Python爬虫-Selenium(1)
@(博客)[python, 爬虫, selenium, Python]
前言
如果一定要说什么东西会记忆犹新、历久弥新的话,恐怕于我来说,是绕不过“2a分之-b正负根号下b平方-4ac”了。这个万能公式,尽管在一定条件下会让计算变得复杂,但学生们也包括过去的我在内,大都对此心爱不已——毕竟少了许多动脑筋的麻烦事儿。
而在爬虫界,也有这么一个可以让人少动脑筋的万能公式,我们不必考虑需要设置哪些cookies,也不用考虑提交动态的uuid,token等等。它不是不存在缺点,效率会有些低,这向来被人诟病。可偏有人爱装×,你说他爬取个业余用来娱乐的数据,总共恐怕千条不足百条有余,几秒的时间差对他来说真的重要吗?
方法无罪,因地制宜。
它就是selenium+chrome。
前期准备
selenium是一个自动化的库,其实可以连接很多浏览器,包括谷歌,火狐,苹果以及PhantomJS,但我这里只以chrome为例。而且,现在用PhantomJS要被Python警告,主要是官方不支持了
安装库:pip install selenium
谷歌驱动:chromedriver 2.41 (对应浏览器版本v67-69,需要科学上网才能下载,也可以去我的CSDN下载,提供win,linux,mac三个版本)
下载之后,建议将驱动放到python目录下的Scripts下面(仅针对win用户),这样一来就不用指明驱动的路径即可使用
基础使用
from selenium import webdriver
# 实例化一个浏览器
browser = webdriver.Chrome()
# 访问百度
browser.get("https://www.baidu.com")
