1.R的编程环境
安装步骤如下:https://blog.csdn.net/m0_37345402/article/details/82839863
1.1 R语言解释器
(1)
- R操作界面分:菜单栏,快捷按钮,命令窗口。
- R是解释型语言,非编译型语言。
- R默认的命令提示符是(>),它表示正在等待输入命令。可以在命令提示符(>)后每次输入并执行一条命令。这称为交互式使用。
- R是解释型语言,因此可以一次性执行写在脚本文件中的一组命令,这称为批处理/脚本文件方式使用。
- 脚本文件以R为扩展名,如test.R。在命令台上键入source(“z.R”)来运行该脚本。
(2)
> test<-c(1,3,5)
> test
[1] 1 3 5
> rnorm(10)
[1] 0.5069663 -0.3913397 -0.9507709 0.3452721 -1.3472558 0.5304965
[7] -0.8309550 -1.7328417 -0.5921933 0.4533204
> t2<-c(2,4,6);
> t3<-c(1,2,3,4,5) #生成一个向量并赋值给t3
> t4<-c(1,2,3,
+ 4,5)
> t4
[1] 1 2 3 4 5
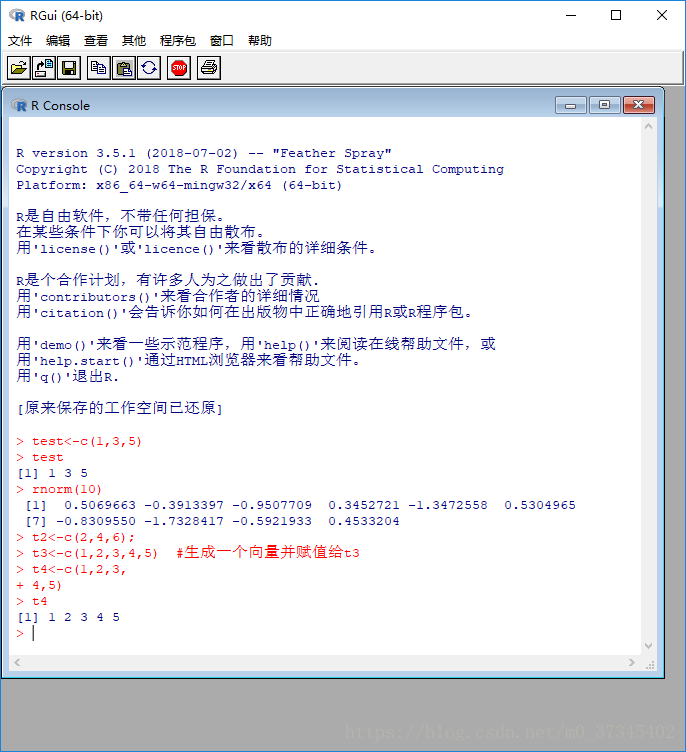
- 标签[1]表示这行的第一项是输出结果的第一项。在这个例子中,标签[1]显得有点多余。但是当输出结果有很多项会占据很多行时,这种标签会很有帮助。例如,输出结果有两行,且每行最多有6项,则第二行将会以标签[7]开头。
- 基本命令要么是表达式(expressions)要么就是赋值(assignments)。
- 表达式:会被解析(evaluate),并将结果显示在屏幕上,同时清空该命令所占内存。
- 赋值会解析表达式并且把值传给变量,但结果不会自动显示在屏幕上。
- 命令分隔符:分号或者换行符。
- R语言只支持单行注释:从井号(#)开始到句子收尾之间的语句。
- 如果一条命令在一行结束的时候在语法上还不完整, R 会给出一个不同的提示符,默认是(“+”)。该提示符会出现在第二行和随后的行中,它持续等待输入直到一条命令在语法上是完整的。
1.2 R编程环境 R Studio
R编程环境必须在安装完R解释器才能安装。
R操作界面分:代码编辑框,命令控制台,资源框,其他栏。
- 代码编辑:批处理的时候使用。
- 命令控制台:交互式使用。
- 资源框:显示内存中所含的对象。
- 其他框: windows的资源管理器,显示当前路径;帮助系统等。
问:解释器与编程环境的区别?
