该系列文章系个人读书笔记及总结性内容,任何组织和个人不得转载进行商业活动!
约束、视图与事务:人多手杂,数据库受不了
数据库到一定规模后,其他人也需要使用数据库:
我们要防止其他人输入错误的数据;
限制只看到部分数据的技术;
防止大家同时输入数据时相互踩到别人的地盘;
本章,我们开始保护数据:“数据库自卫术Part 1”;
本章使用的数据库依然是mark_list:
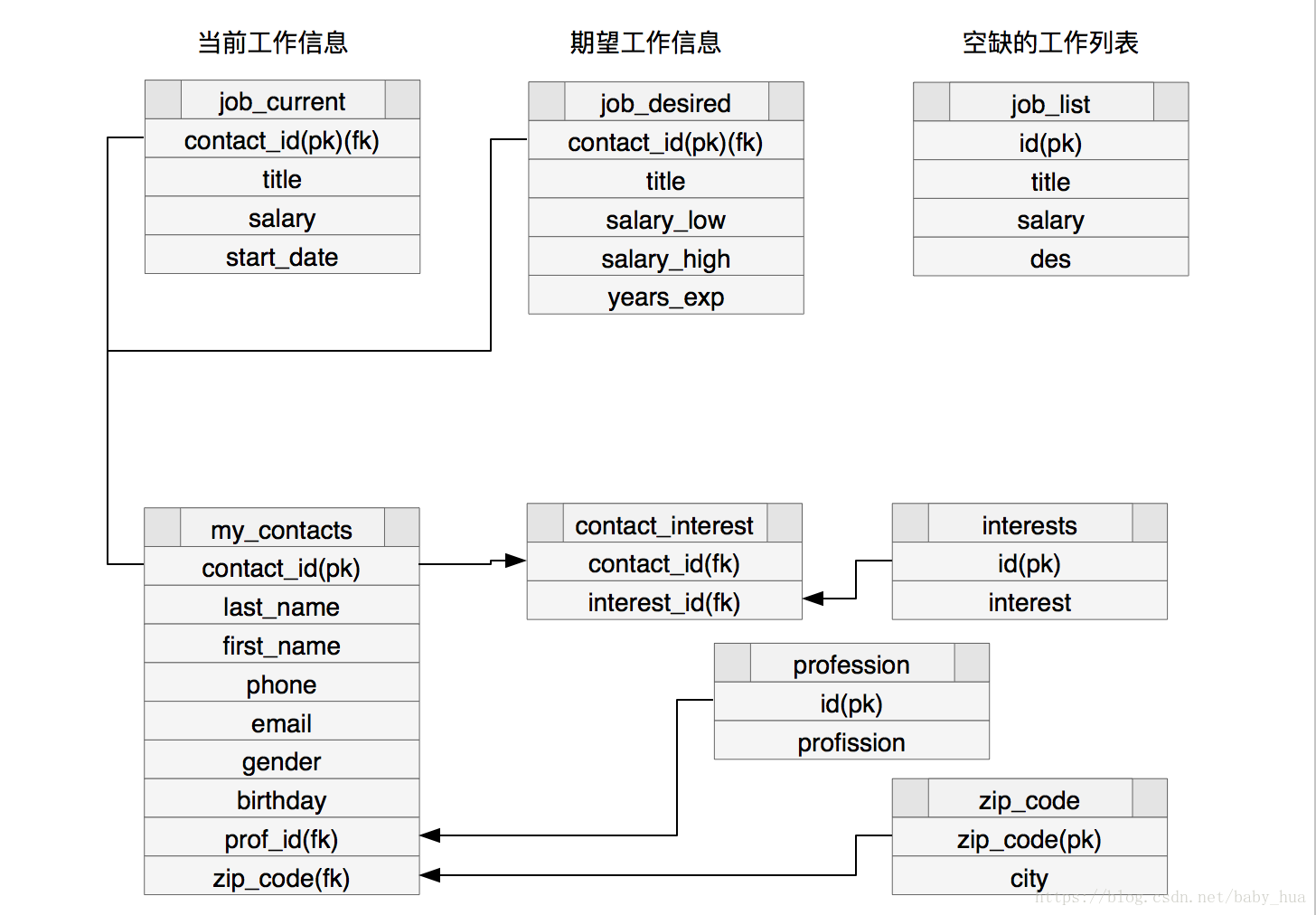
各表中数据如下:
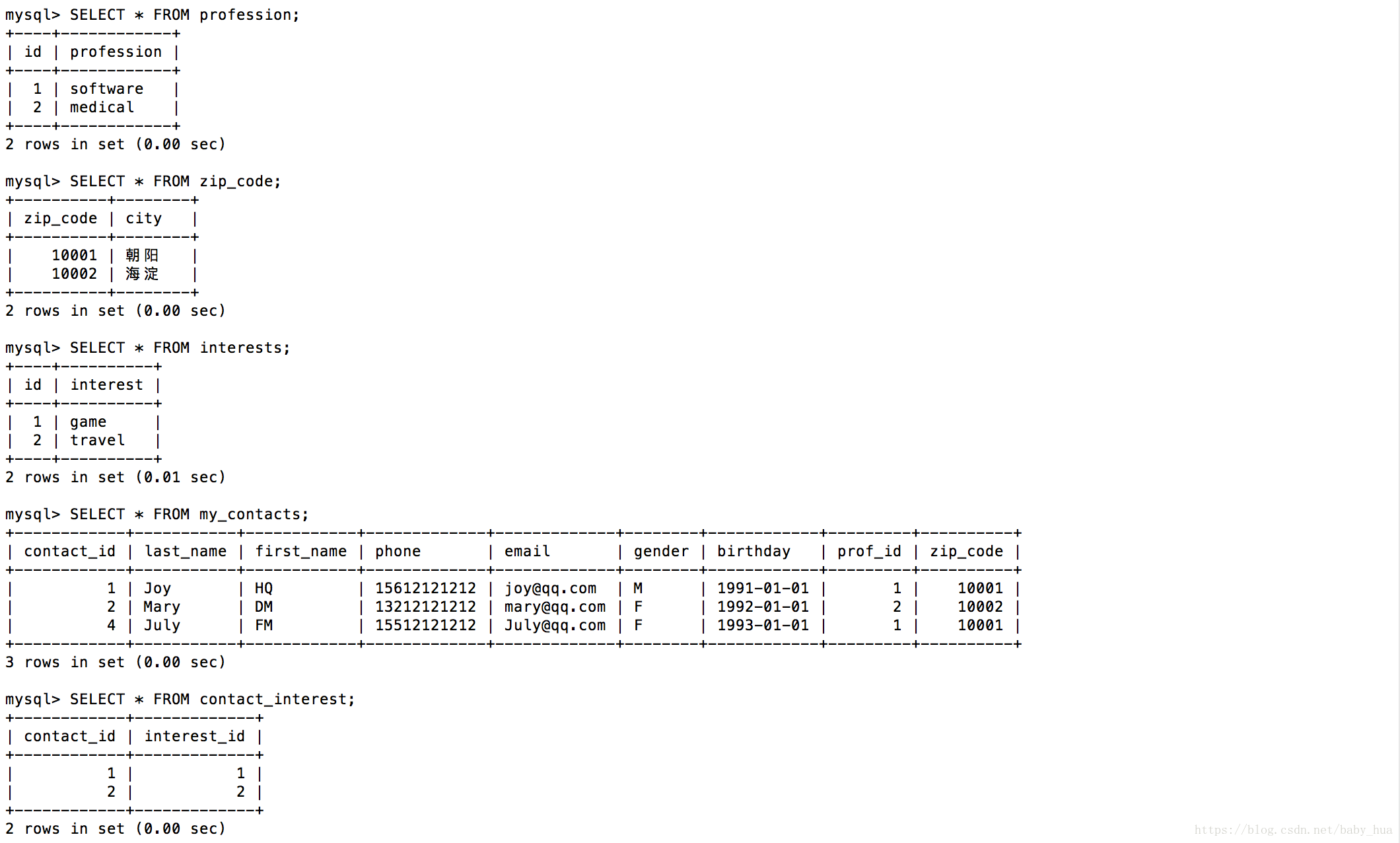

熟悉下准备好的数据,我们继续;
现在作为表的管理者,随着数据量的增加,一个人管理起来比较吃力,而且我还有其他的事情……
我们找了管理数据库,拓展业务需求的帮手;
简单来说,操作数据库的人多了;
插入新的数据:
Maik MQ 14812121212 [email protected] ? 1994-01-01 teacher 海淀
我们看到,除了性别未知以外,其他数据都有,由于有了新的职业’教师’,相应的profession表也需要新增一条数据;
新的数据库使用者user1,在插入数据的时候,尽量保证不出现NULL,于是他在性别的部分使用另一个字符X表示未知;
这里回顾两个知识点:
1.有AUTO_INCREMENT的列不需要放入值,表也会为我们插入主键列的值:
mysql> INSERT INTO profession
-> VALUES
-> (NULL,'student');2.插入数据时,也可以使用子查询:
mysql> INSERT INTO my_contacts
-> (last_name,first_name,phone,email,gender,birthday,prof_id,zip_code)
-> VALUES
-> ('Mail','MQ','14912121212','[email protected]','X','1994-01-01',(
-> SELECT id FROM profession
-> WHERE profession = 'student'),'10002');现在我们的联系人表如下:

伴随着新值的插入,我们需要统计我们联系人中的男、女以及总人数:
查询男、女的话加入WHERE条件即可;
mysql> SELECT COUNT(*)
-> FROM my_contacts;不想要的’X’:
统计人数对不上,都是因为我们使用了这个字符;
我们该如何限制不让user1输入此类字符呢?
检查约束:加入CHECK
约束:constraint 限定了可插入列的内容;他需要在我们创建表/更新表的时候加入约束;
我们之前见到的NOT NULL、PRIMARY KEY、FOREIGN KEY都是约束;
还有一种列约束称为CHECK-检查约束;
CHECK gender:
为my_contacts表的gender设置检查约束;
约束限制输入的字符只能是M或F;
mysql> ALTER TABLE my_contacts
-> ADD CONSTRAINT check_my_contacts CHECK (gender IN ('M','F'));如果是在CREATE TABLE时加入约束的话,语法:
可以是在正常的列之后加上CHECK(something);