# 退出浏览器
browser.quit()一切顺利,就能看到浏览器自动打开,并且跳转到百度网页,之后又自动退出,效果如下:
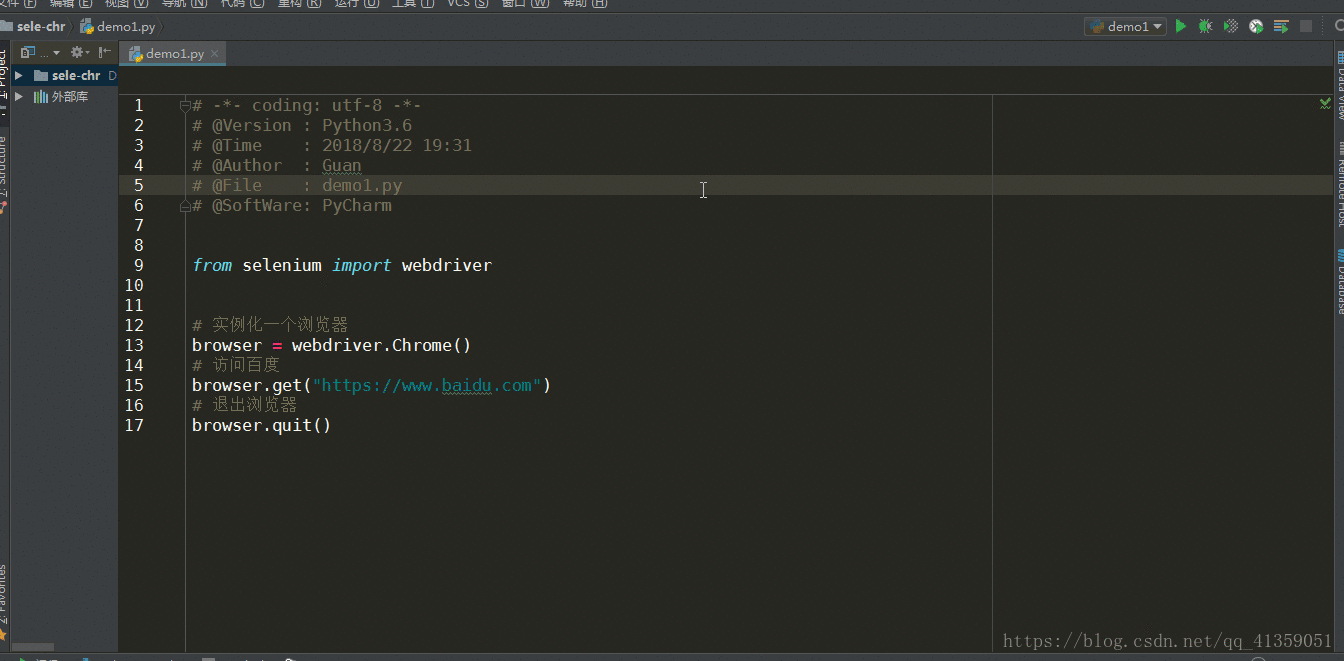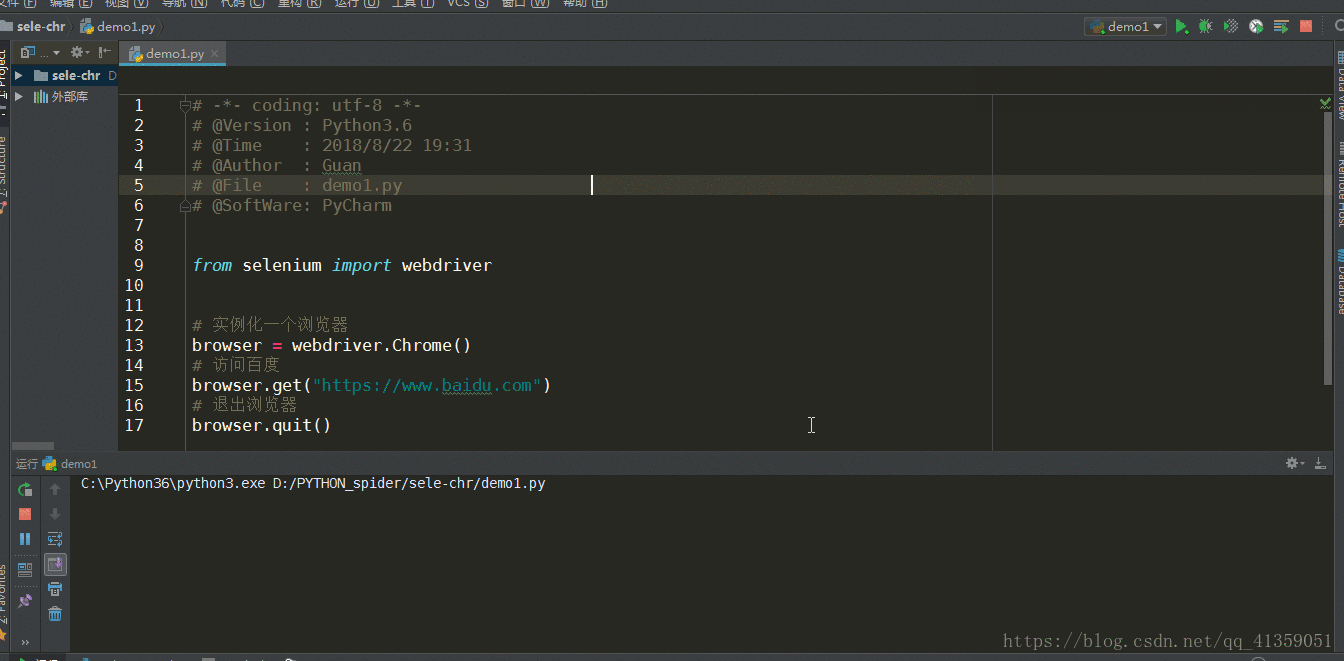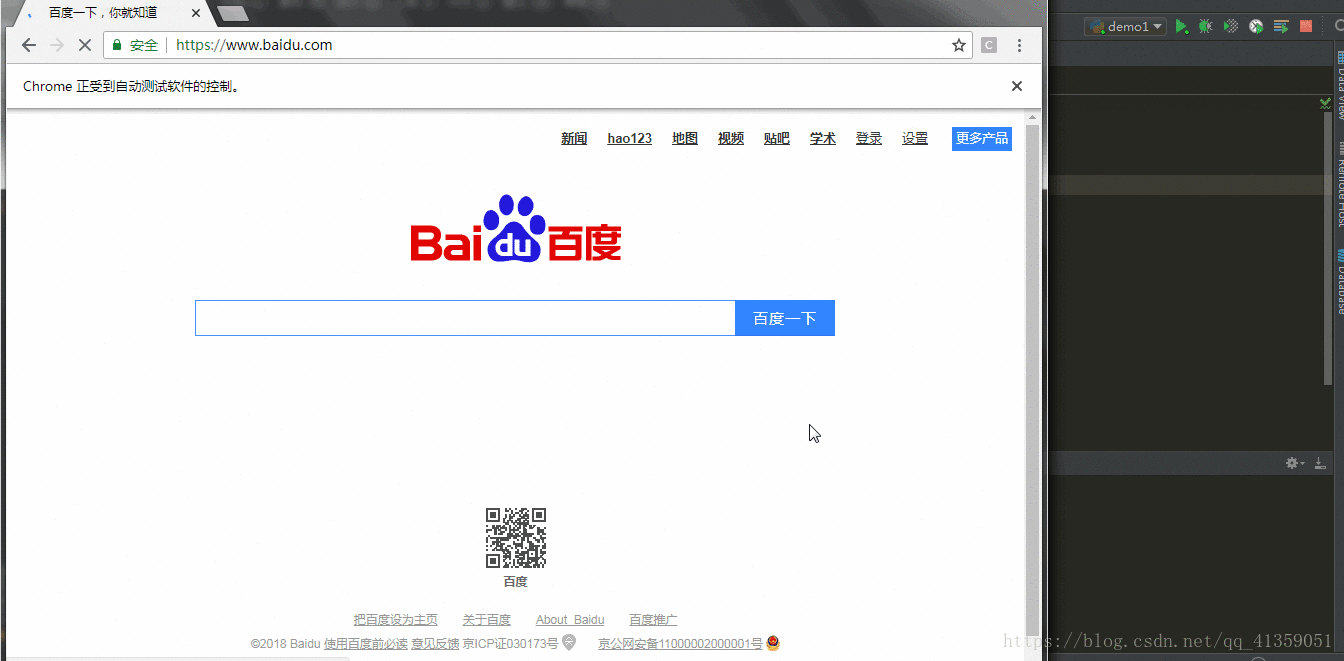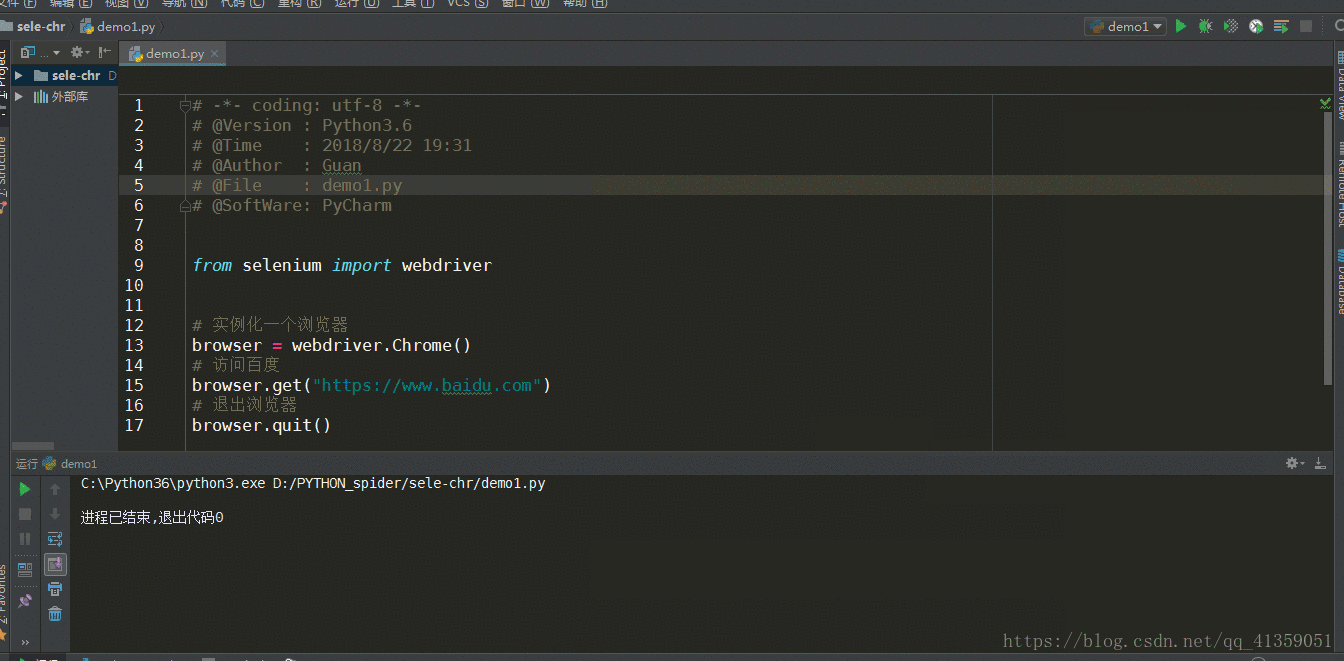
那么,要是我们想通过自动化程序来搜索可不可以呢?答案是当然的。这里就需要找到节点,selenium提供以下多种选择节点的方法:
find_element_by_id通过id定位find_element_by_name通过name定位find_element_by_link_text通过a标签中的文本定位find_element_by_partial通过a标签中的部分文本定位(类似于模糊查询)find_element_by_tag_name通过标签名定位find_element_by_class_name通过类名定位find_element_by_xpath通过xpath规则find_element_by_css_selector通过css选择器
这里我们完全可以用老相识,也就是最后两个方法来寻找节点(我也建议用常用最后两个方法)
首先通过开发者工具审查元素,找到搜索框
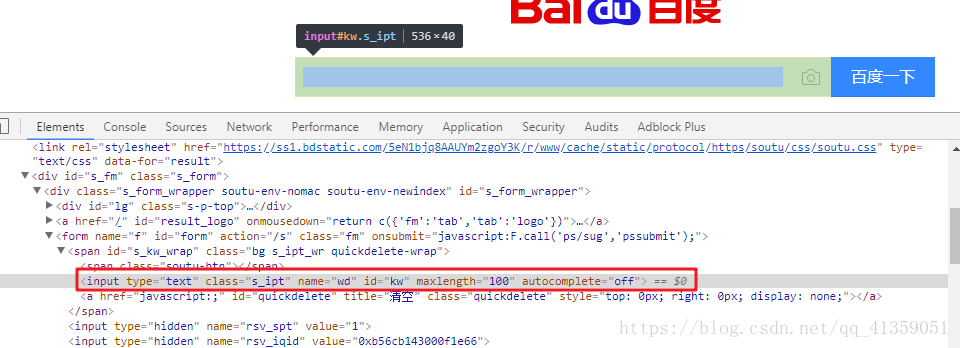
既然是要查询,自然也得找到百度一下这个按钮的节点,以便我们click一下
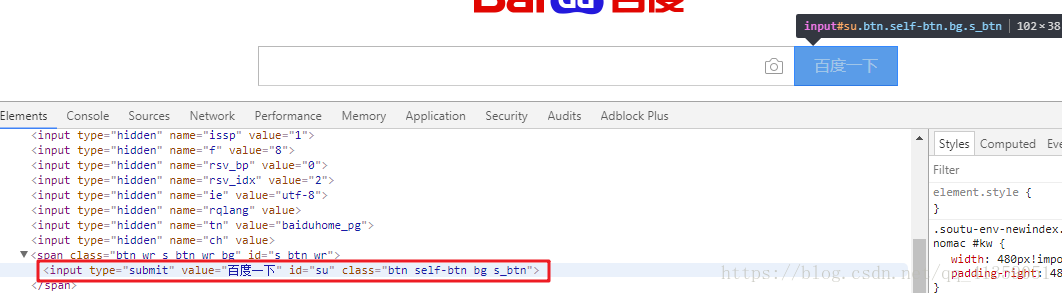