https://www.cnblogs.com/sword03/archive/2010/06/27/1766147.html
1.3R编程
(1)库
①
- 所有能使用的R函数都被包含在一个库(library) 中, 该库存放在磁盘的R HOME/library 目录下(R HOME 是最初安装R的地址)。
- Library目录下含有具有各种功能的包(packages )。
- 名为base的包是R的核心,其内嵌了R语言中所有像数据读写与操作这些最基本的函数。
- 包可到官网上下载,任何人都可编写包,并上传,供大家下载安装。

常用R程序包
base- R基础功能包
stats- R统计学包
cluster- 聚类分析
nlme- 线性及非线性混合效应模型
Graphics- 绘图
lattice- 栅格图
ape- 系统发育与进化分析
apTreeshape- 进化树分析
seqinr- DNA序列分析
ecodist- 生态学数据相异性分析
mefa- 生态学和生物地理学多元数据处理
mgcv- 广义加性模型相关
mvpart- 多变量分解
nlme- 线性及非线性混合效应模型
ouch- 系统发育比较
BiodiversityR - 基于Rcmdr的生物多样性数据分析
vegan- 植物与植物群落的排序,生物多样性计算
ade4- 利用欧几里得方法进行生态学数据分析
maptools- 空间对象的读取和处理
sp- 空间数据处理
spatstat- 空间点格局分析,模型拟合与检验
splancs- 空间与时空点格局分析
picante- 群落系统发育多样性分析
②R程序包安装
在CRAN 提供了每个包的源代码和编译好的MacOS、Window下的程序包
以nnet包为例,CRAN提供了: https://cran.r-project.org/web/packages/nnet/

Window平台下程序包为zip文件,安装时不要解压缩。
- 连网时,用函数install.packages(), 选择镜像后,程序将自动下载并安装程序包。 例如: 打开RGui,在控制台中输入 install.packages(“nnet")
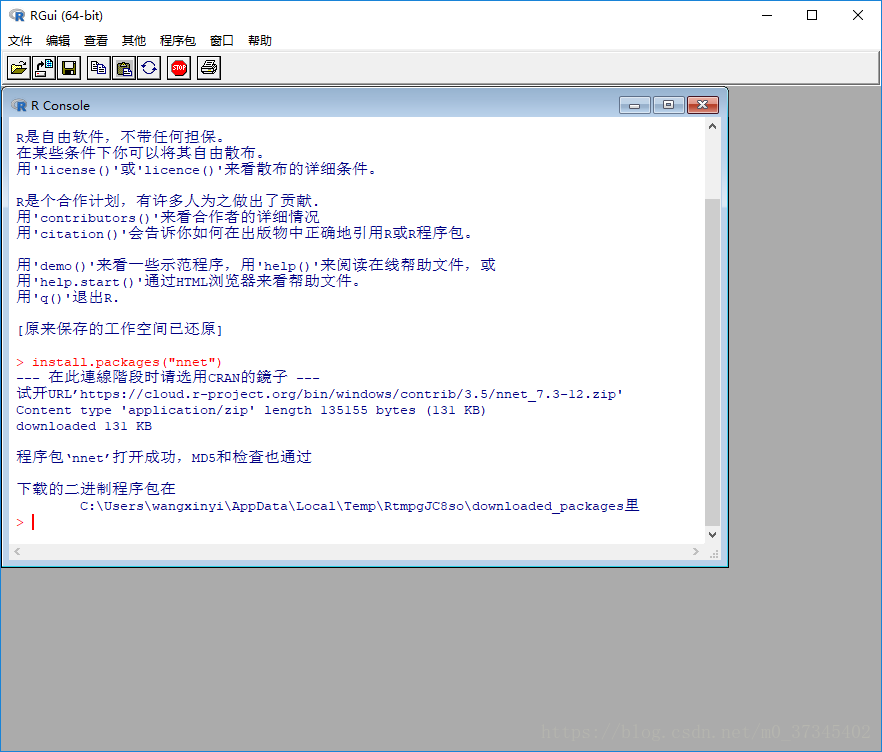