或者单独一行CONSTRAINT check_my_contacts CHECK(something)
删除检查约束:DROP CHECK check_my_contacts;
很遗憾,mysql中的check并不好用,MYSQL的所有引擎均不支持check约束;
类似功能的可以通过enum类型或使用触发器,或者在应用程序里面对数据进行检查再插入;
一个复杂的查询:(我们就当他是一个复杂的吧)
查找job_desired表中EngineerS的人的信息;
mysql> SELECT mc.last_name last_name,mc.first_name first_name,mc.phone,mc.email
-> FROM my_contacts mc NATURAL JOIN job_desired jd
-> WHERE jd.title = 'EngineerS';
+-----------+------------+-------------+-------------+
| last_name | first_name | phone | email |
+-----------+------------+-------------+-------------+
| Mary | DM | 13212121212 | [email protected] |
+-----------+------------+-------------+-------------+这个查询并不难,但如果每天都有类似的查询需求,我们是否能够存储查询,每日看一下结果呢;
——我们可以把查询变成视图;
创建视图:
只需在查询中加入CREATE VIEW;
mysql> CREATE VIEW v_EngineerS AS
-> SELECT mc.last_name last_name,mc.first_name first_name,mc.phone,mc.email
-> FROM my_contacts mc NATURAL JOIN job_desired jd
-> WHERE jd.title = 'EngineerS';查看视图:
把它想象成一张表,我们一样可以SELECT它的内容;
mysql> SELECT * FROM v_EngineerS;
+-----------+------------+-------------+-------------+
| last_name | first_name | phone | email |
+-----------+------------+-------------+-------------+
| Mary | DM | 13212121212 | [email protected] |
+-----------+------------+-------------+-------------+视图的实际行动:
视图的行为方式和子查询一样;
需要给子查询一个别名,这样查询会把他当成一般的表,原因在于FROM子句需要表;
当SELECT语句的结果是一个虚拟表时,若没有别名,SQL将无法取得其中的表;
mysql> SELECT * FROM (
-> SELECT mc.last_name last_name,mc.first_name first_name,mc.phone,mc.email