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
# 找到搜索框,并输入内容
browser.find_element_by_css_selector("#kw").send_keys("有关心情 CSDN")
# 找到按钮,并且点击一下
browser.find_element_by_css_selector("#su").click()效果如下:
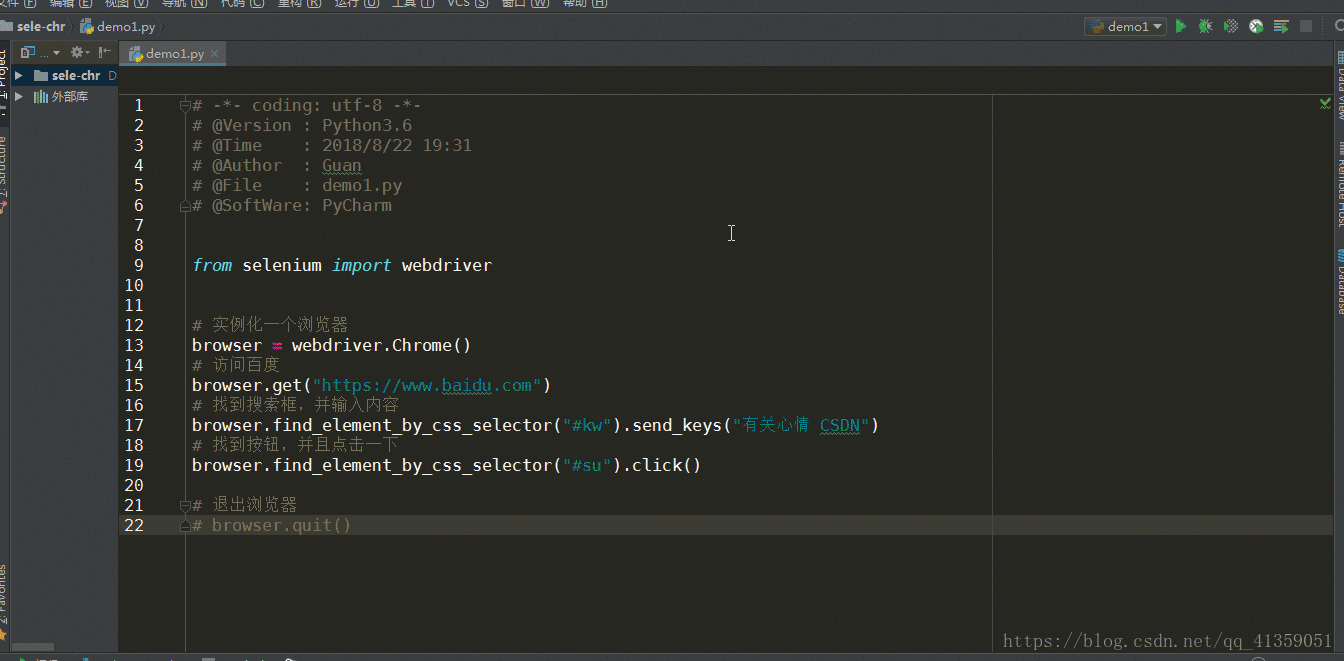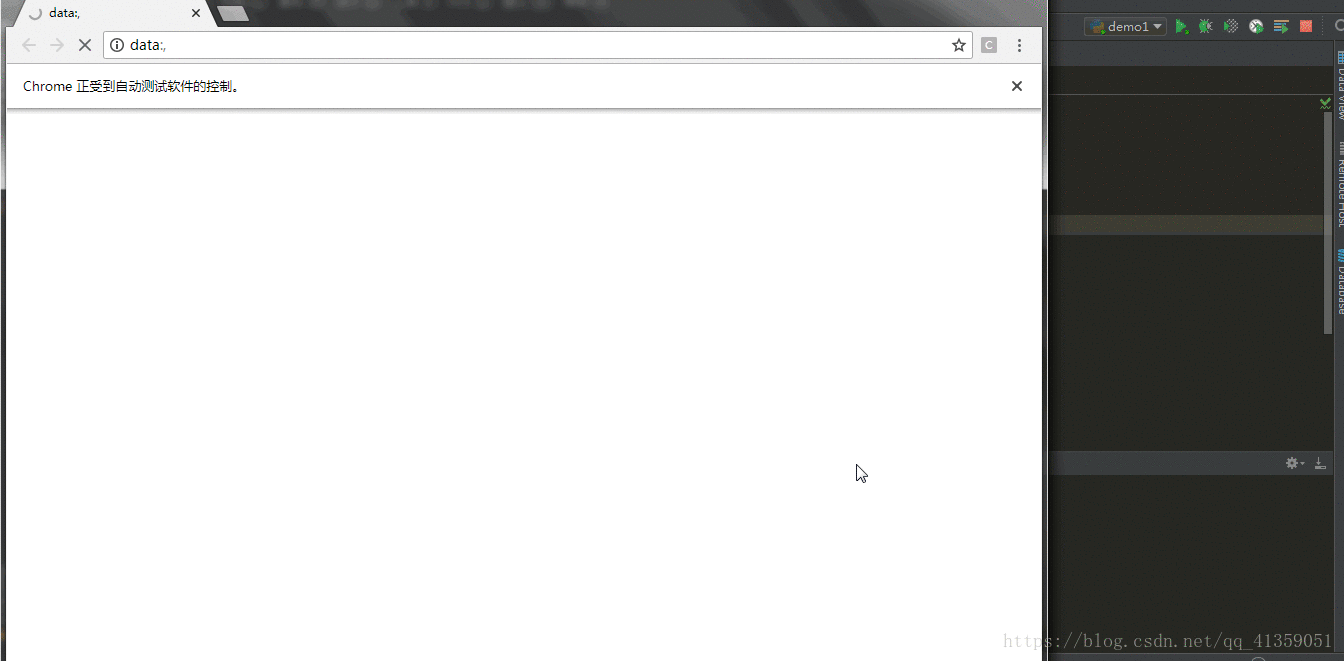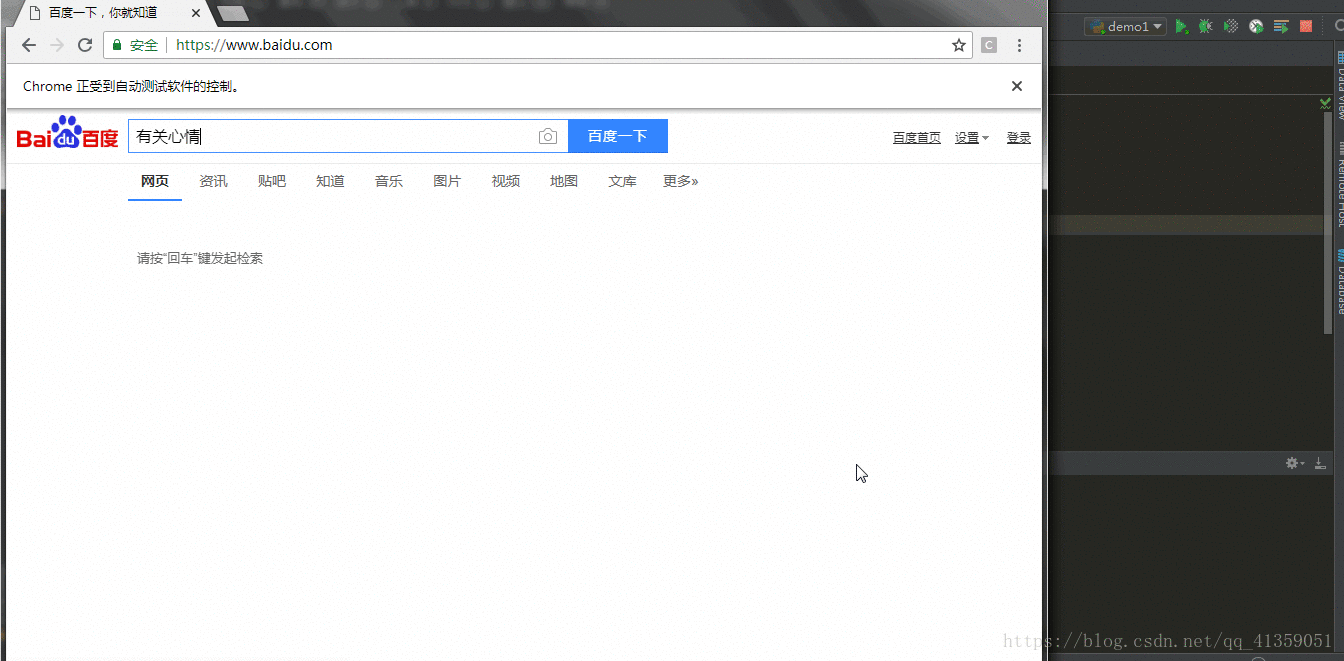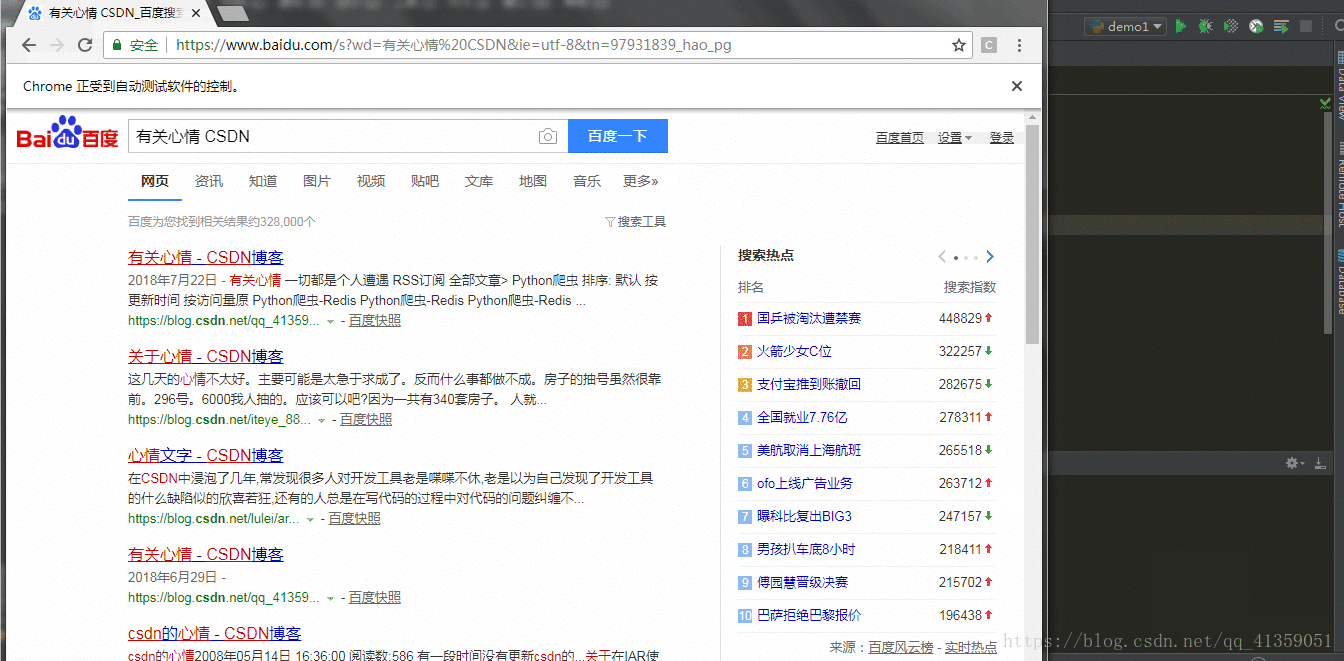
也就是说,selenium提供了send_keys()方法用于输入,click()方法用于点击
进阶使用
浏览器操作
selenium十分强大,提供了许多方法,以至于可以完全模拟人的行为;由于简单,就不一一演示,直接罗列了:
browser.back()前进browser.forward()后退browser.save_screenshot("1.png")保存截图browser.title获取网页标题browser.current_url获取当前url地址browser.close()关闭当前网页(当只有一个页面的时候,会关掉浏览器);而quit()方法是直接关掉浏览器
节点操作
我们也可以通过selenium直接提取数据
前面我们查找节点的时候,都是用的find_element_by...,通过这种方式,只会返回一个节点,如果需要的是多个节点,则得加上一个s,即:find_elements_by...,以list类型返回
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.cnblogs.com/youguanxinqing/")
# 寻找class=postTitle的节点
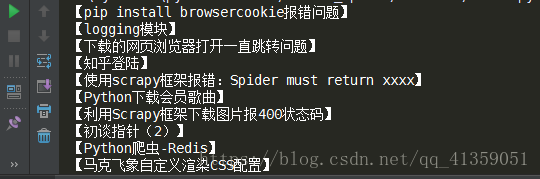
nodes = browser.find_elements_by_css_selector(".postTitle")
# 取出每个节点
for node in nodes:
# 通过取出来的节点找寻它包含的标签为a的节点,并取出文本
title = node.find_element_by_tag_name("a").text
print("【{0}】".format(title))
browser.quit()运行结果如下:
当然,我们也可以取出源码,再用我们熟悉的XPath或者美丽汤,或者pyquery来解析数据,方法为browser.page_source
selenium的一大特色是,取出来的源码是经过js脚本渲染之后的代码,这一来使得我们获取数据更加容易
其他方法:
节点.id获取标签id值节点.location获取标签位置节点.tag_name获取标签名节点.size获取标签大小;以字典方式返回如:{‘height’: 45, ‘width’: 61}节点.get_attribute()获取标签的属性值;如需要class值:节点.get_attribute("class")
等待