- 安装本地zip包 路径:Packages>install packages from local files 选择光盘或者本地磁盘上存储zip包的文件夹。
程序包—安装程序包——nnet
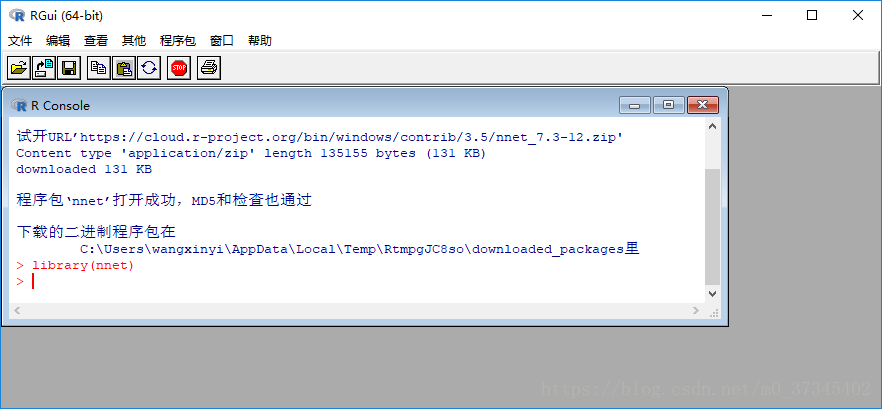
程序包在使用前,需要载入,一个会话中,只载入一次。
在控制台中输入如下命令: library(nnet) 调用程序包内的函数与R内置的函数调用方法一样
(2)工作空间
- R 可以任意地保存一个完整的环境,称为工作空间。主要分为对象和命令。
- 使用getwd()和setwd()来获取/设置工作空间目录;使用list.files()查看当前目录下的文件。工作空间跟当前工作目录相绑定。
- R保存了两个隐藏文件:.RData和.Rhistory。其中.RData以二进制的方式保存了会话中的变量值,.Rhistory以文本文件的方式保存了会话中的所有命令。
- 可用ls()和history()查看当前保存的数据和命令。rm()/remove()可删除工作空间中的变量。
(3)帮助系统
①文档和搜索: help.start() 命令会打开浏览器,显示帮助文档。包括一些入门的文档,以及搜索功能。
http://127.0.0.1:25873/doc/html/index.html
② 函数帮助:使用命令help(rnorm)或?rnorm
③运算符
与函数的帮助类似,但是需要加上单或双引号,如:
> ?'[[' # 等价于 help('[[')
> ?'+' #等价于 help('+')
> ?'if' #等价于 help('if')
④搜索
如果不知道函数名称,还可以进行搜索,比如 ??analysis #等价于 help.search('analysis’)
在所有已安装的包中,搜索包含“关键字”的帮助信息
⑤数据编辑器
当然可以使用下标操作对象,编辑对象中的数据元素。但是R提供的一个可视化的工具能够带来更多的便利,这就是数据编辑器
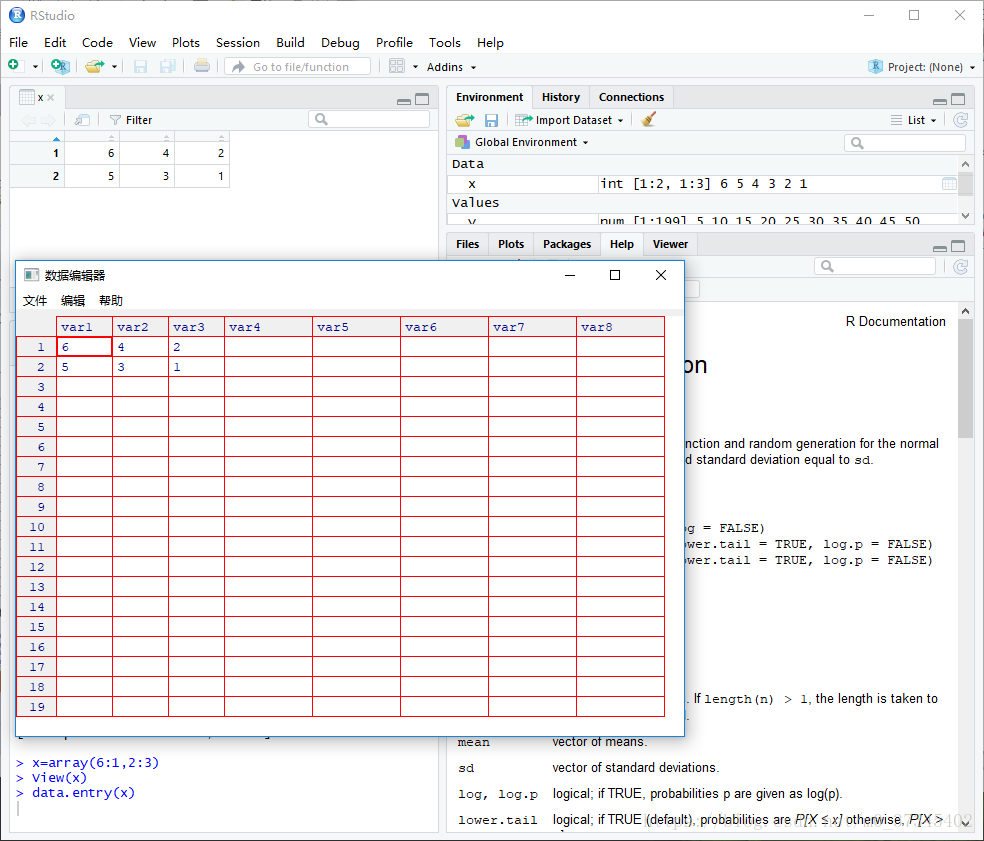
⑥ 编辑数据框