-> FROM my_contacts mc NATURAL JOIN job_desired jd
-> WHERE jd.title = 'EngineerS') AS engineerS_s;
+-----------+------------+-------------+-------------+
| last_name | first_name | phone | email |
+-----------+------------+-------------+-------------+
| Mary | DM | 13212121212 | [email protected] |
+-----------+------------+-------------+-------------+何为视图:
基本上,视图是一个只有在查询中使用VIEW才存在的表——被视为虚拟表(virtual table);
其行为和表一致,能执行表的操作;
和真正的虚拟表相比,真正的虚拟表不会一致保存在数据库里;
视图对数据库的好处:
1.视图把复杂的查询简化为一个命令;
视图隐藏了查询的复杂性;
2.即使一直改变数据库的结构,也不会破坏依赖表的应用程序;
底层的数据表结果变化了,但可以以视图模拟原始的表结构,这对旧的程序兼容性很好;
3.创建视图可以隐藏读者无需看到的信息;
我们可以使用视图指向原始表,但又不必透露原始表的详细信息,保护敏感信息不外泄;
实践:找出联系人愿意换工作的信息,联系人信息,举例预期最低薪资的差距;
mysql> SELECT mc.last_name,mc.first_name,mc.email,jc.salary,jd.salary_low,(jc.salary - jd.salary_low) salary_raise
-> FROM my_contacts mc
-> INNER JOIN job_current jc
-> INNER JOIN job_desired jd
-> WHERE mc.contact_id = jc.contact_id AND mc.contact_id = jd.contact_id;
+-----------+------------+-------------+--------+------------+--------------+
| last_name | first_name | email | salary | salary_low | salary_raise |
+-----------+------------+-------------+--------+------------+--------------+
| Joy | HQ | [email protected] | 1000 | 800 | 200 |
| Mary | DM | [email protected] | 2000 | 1500 | 500 |
+-----------+------------+-------------+--------+------------+--------------+
如果我们在这个SQL前加上:CREATE VIEW v_salary_raise AS,那么这一大段查询就只需要输入SELECT * FROM v_salary_raise;
利用视图进行插入、更新与删除:
SELECT、UPDATE、INSERT、DELETE均可,只要假装视图是真正的表:
语法同操作表一致,操作方式和原始表也是一致的,更新的数据需要满足原始表的约束;
可以把视图看作是原始表的门面;
但也不必要这么麻烦:
如果视图使用了统计函数,就无法用视图改变数据;包含GROUP BY、DISTINCT、HAVING,也不行;
多数情况下,使用原始表的增、删、改更容易;
我们新建一个my_contacts表的视图:
mysql> CREATE VIEW v_contacts AS
-> SELECT contact_id,last_name, first_name, gender
-> FROM my_contacts
-> WHERE gender != 'X'
-> WITH CHECK OPTION;
Query OK, 0 rows affected (0.06 sec)
mysql> select * from v_contacts;
+------------+-----------+------------+--------+
| contact_id | last_name | first_name | gender |
+------------+-----------+------------+--------+
| 1 | Joy | HQ | M |
| 2 | Mary | DM | F |
| 4 | July | FM | F |
+------------+-----------+------------+--------+
插入一条数据:
错误1:我们需要把视图当做一张真实的表,但这张表只有4列;
mysql> INSERT INTO v_contacts
-> (last_name,first_name,phone,email,gender,birthday,prof_id,zip_code)
-> VALUES
-> ('Lufu','LL','14012121213','[email protected]','X','1994-06-01',4,'10002');
ERROR 1054 (42S22): Unknown column 'phone' in 'field list'错误2:视图毕竟被视为虚拟表,操作的还是底层原始表,而原始表中 prof_id和zip_code是NOT NULL的;
mysql> INSERT INTO v_contacts
-> (last_name,first_name,gender)
-> VALUES
-> ('Lufu','LL','X');
ERROR 1423 (HY000): Field of view 'mark_list.v_contacts' underlying table doesn't have a default value删除掉视图,我们重新建一个:
mysql> DROP VIEW v_contacts;
mysql> CREATE VIEW v_contacts AS
-> SELECT contact_id,last_name, first_name, gender,prof_id,zip_code
-> FROM my_contacts
-> WHERE gender != 'X'
-> WITH CHECK OPTION;
mysql> INSERT INTO v_contacts