很可能网速,或者我们电脑太卡的缘故,使得渲染速度太慢,就可能发生某个标签还未通过js脚本渲染,而我们的爬虫程序已经执行到寻找这个标签的语句了,这个时候程序就报错,告诉我们没有这样的标签。selenium也帮我们想到了这个问题
(1)隐式等待:当selenium第一次寻找某个节点没有找到时,它将继续等待,直到设置的时间到了再去找,如果还没找到,报错。代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
browser.implicitly_wait(10) # 参数单位:秒
...==这是一个针对全局的设置,在每一次寻找节点失败的时候,都会固定不变的等待一段时间,直到程序结束(正常结束或者异常结束)==
(2)显式等待:显式比隐式等待灵活许多。它的工作机制是,在最长等待时间之内,定期去看看节点出现没,出现了,程序继续往下走;没出现,就再等一会;直到设置的最长时间到了,程序报错TimeoutException
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get("https://www.taobao.com/")
wait = WebDriverWait(browser, 10) # 实例一个等待对象,最长等待10秒
try:
# 等待id为q的标签出现
inputTag = wait.until(EC.presence_of_element_located((By.ID, "q")))
# 等待能够点击的标签出现(By.CSS_SELECTOR表示使用css选择器)
btnTag = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
# 没等到之后的操作
except:
...
# 等到之后的操作
else:
...异常
当我们需要捕获异常的时候,需要导入对应的异常,如:
from selenium.common.exceptions import TimeoutException, NoSuchElementException
cookies
我们也可以获取、添加、删除浏览器中的Cookies
- browser.get_cookies() 以list类型返回
- browser.add_cookies({...})
- browser.delete_all_cookies()
其他设置
禁止提示
有时候浏览器有如下这样的提示出现,我们可以设置禁止
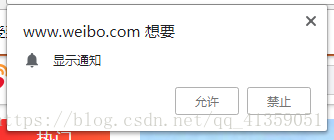
chrome_options = webdriver.ChromeOptions()
prefs = {
"profile.default_content_setting_values": {'notifications': 2} # 禁止浏览器提示
}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
...禁止加载图片
有时候我们为了让爬虫效率,也可以禁止浏览器加载图片以达增快渲染速度
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_setting.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
...无头设置
我们每一次运行,浏览器都会弹出来,事实上除了调试,没有谁会愿意它跑出来“丢人现眼”,所以我们可以设置无头运行(也就是无界面运行)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
browser = webdriver.Chrome(chrome_options=chrome_options)实战新浪微博
需要说明的是,经过渲染之后的网页数据,会夹杂许多杂志,增加清洗数据的难度。这里之所以用selenium+chrome的方法来爬取新浪微博,只为练习。事实上,如果数据并不庞大,调用新浪提供的免费接口,或者访问APP的数据源,都是更好的选择。这里不做延伸
要求
这里我选择爬取的是我喜欢的一个作家,落落的微博,需要提取的数据如下所示:
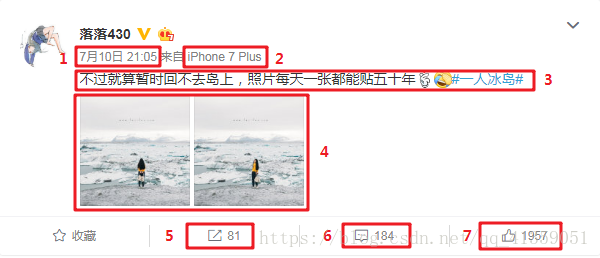
要求1:发布时间,发布设别,微博正文,图片链接,转发数,评论数,点赞数
要求2:将这些数据存入mongodb中
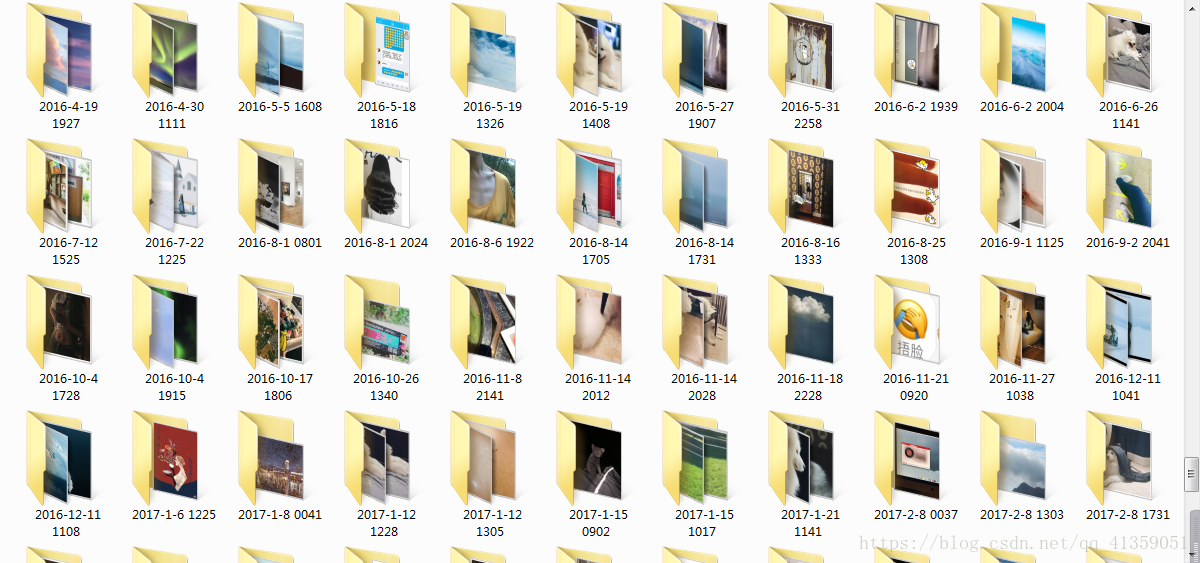
要求3:下载获取到的图片链接(我这里选择的是封面图片,而不是高清大图)
注意
整个过程中需要注意的地方:
注意1:微博每页的数据并非直接全部呈现,当内容比较多时,需要下拉滑动条进行数据的加载
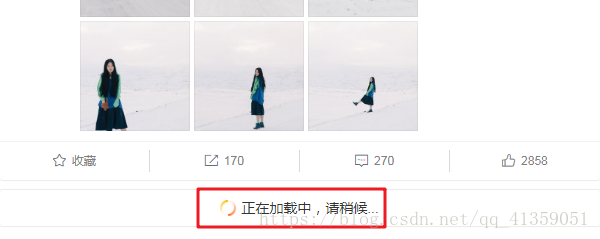
控制浏览器下拉代码:
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")(实际是执行了js语句)
注意2:尽管显示微博页数只有32,但当你访问page=100的时候,依然可以得到渲染后的页面,只是这个页面没有数据
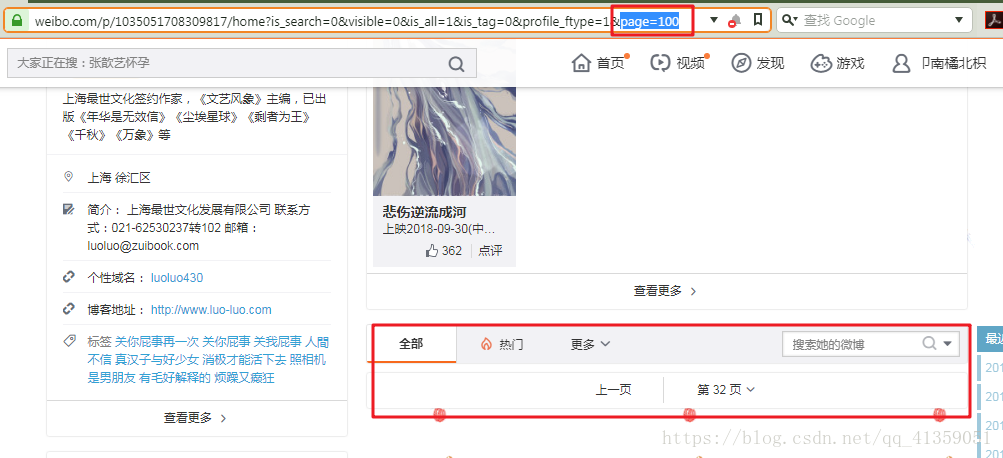
我做了最笨也是最简单的处理,以页数作为循环次数
for page in range(1, PAGE+1):
...注意3:当转发或者评论或者点赞为0的时候,微博直接显示文字

我是通过正则来清洗的数据,因为这样看起来会有些高大上(逃。。。)
tmp = filter(lambda y: y, [re.search(r"\d+|[\u4e00-\u9fa5]+", x) for x in data["TCPCol"]])
tmp = [i.group() for i in list(tmp)]
tmp.pop(0)
data["transNum"], data["comNum"], data["praNum"] = [int(i) if re.match(r"\d+", i) else 0 for i in tmp]效果
程序运行效果如下:
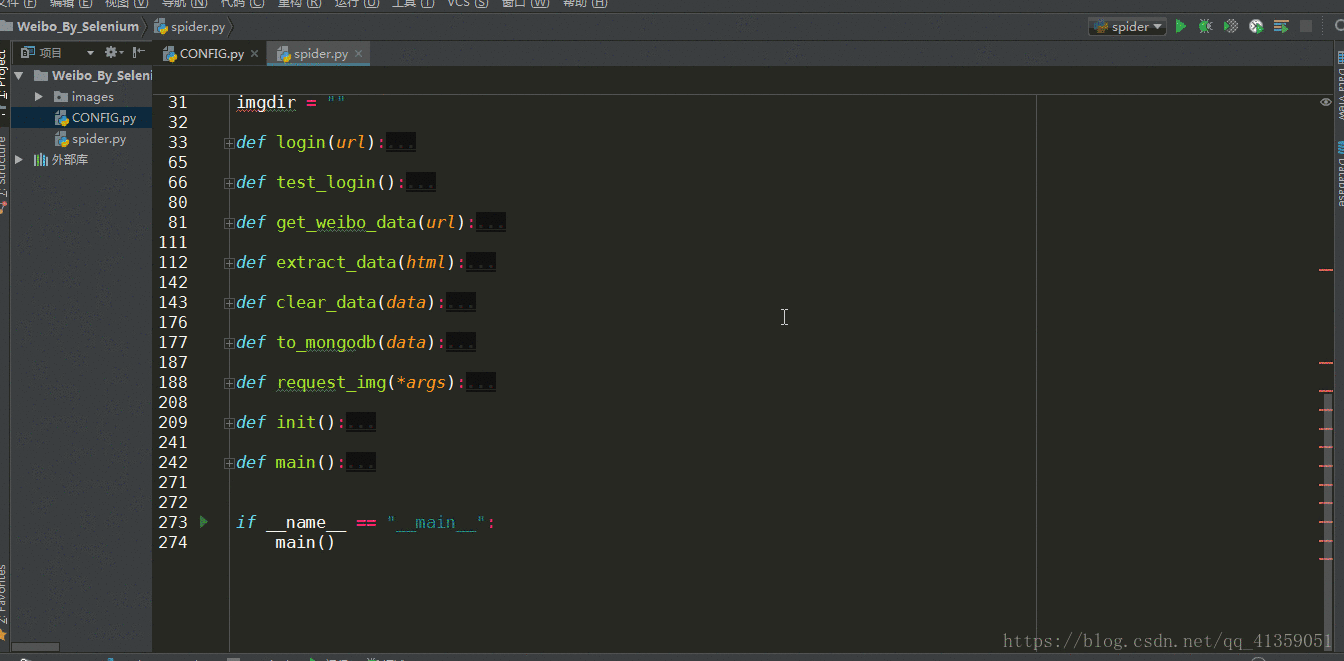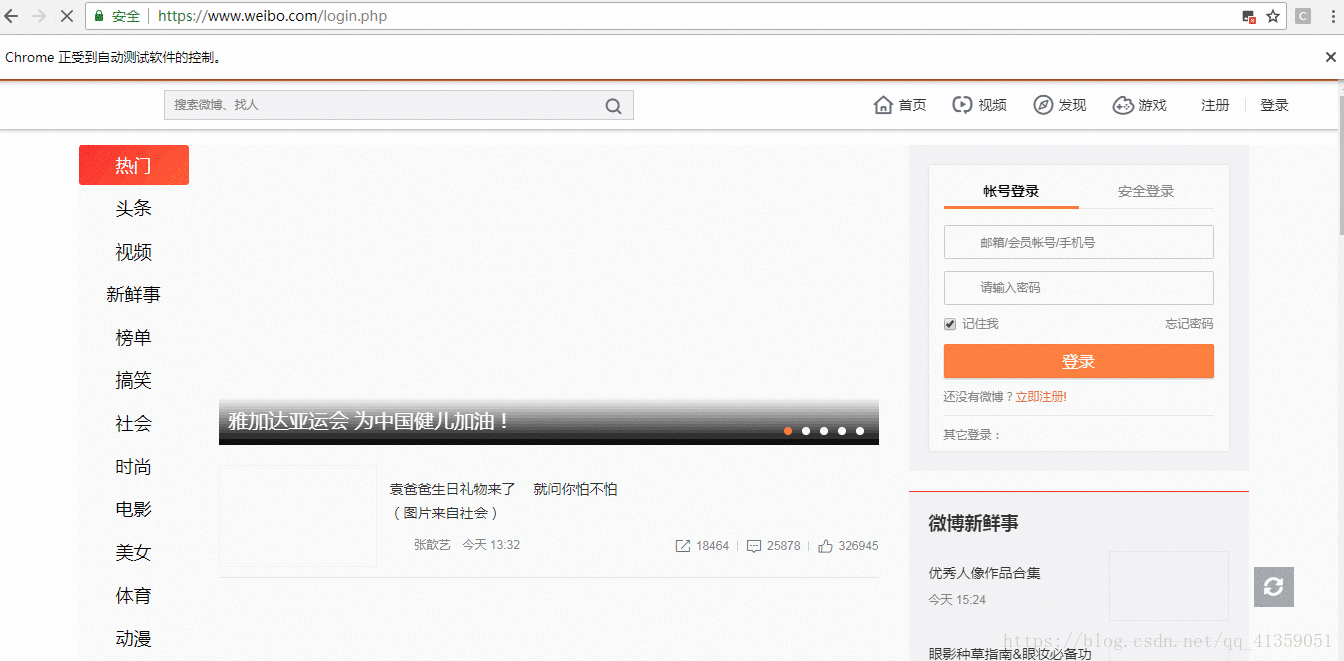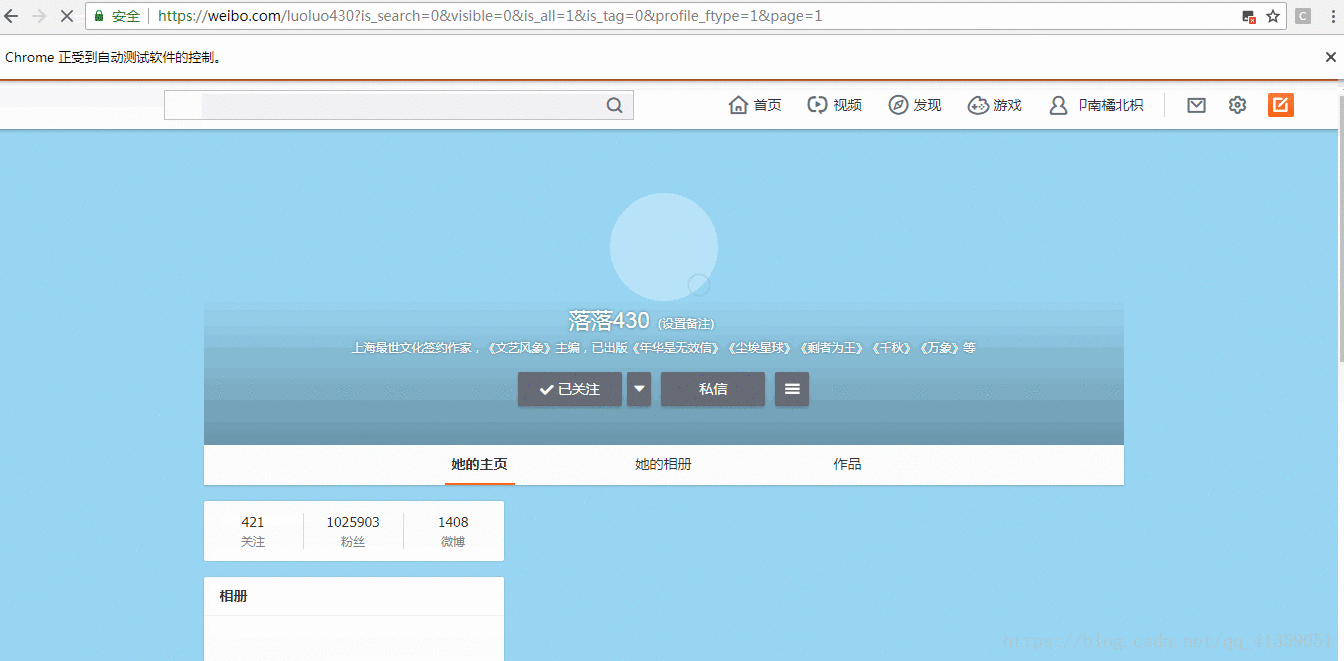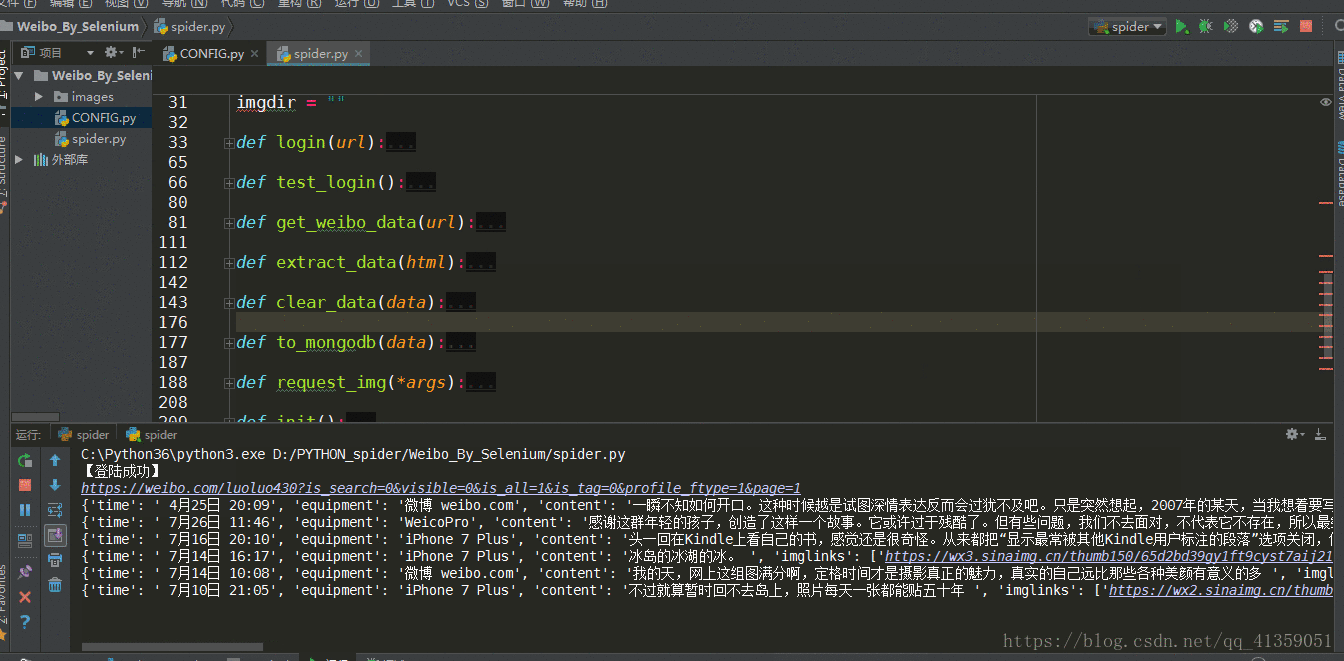
插入mongodb数据格式如下:
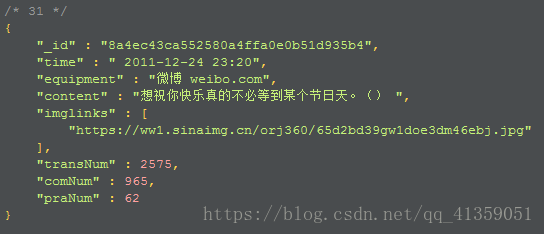
本地保存图片如下:
问题
其中我遇到一个问题,程序已经能够正常运行,然而添加无头设置之后会报错,编译器提示元素不可见。暂时我还没能解决这个问题,之后我会好好研究,或者,要不你们告诉告诉我嘛【装可爱脸.jpg】
完整代码已上传GitHub,点击可查看