data.entry()函数可以打开数据编辑器,但是不适用于数据框。如果用data.entry()修改了数据框,会转换成列表(list)类型。
编辑数据框需要使用edit()函数:
> xnew<-edit(xold)
edit()函数只是编辑,并不赋值。如果要直接修改数据框,需要使用如下的形式:
> x = edit(x)
> fix(x) #等价于上面的形式

R语言框架
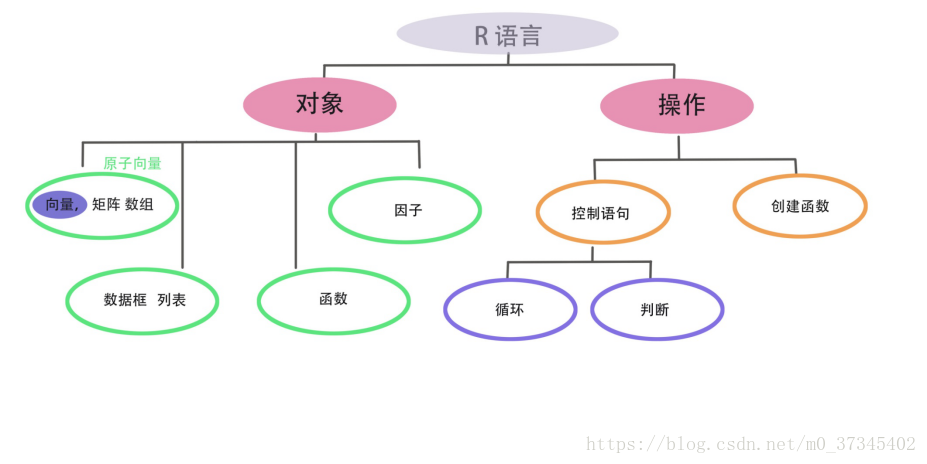
2.R的基本概念
2.1 R的基本结构
在R中,基本的数据结构有:向量,矩阵,数组,数据框,列表,因子,函数等。
向量:一系列同类型的有序元素构成。
- 向量是一维结构。
- 向量是R最简单的数据结构,在R中没有标量。标量被看成1个元素的向量。
- 向量元素必须是同类型的。
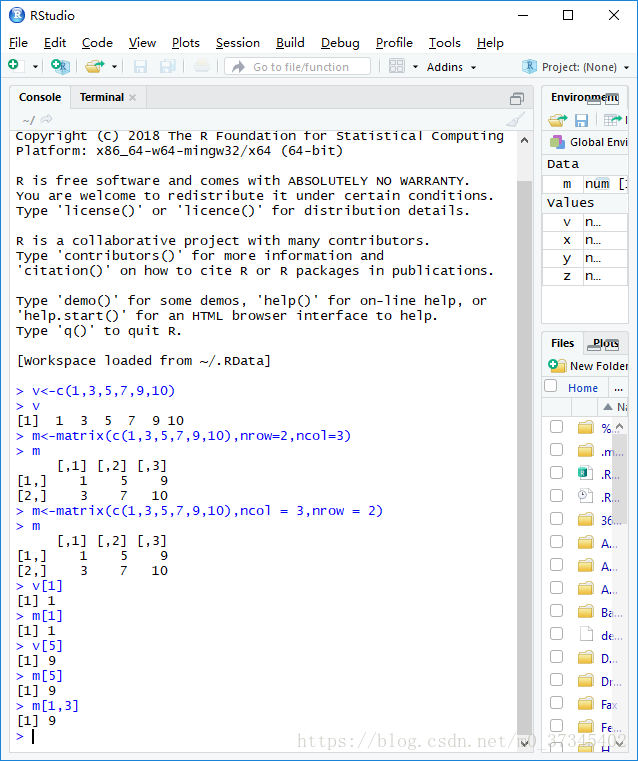
矩阵:二维的同类型元素的集合。
- 矩阵由函数matrix创建。 矩阵需要输入行数,列数。
- 矩阵是二维的,引用元素可通过双下标做索引。
- 矩阵在物理实现时,是向量附加行列数属性来实现的,因此也可以通过向量的方式引用其元素。
> v<-c(1,3,5,7,9,10)
> v
[1] 1 3 5 7 9 10
> m<-matrix(c(1,3,5,7,9,10),nrow=2,ncol=3)
> m
[,1] [,2] [,3]
[1,] 1 5 9
[2,] 3 7 10
> m<-matrix(c(1,3,5,7,9,10),ncol = 3,nrow = 2)
> m
[,1] [,2] [,3]
[1,] 1 5 9
[2,] 3 7 10
> v[1]
[1] 1
> m[1]
[1] 1
> v[5]
[1] 9
> m[5]
[1] 9
> m[1,3]
[1] 9
2.2 结构类型与元素类型
结构类型是指在R语言中,自带的对象的数据结构的类型。主要有 向量、矩阵、数组、数据框、列表等。
元素类型是指在一个对象中,其元素所属类型。主要类型有:
- 数值型:分为整数型和双精度型(默认)。
- 字符型:夹在双引号或者单引号之间的字符或字符串。
- 复数型:形如a+bi形式的复数。
- 逻辑型:只能取TRUE(T)/FALSE(F)。