-> (last_name,first_name,gender,prof_id,zip_code)
-> VALUES
-> ('David','DD','M',4,'10002');查询表数据:我们看到数据插入成功了;

CHECK OPTION的作用:
上边的视图新建时,我们使用了WITH CHECK OPTION,他的作用是要求RDBMS按照WHERE子句来判断执行更新;
比如,我们针对上边的视图,插入如下的一条数据,就不会成功,因为视图创建的WHERE子句要求不为X字符;
mysql> INSERT INTO v_contacts
-> (last_name,first_name,gender,prof_id,zip_code)
-> VALUES
-> ('Lufu','LL','X',4,'10002');
ERROR 1369 (HY000): CHECK OPTION failed 'mark_list.v_contacts'但如果没有创建视图时添加CHECK OPTION的话,这条记录就可以插入成功了;
由于MySQL不支持CHECK CONSTRAINT机制,可以使用CHECK OPTION模仿该功能;
因为视图能够精确的反应表的结构,还能强迫更新语句服从WHERE子句的条件;
可更新视图:
类似上边的v_contacts视图,就是可更新视图,他是可以改变底层表的视图;
重点在于可更新视图的内容需要包括它引用的表中所有设定为NOT NULL的列;
值得注意的是,你并不会经常使用视图的INSERT、UPDATE、DELETE来更新表,因为直接操作表更容易;
使用完毕的视图,请利用DROP VIEW语句清理空间;
值得注意的是:
视图会像表一样出现在数据库中,SHOW TABLES和DESC可用来查看视图;
对于有视图的表,如果不在需要了,最好先卸除视图,然后再卸除它依据的表;
虽然检查约束和视图等对管理数据库有帮助,也有助于维护控制权,但如果两个人同时操作1列,就需要‘事务’的帮助了;
事务:
说到事务,还是要结合他最经典的场景,账务余额消费;
比如两个人同时使用卡支付消费各100,而账户余额只有150;
A、B在销售员开出支付单之后缴费,此时都会校验余额,150>100,满足条件,数据库予以支出,但最终账户余额成了-50;
在一个人支付成功之后,如果能再一次检查余额和消费金额,就能及时给出账户余额不足的提示;
新建数据库mark_amount,表my_amount:
并插入一条数据;
mysql> SELECT * FROM my_amount;
+----+------+--------+
| id | name | amount |
+----+------+--------+
| 1 | Mark | 150 |
+----+------+--------+事务场景对应的SQL如下:
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark’;
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark’;
注:出问题的地方;
mysql> UPDATE my_amount
-> SET amount = (amount - 100)
-> WHERE name = 'Mark';
mysql> UPDATE my_amount
-> SET amount = (amount - 100)
-> WHERE name = 'Mark';
mysql> SELECT * FROM my_amount;
+----+------+--------+
| id | name | amount |
+----+------+--------+
| 1 | Mark | -50 |
+----+------+--------+一开始150>100的检查都通过了,但在消费之后,账户余额竟成了负数;
如果SELECT和UPDATE能一起执行,分为两组;
在组之间进行金额检查,就可以避免这个问题了;
如果一系列SQL语句能以组的方式一起执行,而且在发生意外时SQL语句还能回到未执行的状态——满足这个功能就是事务;
事务(transaction):
是一群可完成一组工作的SQL语句;
上述过程就可以分解为两个事务:
A: SELECT TO CHECK -> UPDATE AMOUNT;
B: SELECT TO CHECK -> UPDATE AMOUNT;
在事务过程中,如果所有步骤无法不受干扰地完成,则不该完成任何单一步骤;
ACIO构成事务的四个原则:
1)ATOMICITY:原子性
事务的每个步骤必须完成,否则只能都不完成;不能只执行部分事务;
2)CONSISTENCY:一致性
事务完成后应该维持数据库的一致性,就是数据要对应的上;
3)ISOLATION:隔离性
表示每次事务都会看到具有一致性的数据库,无论其他事务如何;新的事务无法影响正在执行的事务,直到其完成;
4)DURABILITY:持久性
数据库需要正确地存储数据并保护数据免受断电或其他威胁的伤害;
通常把事务记录在主数据库以外的地方;
使用SQL管理事务:
有三种SQL事务管理工具可以保障账户的安全;
追踪:START TRANSACTION;
持续追踪后续所有SQL语句,直到输入COMMIT或ROLLBACK为止;
提交:COMMIT;
提交所有代码造成的改变;
回滚:ROLLBACK;
逆转改变过程,回到事务开始前状态;
类似断电的场景,可以在通电之后进行回滚;
值得注意的是,在你COMMIT前,数据库都不会发生任何改变;
事务在MySQL下运作:
在SQL使用事务之前,你需要采用正确的存储引擎(storage engine);
存储引擎是存储所有数据内容和结构的方式;
有些存储引擎不允许事务;
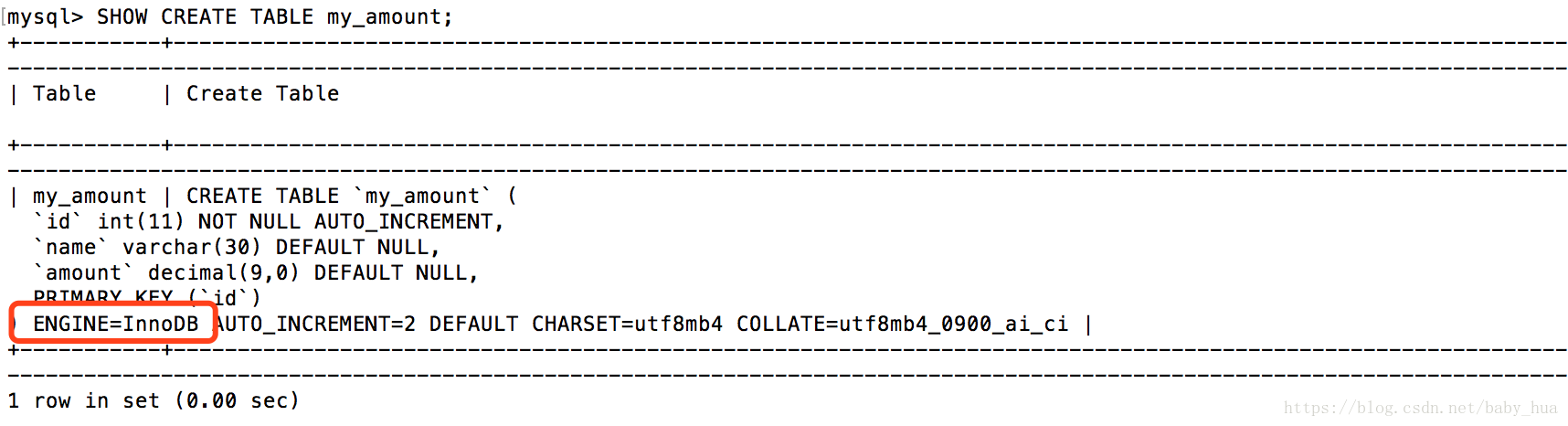
存储引擎必须是BDB或InnoDB,她他们都支持事务;
改变存储引擎:
语法:ALTER TABLE table TYPE = InnoDB;
事务示例:
我们先把账户余额更新为150;
然后使用事务进行查询+更新;
1)初始:
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark';
+--------+
| amount |
+--------+
| 150 |
+--------+2)事务:
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark';
+--------+
| amount |
+--------+
| 150 |
+--------+
1 row in set (0.00 sec)
mysql> UPDATE my_amount
-> SET amount = (amount - 100)
-> WHERE name = 'Mark';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark';
+--------+
| amount |
+--------+
| 50 |
+--------+
1 row in set (0.00 sec)
mysql> ROLLBACK;
Query OK, 0 rows affected (0.04 sec)3)回滚之后:
mysql> SELECT amount
-> FROM my_amount
-> WHERE name = 'Mark';
+--------+
| amount |
+--------+
| 150 |
+--------+
1 row in set (0.00 sec)第二次我们改用COMMIT,余额数据再次查询的值就是50了;
值得注意的是:
START TRANSACTION 和COMMIT与ROLLBACK必须搭配使用;
利用事务测试查询是最合适的方法,这样可以在数据库里实心影响数据的查询,在出错时还可以回滚;
RDBMS会记录事务过程中的每个操作,称为事务日志(transaction log),操作越多,日志越大;
事务最好留到真正需要的时候使用,避免存储空间的浪费,也避免RDBMS花费太多精力追中每个操作;
在了解了限制数据操作的内容之后,下一章我们会介绍如何控制对表的权限;
总结:
本章主要介绍了视图和事务;
1.VIEWS:视图
使用视图把查询结果当成表;很合适简化复杂查询;
2.UPDATABLE VIEWS:可更新表
有些视图能用于改变它底层的实际表;这类视图必须包含底层表的所有NOT NULL列;
3.NON-UPDATABLE VIEWS:
无法对底层表执行INSERT或UPDATE操作的视图;
4.CHECK CONSTRAINTS:检查约束
可以只让特定值插入或更新至表里;
5.CHECK OPTION:
创建可更新视图时,使用这个关键字可以强迫所有插入与更新的数据都满足视图里的WHERE条件;
6.TRANSACTIONS:事务
一组必须同进退的查询;如果这些查询无法不受干扰的全部执行,则不承认其中部分查询造成的改变;
7.START TRANSACTION:
告诉RDBMS开始事务;
在COMMIT之前的改变都不具有永久性,直到出现COMMIT和ROLLBACK;
ROLLBACK可以吧数据库带回START TRANSACTION前的状态;
补充:
1.获取全局有关日志的变量及值:
mysql> show global variables like '%log%';2.查看二进制日志:
mysql> show master logs;或
mysql> show binary logs;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000001 | 628 |
| binlog.000002 | 33083 |
| binlog.000003 | 72477 |
| binlog.000004 | 5164 |
+---------------+-----------+
4 rows in set (0.00 sec)mysql> show binlog events in 'binlog.000004';