文章目录
文献摘自A 2.9TOPS/W Deep Convolutional Neural Network SoC in FD-SOI 28nm for Intelligent Embedded Systems
1 英文缩写
- DCNN: deep convolutional neural networks
- HW: hardware
- DMA: 直接内存访问
- CAF: configurable accelerator framework
- CA: convolution accelerator
- MAC: multiply-accumulate
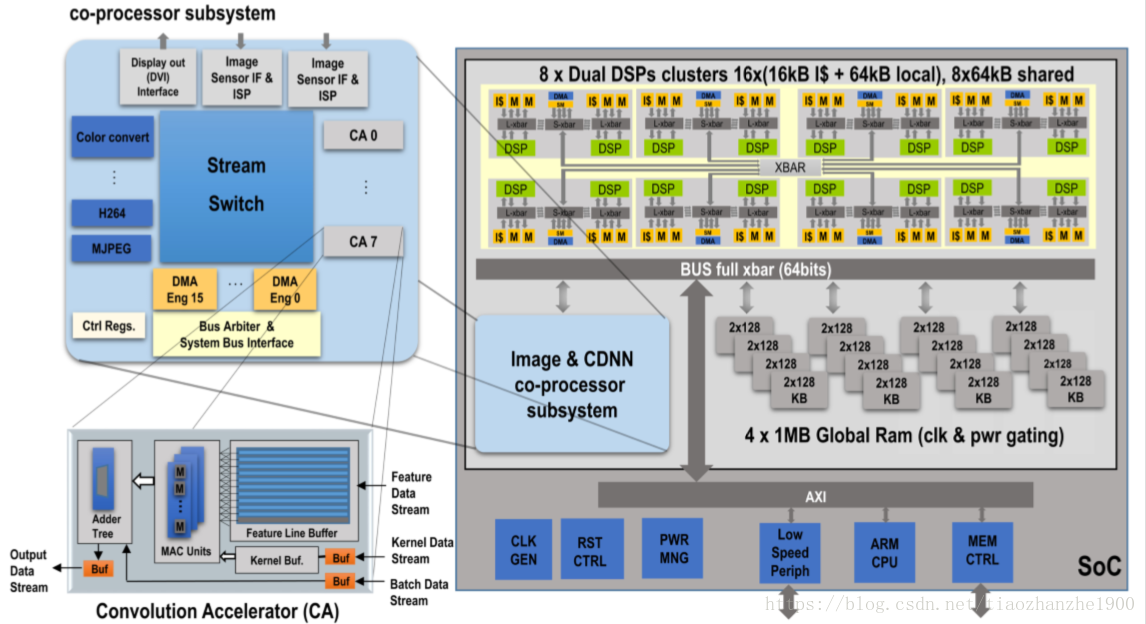
2 overall architecture
We present a state-of-the-art performance and energy efficient HW-accelerated DCNN processor with the following features:
-
An energy-efficient set of DCNN HW convolutional accelerators supporting kernel compression
-
an on-chip reconfigurable data-transfer fabric
-
a power-efficient array of DSPs to support complete real-world computer vision applications
-
an ARM-based host subsystem with peripherals(外围设备)
-
a range of high-speed IO interfaces for imaging and other types of sensors
-
a chip-to-chip multilink(多链路) to pair multiple devices together
-
ARM Cortex microcontroller with 128KB of memory
-
不同的外围设备
扫描二维码关注公众号,回复: 3689075 查看本文章
-
8 DSP clusters
-
- 每个DSP cluster有2 DSP, 4-way 16KB instruction caches, 64KB local RAMs and a 64KB shared RAM
-
Image&CDNN co-processor subsystem
-
- 8个convolution accelerator
2 accelerator subsystem
- a configurable fully connected switch to/from different kinds of sources/sinks
- various types of accelerators
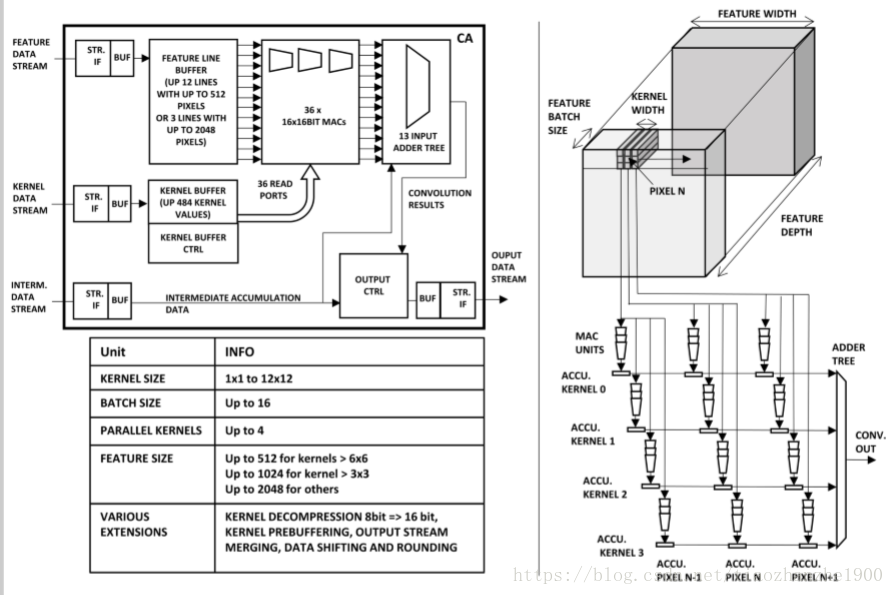
Various kernel sizes (up to 12×12), batch sizes (up to 16), and parallel kernels (up to 4) can be handled by a single CA instance, but any size kernel can be accommodated with the accumulator input.
3 convolutional accelerator
- a line buffer to fetch up to 12 feature map data words in parallel with a single memory access
- 最大kernel size:12*12,但是kernel buffer 有36个读端口
4 DSP cluster
32bit DSP
The DSPs are tasked with max or average pooling, nonlinear activation, cross-channel response normalization and classification.