第二十一天 – hive补充 – hive分区、分桶 – hive数据导入导出
文章目录
一、Hive基础补充
使用的表及表数据
-
dept
CREATE TABLE dept( deptno int, dname string, loc string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;10,ACCOUNTING,NEW YORK 20,RESEARCH,DALLAS 30,SALES,CHICAGO 40,OPERATIONS,BOSTON -
emp
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal int, comm int, deptno int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile7369,SMITH,CLERK,7902,1980-12-17,800,null,20 7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30 7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30 7566,JONES,MANAGER,7839,1981-04-02,2975,null,20 7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30 7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30 7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10 7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20 7839,KING,PRESIDENT,null,1981-11-17,5000,null,10 7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30 7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20 7900,JAMES,CLERK,7698,1981-12-03,950,null,30 7902,FORD,ANALYST,7566,1981-12-02,3000,null,20 7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
- left join 、left outer join 、left semi join:以左表为准连接右表,如果右表连接不上将null替代
select
e1.ename
from emp e
left join emp e1
on e.mgr = e1.empno
where e.ename = "JONES"
;
select
e1.ename
from emp e
left outer join emp e1
on e.mgr = e1.empno
where e.ename = 'JONES'
;
=======
select
d.*
from dept d
left semi join emp e
on e.deptno = d.deptno and e.deptno is null
;
select
d.*
from dept d
left semi join emp e
on e.deptno = d.deptno
where e.deptno is null
;
- right join 、right outer join:右连接,以右表准,连接左表,如果左表连接不上用null替代
hive不支持右半开连接,即不支持right semi join
select
e1.ename
from emp e
right join emp e1
on e.mgr = e1.empno
where e.ename = 'JONES'
;
- 多表用"," 、 join 、 inner join:内连接,两张表能相互关联即可
select
e1.ename
from emp e
inner join emp e1
on e.mgr = e1.empno
where e.ename = 'JONES'
;
select
e1.ename
from emp e,emp e1
where e.mgr = e1.empno and e.ename = 'JONES'
;
-
full join 、 full outer join : 全连接、全外链接
-
hive在1.2.2是默认开启了使用map端join查询;但是在hive的一些老版本中没有默认开启map-join,需要使用出MAPJOIN()来触发执行mapjoin,MAPJOIN()虽然已经过时,但是也可以使用,
select
/*+MAPJOIN(d)*/
d.dname name,
max(e.sal) high_sal
from dept d
inner join emp e
on d.deptno = e.deptno
group by d.dname,e.deptno
;
-
所有join的on只支持等值连接,on后可以有and,不支持<> != < > 等,永远是小表(结果集)驱动大表(结果集),小表放左边。
-
group by:分组,通常和聚合函数搭配使用
select后面的字段要么在group by中出现过,要么在聚合函数里面。 -
having:对分完组之后的结果进行过滤,通常和group by搭配使用
having后是可以用聚合函数,而where不行 -
order by:全局排序,全局即对所有的reducer进行排序,一般reducer只有一个。
sort by :局部排序,对每一个redcuer中的数据排序。当只有一个reducer的时候,sort by 和 order by一样。
默认用升序,asc,降序desc -
distribute by:将map中的数据分到哪一个reduce中,默认也有。
-
cluster by:兼有distribute by 和 sort by的功能,既能能指定distribute by,也能sort by,但是sort by必须是升序。
select
sal sal
from emp
cluster by sal
;
==========以上等价于以下
select
sal
from emp
distribute by sal
sort by sal desc
;
- union : 将一个或者多个结果集进行合并,该合并会排序去重。
union all :量一个或者多个结果集进行合并,排序但不会去重。
select
d.deptno id,
d.dname name
from dept d
union
select
e.empno id,
e.ename name
from emp e
;
select
d.deptno id,
d.dname name
from dept d
union
select
d.deptno id,
d.dname name
from dept d
;
=================
select
d.deptno id,
d.dname name
from dept d
union all
select
d.deptno id,
d.dname name
from dept d
;
select
d.deptno id,
d.dname name
from dept d
union all
select
d.deptno id,
d.dname name
from dept d
limit 2
;
注意:
多个union的子集中的字段个数、字段的名称(名称不一样的起别名)、字段类型需要保持一致。
单个union子句不支持order by 、group by、distribute by等。
orderByClause clusterByClause distributeByClause sortByClause limitClause
二、Hive分区
hive分区的目的
hive为了避免全表扫描,从而引进分区技术来将数据进行划分。减少不必要数据的扫描,从而提高效率。
hive分区和mysql分区的区别
mysql分区字段用的是表内字段;而hive分区字段采用表外字段。
hive的分区技术
- hive的分区字段是一个伪字段,但是可以用来进行操作。
- 分区字段不进行区分大小写
- 分区可以是表分区或者分区的分区,可以有多个分区
hive分区根据
看业务,只要是某个标识能把数据区分开来。比如:年、月、日、地域、性别等
分区关键字
partitioned by(字段)
分区本质
在表的目录或者是分区的目录下在创建目录,分区的目录名为指定字段=值
hive分区练习
create table if not exists u1(
id int,
name string,
age int
)
partitioned by(dt string)
row format delimited fields terminated by ' '
stored as textfile
;
u1
1 xm1 16
2 xm2 18
3 xm3 22
u2
11 xh1 26
22 xh2 28
33 xh3 30
导入数据
load data local inpath ‘/home/userdata/u1’ into table u1 partition(dt=“2018-10-14”);
load data local inpath ‘/home/userdata/u115’ into table u1 partition(dt=“2018-10-15”);
加载数据后,在hdfs中查看目录

查看分区
select * from u1 where dt=‘2018-10-15’;
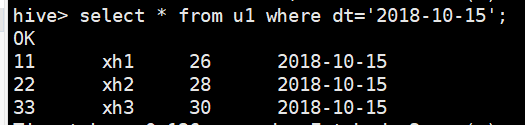
hive分区练习2 – 二级分区
create table if not exists u2(
id int,
name string,
age int
)
partitioned by(month int,day int)
row format delimited fields terminated by ' '
stored as textfile
;
u1914
1 xm1 16
2 xm2 18
u1915
3 xm3 22
u11014
11 xh1 26
u11015
22 xh2 28
33 xh3 30
导入数据
load data local inpath ‘/home/userdata/u1914’ into table u2 partition(month=9,day=14);
load data local inpath ‘/home/userdata/u1915’ into table u2 partition(month=9,day=15);
load data local inpath ‘/home/userdata/u11014’ into table u2 partition(month=10,day=14);
load data local inpath ‘/home/userdata/u11015’ into table u2 partition(month=10,day=15);
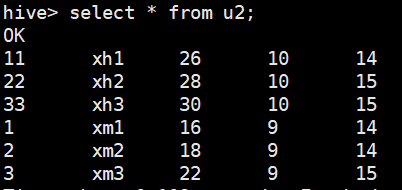
hive分区修改
查询分区
show partitions u1;
增加分区
alter table u1 add partition(dt=“2018-10-16”);
alter table u1 add partition(dt=“2018-10-16”) partition(dt=“2018-10-17”);
alter table u1 add partition(dt=“2018-10-19”) location “/user/hive/warehouse/test.db/u1/dt=2018-10-16/”;
修改分区(手动修改元数据信息)
alter table u1 partition(dt=“2018-10-16”) rename to partition(dt=“2018-10-26”);
修改已存在分区的路径
alter table u1 partition(dt=“2018-10-19”) set location “hdfs://qianfeng/user/hive/warehouse/test.db/u1/dt=2018-10-14/”;
删除分区
alter table u1 drop partition(dt=“2018-10-27”);
alter table u1 drop partition(dt=“2018-10-26”),partition(dt=“2018-10-19”);
三、hive动态分区
参数设置
hive.exec.dynamic.partition=true; 是否允许动态分区
hive.exec.dynamic.partition.mode=strict/nostrict; 动态区模式为严格模式
strict:严格模式,最少需要一个静态分区列(需指定固定值)
nostrict:非严格模式,允许所有的分区字段都为动态。
hive.exec.max.dynamic.partitions=1000; 允许最大的动态分区
hive.exec.max.dynamic.partitions.pernode=100; 单个节点允许最大分区
创建动态分区表
动态分区表的创建语句与静态分区表相同,不同之处在与导入数据,静态分区表可以从本地文件导入,但是动态分区表需要使用from…insert into语句导入。
create table if not exists u3(
id int,
name string,
age int
)
partitioned by(month int,day int)
row format delimited fields terminated by ' '
stored as textfile
;
导入数据,将u2表中的数据加载到u3中:
from u2
insert into table u3 partition(month,day)
select id,name,age,month,day
;
混合分区
create table if not exists u4(
id int,
name string,
age int
)
partitioned by(month int,day int)
row format delimited fields terminated by ' '
stored as textfile
;
导入数据
from u2
insert into table u4 partition(month=9,day)
select id,name,age,day
where month=9
;
hive的mr的执行模式
set hive.mapred.mode=strict/nostrict;
在严格模式下,有以下限制:
1、Cartesian Product.笛卡尔积,没有任何where和on的连接查询。
2、No partition being picked up for a query.对分区表查询不带分区字段做过滤。
3、Orderby without limit.order by不带limit
4、Comparing bigints and strings.
5、Comparing bigints and doubles.
如下不能运行
select
*
from u4
;
select
*
from u4 u
join u3 uu
;
select
*
from u4
order by id
;
四、hive分桶
分桶目的作用
更加细致地划分数据;对数据进行抽样查询,较为高效;可以使查询效率提高
分桶原理关键字
分桶字段是表内字段,默认是对分桶的字段进行hash值,然后再模于总的桶数,得到的值则是分区桶数。
bucket
clustered by(id) into 4 buckets
分桶的本质
在表目录或者分区目录中创建文件。
分桶案例
分四个桶
create table if not exists u5(
id int,
name string,
age int
)
partitioned by(month int,day int)
clustered by(id) into 4 buckets
row format delimited fields terminated by ' '
stored as textfile
;
对分桶的数据不能使用load的方式加载数据,使用load方式加载不会报错,但是没有分桶的效果。
为分桶表添加数据,需要设置set hive.enforce.bucketing=true;
首先将数据添加到u2表中
1 xm1 16
2 xm2 18
3 xm3 22
4 xh4 20
5 xh5 22
6 xh6 23
7 xh7 25
8 xh8 28
9 xh9 32
load data local inpath ‘/home/userdata/bu’ into table u2 partition(month=9,day=10);
from u2
insert into table u5 partition(month=9,day=10)
select id,name,age
where month = 9
and day = 10
;
对分桶进行查询:tablesample(bucket x out of y on id)
x:表示从哪个桶开始查询
y:表示桶的总数,一般为桶的总数的倍数或者因子。
x不能大于y。
select * from u5 tablesample(bucket 1 out of 4 on id); 查询到三条数据
select * from u5 tablesample(bucket 2 out of 4 on id);查询到两条数据
select * from u5 tablesample(bucket 1 out of 2 on id); 1 1+4/2=3 3+4/2=5 查询到五条数据
select * from u5 tablesample(bucket 1 out of 8 on id) where age > 22; 查询到一条数据
随机查询
select * from u5 order by rand() limit 3;
select * from u5 tablesample(3 rows);
select * from u5 tablesample(30 percent); 按表的百分比查询
select * from u5 tablesample(3G);
select * from u5 tablesample(3K); B、k、M、G 按要查询的数据大小查询
分区与分桶的对比
分区使用表外的字段,分桶使用表内字段
分区可以使用load加载数据,而分桶就必须要使用insert into方式加载数据
分区常用;分桶少用
五、hive数据导入导出
hive数据导入
-
load从本地加载
-
load从hdfs中加载
-
insert into方式加载
-
location指定
-
like指定,克隆
create table if not exists u7 like u6;
alter table u8 add partition(month=9,day=10);
create table if not exists u9 like u6 location “hdfs://qianfeng/user/hive/warehouse/gp1801.db/u6/month=9/day=10”; -
ctas语句指定(create table as)
-
手动将数据copy到表目录
hive数据导出
- insert into方式导出
- insert overwrite local directory:导出到本地某个目录
- insert overwrite directory:导出到hdfs某个目录
insert overwrite local directory '/home/uesedata/out/00'
select id,name from u2;
insert overwrite local directory '/home/uesedata/out/01'
row format delimited fields terminated by ','
select id,name from u2;
insert overwrite directory 'hdfs://bigdata/out/01'
row format delimited fields terminated by ','
select id,name from u11;
导出到文件
hive -S -e “use gp1801;select * from u2” > /home/out/02/result