- 函数型:函数对象。
- RAW:以二进制形式保存的数据。
- 缺省值:若某值不可得到(not available)或缺少值(missing value),相关位置可被赋NA值;任何NA的运算结果都为NA。
A<-c(2,4,6) A是向量,A有三个元素,A的元素是数值型。
B<-c(“Lee”,”Jack”) B是向量,B有两个元素,B的元素是字符型。
C<-c(TRUE,FALSE) C是向量,C有两个元素,C的元素是逻辑型。
2.3 对象的类型和长度
- R中皆对象。
- R中所有的对象都有元素类型和长度属性,可通过函数typeof()和length()获取;
- 数据结构可通过class()获取。
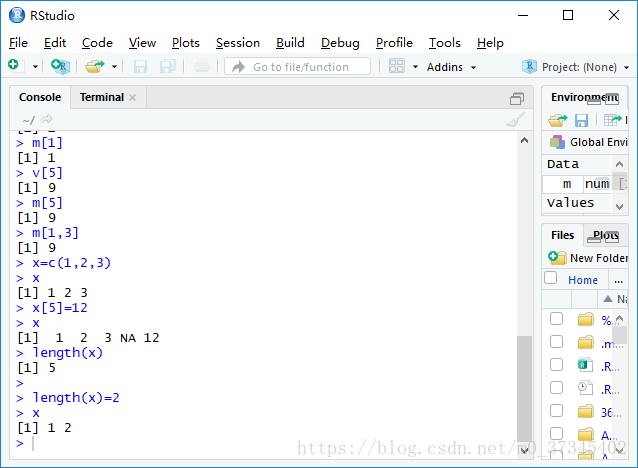
- R对象的长度可以随时发生改变,常见包括如下情况:
> # 扩大索引范围
> x=c(1,2,3)
> x
[1] 1 2 3
> x[5]=12
> x
[1] 1 2 3 NA 12
> length(x)
[1] 5
> #直接设置length属性
> length(x)=2
> x
[1] 1 2
- 前两种情况必须把对象考虑成一维才能用。比如如果用二维引用的矩阵不可如此来增加存储,这样会报错:引用超过维度。
- R语言不能通过对某元素赋NULL值的方式,删除一个元素。
> m=matrix(1:6,nrow = 3,ncol = 2)
> m
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m[,3]=matrix(c(5,6,7),nrow = 3,ncol = 1)
Error in `[<-`(`*tmp*`, , 3, value = c(5, 6, 7)) :
subscript out of bounds
> #重新复制
> m<-matrix(1:8,nrow = 2,ncol = 4)
> m
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8

2.4 对象的其他属性
- 除了typeof和length之外,其他class的对象可能还会有其他的属性,可以通过函数attributes()和attr()进行操作,例如:
函数attributes(object)将给出当前对象所具有的所有非基本属性(长度和模式属于基本属性)的一个列表。
函数attr(object,name)可以被用来选取一个指定的属性。
R的数组中,元素的排列顺序是第一下标变化最快,最后下标变化最慢。这在FORTRAN中叫做“ 按列次序”。
属性以列表形式保存,其中所有元素都有名字。
- dim属性可通过dim()操作:二维或以上的都有dim属性。
> x=1:6
> x
[1] 1 2 3 4 5 6
> attributes(x)
NULL
> dim(x)=c(3,2)
> attributes(x)
$`dim`
[1] 3 2
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> attr(x,"dim")=c(2,3)
> x
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6

2.5 对象元素的访问
(1) 用下标来访问对象中的元素:下标个数需与对象维数对应。
- R的所有对象都可用一个下标来索引,这样就把对象看成广义的“向量”——有顺序的一排元素,这个对象是表明在这个序列中元素的序号。比如上述x虽然是2维的,但是x[2]也可以,表明第二个元素。
- 下标可以是负值,这表明就不选这个位置的元素。
> x=array(6:1,2:3)
> x
[,1] [,2] [,3]
[1,] 6 4 2
[2,] 5 3 1
> x[2] #按照存储的顺序访问单个元素
[1] 5
> x[1,2] #通过多个下标访问单个元素
[1] 4
> x[1,] #返回一行
[1] 6 4 2
> x[,1] #返回一列
[1] 6 5
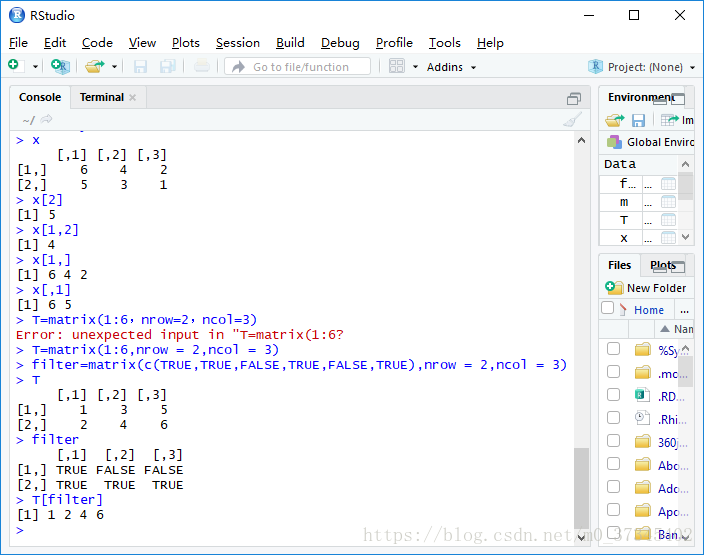
(2) 生成筛选索引:可以用等维的逻辑向量来选取元素。
- 如果是矩阵,则需要等维度的逻辑矩阵来选取元素。提取出TRUE位置的元素。结果返回的是一个向量。
- 若筛选矩阵中有NA值,则此位置处的提取值为NA
