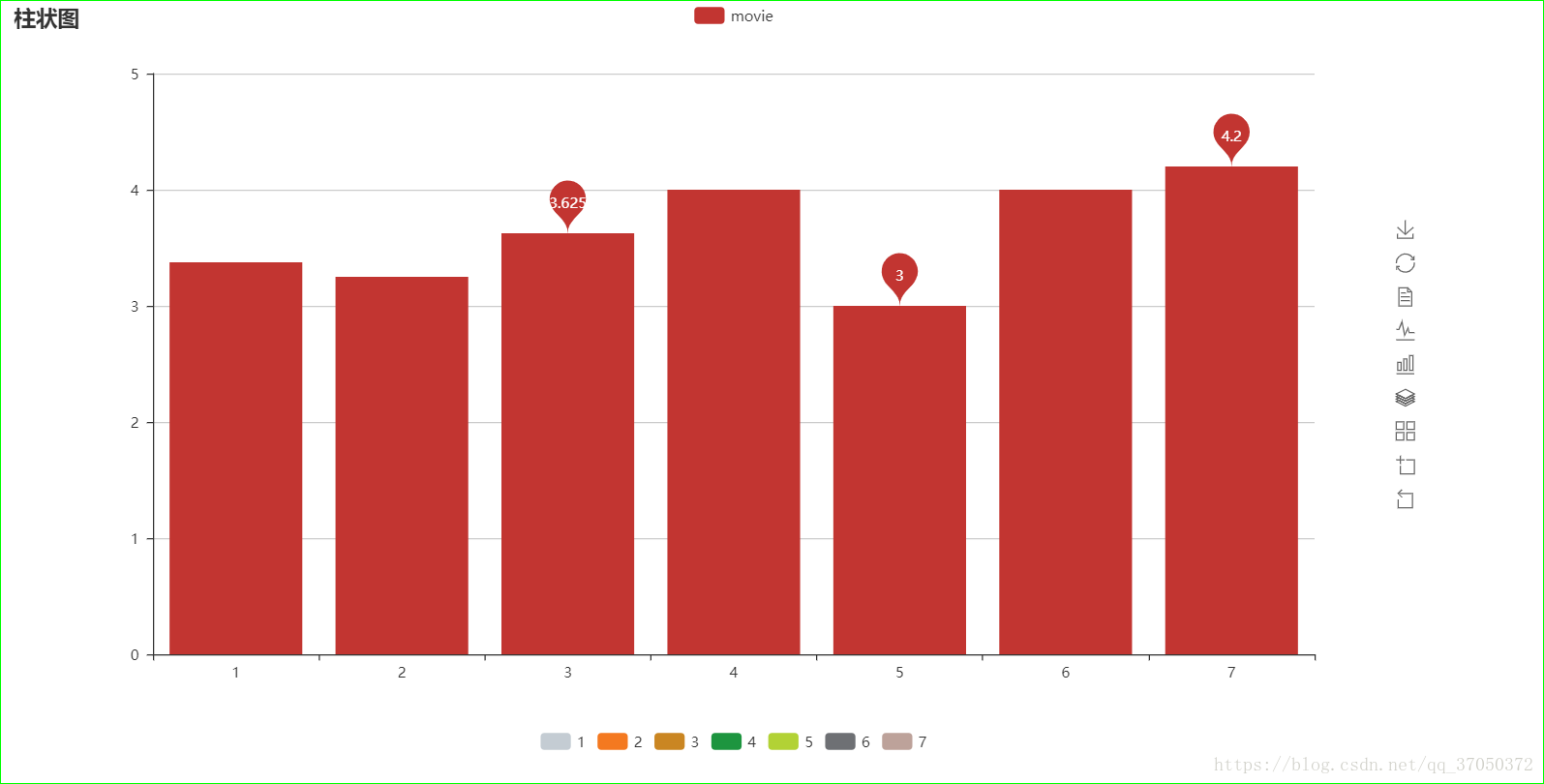
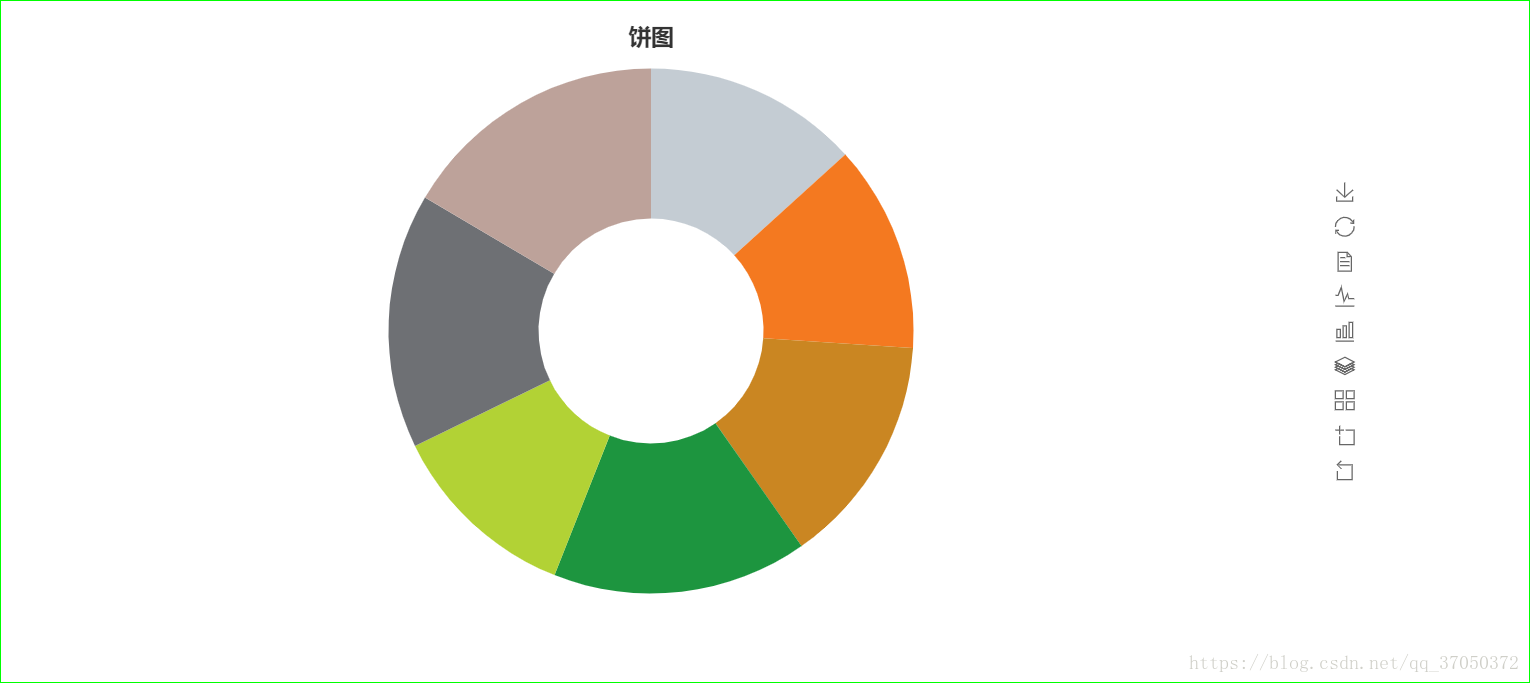
平均分可视化:
"""
可视化每个用户的电影评分平均分
"""
import pymysql
from pyecharts import Bar
from pyecharts import Pie
from pyecharts import Page
# 创建数据库连接
db = pymysql.connect("marshal", "root", "123456", "sqooptest")
cursor = db.cursor()
# SQL语句
sql = "select * from avg_movie"
# 定义横坐标
user_id = list()
# 定义纵坐标
avg_rate = list()
#获取数据据数据
def get_dataSet():
# 执行SQL语句
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有数据
results = cursor.fetchall()
except:
print("Error")
return results
if __name__ == '__main__':
results = get_dataSet()
for item in results:
user_id.append(item[0])
avg_rate.append(item[1])
print(user_id)
print(avg_rate)
# 定义一个页
page = Page()
# 生成柱状图
bar_uid_avg = Bar("柱状图", height=600, width=1200)
bar_uid_avg.add("movie", user_id, avg_rate, mark_point=['max', 'min', 'average'], is_more_utils=True)
# 生成饼图
pie_uid_avg = Pie("饼图", title_pos="center", title_top="50", height=600, width=1200)
pie_uid_avg.add("movie", user_id, avg_rate, is_random=True, radius=[30, 70], is_more_utils=True)
page.add(bar_uid_avg)
page.add(pie_uid_avg)
page.render("uid_avg.html")执行结果: