* Map集合和Collection集合的区别?
* Map集合存储元素是成对出现的,Map集合的键是唯一的,值是可重复的。可以把这个理解为:夫妻对
* Collection集合存储元素是单独出现的,Collection的儿子List是可重复的,Set是唯一的。可以把这个理解为:光棍(11.11)
* 注意:
* Map集合的数据结构值针对键有效,跟值无关
* HashMap,TreeMap等会讲。
* Collection集合的数据结构是针对元素有效
* Map集合的功能概述:
* 1:添加功能
* V put(K key,V value):添加元素。这个其实还有另一个功能?先不告诉你,等会讲
* 如果键是第一次存储,就直接存储元素,返回null
* 如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
* 2:删除功能
* void clear():移除所有的键值对元素
* V remove(Object key):根据键删除键值对元素,并把值返回
* 3:判断功能
* boolean containsKey(Object key):判断集合是否包含指定的键
* boolean containsValue(Object value):判断集合是否包含指定的值
* boolean isEmpty():判断集合是否为空
* 4:获取功能
* Set<Map.Entry<K,V>> entrySet():???
* V get(Object key):根据键获取值
* Set<K> keySet():获取集合中所有键的集合
* Collection<V> values():获取集合中所有值的集合
* 5:长度功能
* int size():返回集合中的键值对的对数
1 // 创建集合对象 2 Map<String, String> map = new HashMap<String, String>(); 3 4 // 创建元素并添加元素 5 map.put("邓超", "孙俪"); 6 map.put("黄晓明", "杨颖"); 7 map.put("周杰伦", "蔡依林"); 8 map.put("刘恺威", "杨幂"); 9 10 // V get(Object key):根据键获取值 11 System.out.println("get:" + map.get("周杰伦")); 12 System.out.println("get:" + map.get("周杰")); // 返回null 13 System.out.println("----------------------"); 14 15 // Set<K> keySet():获取集合中所有键的集合 16 Set<String> set = map.keySet(); 17 for (String key : set) { 18 System.out.println(key); 19 } 20 System.out.println("----------------------"); 21 22 // Collection<V> values():获取集合中所有值的集合 23 Collection<String> con = map.values(); 24 for (String value : con) { 25 System.out.println(value); 26 }
* Map集合的遍历(方法一)。
* A:获取所有的键
* B:遍历键的集合,获取得到每一个键
* C:根据键去找值
1 // 创建集合对象 2 Map<String, String> map = new HashMap<String, String>(); 3 4 // 创建元素并添加到集合 5 map.put("杨过", "小龙女"); 6 map.put("郭靖", "黄蓉"); 7 map.put("杨康", "穆念慈"); 8 map.put("陈玄风", "梅超风"); 9 10 // 遍历 11 // 获取所有的键 12 Set<String> set = map.keySet(); 13 // 遍历键的集合,获取得到每一个键 14 for (String key : set) { 15 // 根据键去找值 16 String value = map.get(key); 17 System.out.println(key + "---" + value); 18 }
* Map集合的遍历(方法二)。
* A:获取所有键值对对象的集合
* B:遍历键值对对象的集合,得到每一个键值对对象
* C:根据键值对对象获取键和值
* 这里面最麻烦的就是键值对对象如何表示呢?
* 看看我们开始的一个方法:
* Set<Map.Entry<K,V>> entrySet():返回的是键值对对象的集合
1 // 创建集合对象 2 Map<String, String> map = new HashMap<String, String>(); 3 4 // 创建元素并添加到集合 5 map.put("杨过", "小龙女"); 6 map.put("郭靖", "黄蓉"); 7 map.put("杨康", "穆念慈"); 8 map.put("陈玄风", "梅超风"); 9 10 // 获取所有键值对对象的集合 11 Set<Map.Entry<String, String>> set = map.entrySet(); 12 // 遍历键值对对象的集合,得到每一个键值对对象 13 for (Map.Entry<String, String> me : set) { 14 // 根据键值对对象获取键和值 15 String key = me.getKey(); 16 String value = me.getValue(); 17 System.out.println(key + "---" + value); 18 }
Map集合遍历的两种方式图解:

* HashMap:是基于哈希表的Map接口实现。
* 哈希表的作用是用来保证键的唯一性的。
// 下面的写法是八进制,但是不能出现8以上的单个数据
// hm.put(003, "hello");
// hm.put(006, "hello");
// hm.put(007, "hello");
// hm.put(008, "hello");
//直接打印HashMap的对象名,仅仅是集合的元素的字符串表示。
* HashMap<Student,String>
* 键:Student
* 要求:如果两个对象的成员变量值都相同,则为同一个对象。
* 值:String
只需重写Student类的hashCode()和equals()方法。能够自动生成。
* LinkedHashMap:是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。
* 由哈希表保证键的唯一性
* 由链表保证键盘的有序(存储和取出的顺序一致)
* TreeMap:是基于红黑树的Map接口的实现。
举例:
1 // 创建集合对象 2 TreeMap<Student, String> tm = new TreeMap<Student, String>( 3 new Comparator<Student>() { 4 @Override 5 public int compare(Student s1, Student s2) { 6 // 主要条件 7 int num = s1.getAge() - s2.getAge(); 8 // 次要条件 9 int num2 = num == 0 ? s1.getName().compareTo( 10 s2.getName()) : num; 11 return num2; 12 } 13 });
Comparable和Comparator区别比较
Comparable是排序接口,若一个类实现了Comparable接口,就意味着“该类支持排序”。而Comparator是比较器,我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
两种方法各有优劣, 用Comparable 简单, 只要实现Comparable 接口的对象直接就成为一个可以比较的对象,但是需要修改源代码。 用Comparator 的好处是不需要修改源代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象,那样就可以节省很多重复劳动了。
* 需求 :"aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5)b(4)c(3)d(2)e(1)
*
* 分析:
* A:定义一个字符串(可以改进为键盘录入)
* B:定义一个TreeMap集合
* 键:Character
* 值:Integer
* C:把字符串转换为字符数组
* D:遍历字符数组,得到每一个字符
* E:拿刚才得到的字符作为键到集合中去找值,看返回值
* 是null:说明该键不存在,就把该字符作为键,1作为值存储
* 不是null:说明该键存在,就把值加1,然后重写存储该键和值
* F:定义字符串缓冲区变量
* G:遍历集合,得到键和值,进行按照要求拼接
* H:把字符串缓冲区转换为字符串输出
*
* 录入:linqingxia
* 结果:result:a(1)g(1)i(3)l(1)n(2)q(1)x(1)
1 // 定义一个字符串(可以改进为键盘录入) 2 Scanner sc = new Scanner(System.in); 3 System.out.println("请输入一个字符串:"); 4 String line = sc.nextLine(); 5 6 // 定义一个TreeMap集合 7 TreeMap<Character, Integer> tm = new TreeMap<Character, Integer>(); 8 9 //把字符串转换为字符数组 10 char[] chs = line.toCharArray(); 11 12 //遍历字符数组,得到每一个字符 13 for(char ch : chs){ 14 //拿刚才得到的字符作为键到集合中去找值,看返回值 15 Integer i = tm.get(ch); 16 17 //是null:说明该键不存在,就把该字符作为键,1作为值存储 18 if(i == null){ 19 tm.put(ch, 1); 20 }else { 21 //不是null:说明该键存在,就把值加1,然后重写存储该键和值 22 i++; 23 tm.put(ch,i); 24 } 25 } 26 27 //定义字符串缓冲区变量 28 StringBuilder sb= new StringBuilder(); 29 30 //遍历集合,得到键和值,进行按照要求拼接 31 Set<Character> set = tm.keySet(); 32 for(Character key : set){ 33 Integer value = tm.get(key); 34 sb.append(key).append("(").append(value).append(")"); 35 } 36 37 //把字符串缓冲区转换为字符串输出 38 String result = sb.toString(); 39 System.out.println("result:"+result);
* HashMap嵌套HashMap:
1 // 创建集合对象 2 HashMap<String, HashMap<String, Integer>> czbkMap = new HashMap<String, HashMap<String, Integer>>(); 3 4 // 创建基础班集合对象 5 HashMap<String, Integer> jcMap = new HashMap<String, Integer>(); 6 // 添加元素 7 jcMap.put("陈玉楼", 20); 8 jcMap.put("高跃", 22); 9 // 把基础班添加到大集合 10 czbkMap.put("jc", jcMap); 11 12 // 创建就业班集合对象 13 HashMap<String, Integer> jyMap = new HashMap<String, Integer>(); 14 // 添加元素 15 jyMap.put("李杰", 21); 16 jyMap.put("曹石磊", 23); 17 // 把基础班添加到大集合 18 czbkMap.put("jy", jyMap); 19 20 //遍历集合 21 Set<String> czbkMapSet = czbkMap.keySet(); 22 for(String czbkMapKey : czbkMapSet){ 23 System.out.println(czbkMapKey); 24 HashMap<String, Integer> czbkMapValue = czbkMap.get(czbkMapKey); 25 Set<String> czbkMapValueSet = czbkMapValue.keySet(); 26 for(String czbkMapValueKey : czbkMapValueSet){ 27 Integer czbkMapValueValue = czbkMapValue.get(czbkMapValueKey); 28 System.out.println("\t"+czbkMapValueKey+"---"+czbkMapValueValue); 29 } 30 }
ArrayList嵌套HashMap的遍历:
1 for (HashMap<String, String> hm : array) { 2 Set<String> set = hm.keySet(); 3 for (String key : set) { 4 String value = hm.get(key); 5 System.out.println(key + "---" + value); 6 } 7 }
HashMap嵌套HashMap嵌套ArrayList,三层嵌套举例:
1 // 创建大集合 2 HashMap<String, HashMap<String, ArrayList<Student>>> czbkMap = new HashMap<String, HashMap<String, ArrayList<Student>>>(); 3 4 // 北京校区数据 5 HashMap<String, ArrayList<Student>> bjCzbkMap = new HashMap<String, ArrayList<Student>>(); 6 ArrayList<Student> array1 = new ArrayList<Student>(); 7 Student s1 = new Student("林青霞", 27); 8 Student s2 = new Student("风清扬", 30); 9 array1.add(s1); 10 array1.add(s2); 11 ArrayList<Student> array2 = new ArrayList<Student>(); 12 Student s3 = new Student("赵雅芝", 28); 13 Student s4 = new Student("武鑫", 29); 14 array2.add(s3); 15 array2.add(s4); 16 bjCzbkMap.put("基础班", array1); 17 bjCzbkMap.put("就业班", array2); 18 czbkMap.put("北京校区", bjCzbkMap); 19 20 21 // 西安校区数据 22 HashMap<String, ArrayList<Student>> xaCzbkMap = new HashMap<String, ArrayList<Student>>(); 23 ArrayList<Student> array3 = new ArrayList<Student>(); 24 Student s5 = new Student("范冰冰", 27); 25 Student s6 = new Student("刘意", 30); 26 array3.add(s5); 27 array3.add(s6); 28 ArrayList<Student> array4 = new ArrayList<Student>(); 29 Student s7 = new Student("李冰冰", 28); 30 Student s8 = new Student("张志豪", 29); 31 array4.add(s7); 32 array4.add(s8); 33 xaCzbkMap.put("基础班", array3); 34 xaCzbkMap.put("就业班", array4); 35 czbkMap.put("西安校区", xaCzbkMap); 36 37 // 遍历集合 38 Set<String> czbkMapSet = czbkMap.keySet(); 39 for (String czbkMapKey : czbkMapSet) { 40 System.out.println(czbkMapKey); 41 HashMap<String, ArrayList<Student>> czbkMapValue = czbkMap 42 .get(czbkMapKey); 43 Set<String> czbkMapValueSet = czbkMapValue.keySet(); 44 for (String czbkMapValueKey : czbkMapValueSet) { 45 System.out.println("\t" + czbkMapValueKey); 46 ArrayList<Student> czbkMapValueValue = czbkMapValue 47 .get(czbkMapValueKey); 48 for (Student s : czbkMapValueValue) { 49 System.out.println("\t\t" + s.getName() + "---" 50 + s.getAge()); 51 } 52 } 53 }
* 1:Hashtable和HashMap的区别?
* Hashtable:线程安全,效率低。不允许null键和null值
* HashMap:线程不安全,效率高。允许null键和null值
*
* 2:List,Set,Map等接口是否都继承子Map接口?
* List,Set不是继承自Map接口,它们继承自Collection接口
* Map接口本身就是一个顶层接口
1 Hashtable<String, String> hm = new Hashtable<String, String>(); 2 3 hm.put("it001", "hello"); 4 // hm.put(null, "world"); //NullPointerException 5 // hm.put("java", null); // NullPointerException 6 7 System.out.println(hm);
* Collections:是针对集合进行操作的工具类,都是静态方法。
*
* 面试题:
* Collection和Collections的区别?
* Collection:是单列集合的顶层接口,有子接口List和Set。
* Collections:是针对集合操作的工具类,有对集合进行排序和二分查找的方法
*
* 要知道的方法
* public static <T> void sort(List<T> list):排序 默认情况下是自然顺序。
* public static <T> int binarySearch(List<?> list,T key):二分查找
* public static <T> T max(Collection<?> coll):最大值
* public static void reverse(List<?> list):反转
* public static void shuffle(List<?> list):随机置换
Collections可以针对ArrayList存储基本包装类的元素排序,也可以对存储自定义对象排序。
方法一: 在对象类中重写compareTo()方法,实现Comparable接口:
public class Student implements Comparable<Student> { @Override public int compareTo(Student s) { int num = this.age - s.age; int num2 = num == 0 ? this.name.compareTo(s.name) : num; return num2; }
方法二:在内部类中实现
1 // 排序 2 // 自然排序 3 // Collections.sort(list); 4 // 比较器排序 5 // 如果同时有自然排序和比较器排序,以比较器排序为主 6 Collections.sort(list, new Comparator<Student>() { 7 @Override 8 public int compare(Student s1, Student s2) { 9 int num = s2.getAge() - s1.getAge(); 10 int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) 11 : num; 12 return num2; 13 } 14 });
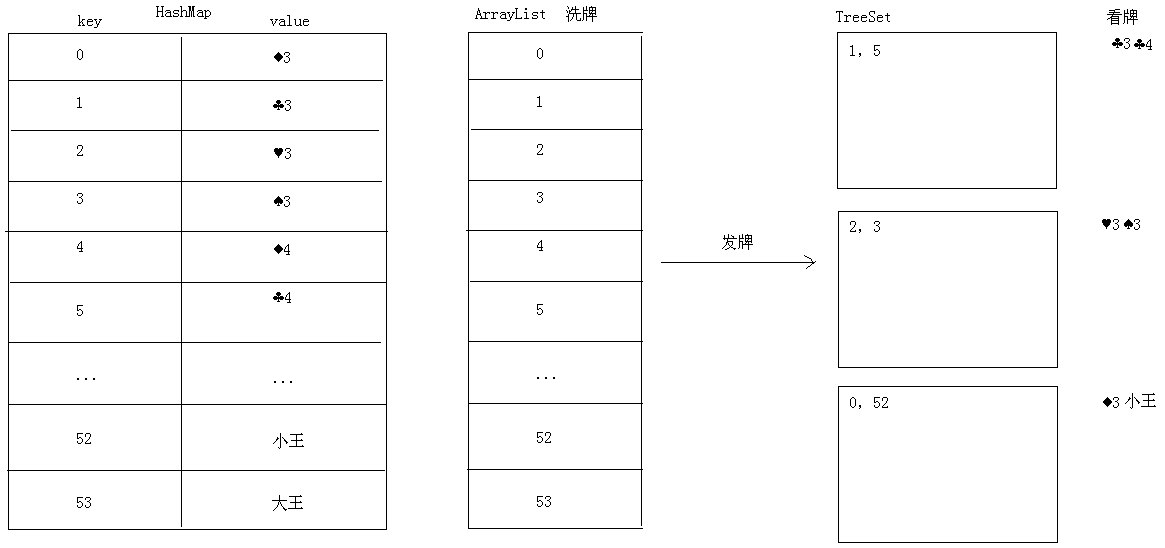
* 模拟斗地主洗牌和发牌
* 思路:
* A:创建一个HashMap集合
* B:创建一个ArrayList集合
* C:创建花色数组和点数数组
* D:从0开始往HashMap里面存储编号,并存储对应的牌
* 同时往ArrayList里面存储编号即可。
* E:洗牌(洗的是编号)
* F:发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收)
* G:看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
模拟斗地主洗牌和发牌并对牌进行排序的原理图解:
代码:
1 public class PokerDemo { 2 public static void main(String[] args) { 3 // 创建一个HashMap集合 4 HashMap<Integer, String> hm = new HashMap<Integer, String>(); 5 6 // 创建一个ArrayList集合 7 ArrayList<Integer> array = new ArrayList<Integer>(); 8 9 // 创建花色数组和点数数组 10 // 定义一个花色数组 11 String[] colors = { "♠", "♥", "♣", "♦" }; 12 // 定义一个点数数组 13 String[] numbers = { "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", 14 "K", "A", "2", }; 15 16 // 从0开始往HashMap里面存储编号,并存储对应的牌,同时往ArrayList里面存储编号即可。 17 int index = 0; 18 19 for (String number : numbers) { 20 for (String color : colors) { 21 String poker = color.concat(number); 22 hm.put(index, poker); 23 array.add(index); 24 index++; 25 } 26 } 27 hm.put(index, "小王"); 28 array.add(index); 29 index++; 30 hm.put(index, "大王"); 31 array.add(index); 32 33 // 洗牌(洗的是编号) 34 Collections.shuffle(array); 35 36 // 发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收) 37 TreeSet<Integer> fengQingYang = new TreeSet<Integer>(); 38 TreeSet<Integer> linQingXia = new TreeSet<Integer>(); 39 TreeSet<Integer> liuYi = new TreeSet<Integer>(); 40 TreeSet<Integer> diPai = new TreeSet<Integer>(); 41 42 for (int x = 0; x < array.size(); x++) { 43 if (x >= array.size() - 3) { 44 diPai.add(array.get(x)); 45 } else if (x % 3 == 0) { 46 fengQingYang.add(array.get(x)); 47 } else if (x % 3 == 1) { 48 linQingXia.add(array.get(x)); 49 } else if (x % 3 == 2) { 50 liuYi.add(array.get(x)); 51 } 52 } 53 54 // 看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌) 55 lookPoker("风清扬", fengQingYang, hm); 56 lookPoker("林青霞", linQingXia, hm); 57 lookPoker("刘意", liuYi, hm); 58 lookPoker("底牌", diPai, hm); 59 } 60 61 // 写看牌的功能 62 public static void lookPoker(String name, TreeSet<Integer> ts, 63 HashMap<Integer, String> hm) { 64 System.out.print(name + "的牌是:"); 65 for (Integer key : ts) { 66 String value = hm.get(key); 67 System.out.print(value + " "); 68 } 69 System.out.println(); 70 } 71 }
集合总结:
Collection(单列集合)
List(有序,可重复)
ArrayList
底层数据结构是数组,查询快,增删慢。线程不安全,效率高。
Vector
底层数据结构是数组,查询快,增删慢。线程安全,效率低。
LinkedList
底层数据结构是链表,查询慢,增删快。线程不安全,效率高。
Set(无序,唯一)
HashSet
底层数据结构是哈希表,哈希表以来两个方法: hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是ture:说明元素重复,不添加;如果是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashSet
底层数据结构由链表和哈希表组成,由链表保证元素有序,哈希表保证元素唯一。
TreeSet
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素的唯一性呢?
根据元素的返回值是否是0来决定
如何保证元素的排序呢?
两种方式:
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接受一个Comparator的实现类对象
Map(双列集合)
A:Map集合的数据结构仅仅针对键有效,与值无关。
B:存储的是键值对形式的元素,键唯一,值可重复。
HashMap
底层数据结构是哈希表。线程不安全,效率高。哈希表依赖两个方法: hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是ture:说明元素重复,不添加;如果是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashMap
底层数据结构由链表和哈希表组成,由链表保证元素有序,哈希表保证元素唯一。
Hashtable
底层数据结构是哈希表,线程安全,效率低。哈希表依赖两个方法: hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是ture:说明元素重复,不添加;如果是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
TreeMap
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素的唯一性呢?
根据元素的返回值是否是0来决定
如何保证元素的排序呢?
两种方式:
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接受一个Comparator的实现类对象
2:到底使用那种集合
看需求。
是否是键值对形式:
是:Map
键是否需要排序:
是:TreeMap
否:HashMap
不知道,就是用HashMap
否:Collection
元素是否唯一:
是:Set
元素是否需要排序:
是:TreeSet
否:HashSet
不知道就使用HashSet
否:List
要安全吗:
是:Vector(其实我们也不用,后面我们讲解了多线程以后,我在给你回顾用谁)
否:ArrayList或者LinkedList
增删多:LinkedList
查询多:ArrayList
不知道就使用ArrayList
不知道就使用ArrayList
3:集合的常见方法及遍历方式
Collection:
add()
remove()
contains()
iterator()
size()
|--List
get()
遍历:
增强for
迭代器
普通for
|--Set
遍历:
增强for
迭代器
Map:
put()
remove()
containskey(), containsValue()
keySet()
get()
value()
entrySet()
size()
遍历:
根据键找值
根据键值对对象分别找键和值