> T=matrix(1:6,nrow = 2,ncol = 3)
> filter=matrix(c(TRUE,TRUE,FALSE,TRUE,FALSE,TRUE),nrow = 2,ncol = 3)
> T
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> filter
[,1] [,2] [,3]
[1,] TRUE FALSE FALSE
[2,] TRUE TRUE TRUE
> T[filter]
[1] 1 2 4 6
(3) 若对象有names属性,还可通过names所含的字符串来索引。
- 若对象是list 或者 data frame类型的,可以用$连接names属性值,来引用对应分量。
- 注意:向量、矩阵和数组不可通过$来引用。
> x=array(6:1,2:3)
> names(x)<-c('a','b','c')
> x
[,1] [,2] [,3]
[1,] 6 4 2
[2,] 5 3 1
attr(,"names")
- "a" "b" "c" NA NA NA
> x['b']
b
5
> x$b
Error in x$b : $ operator is invalid for atomic vectors
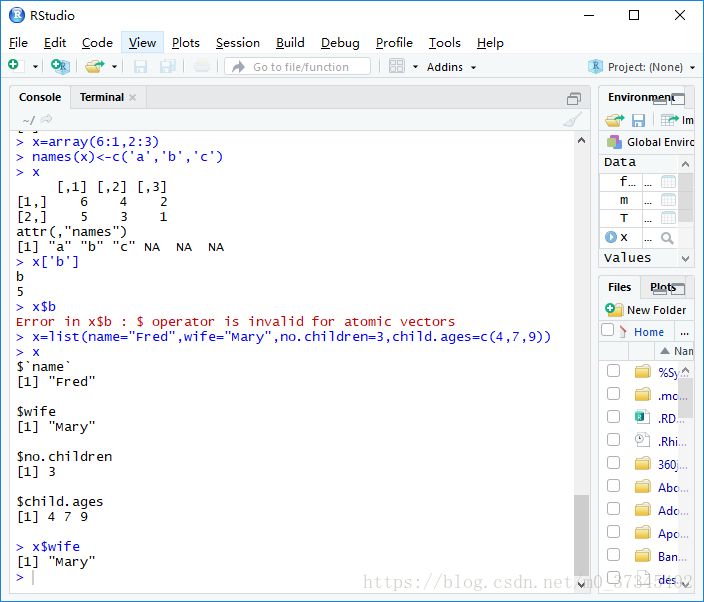
> x=list(name="Fred",wife="Mary",no.children=3,child.ages=c(4,7,9))
> x
$`name`
[1] "Fred"
$wife
[1] "Mary"
$no.children
[1] 3
$child.ages
[1] 4 7 9
> x$wife
[1] "Mary"
练习:条件筛选
创建一个2到50的向量 vector1
2, 4, 6, 8, ..., 48, 50
> vector1<-seq(from=2,to=50,by=2)
> vector1
[1] 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42
[22] 44 46 48 50
选取vector1中的第20个元素
> vector1[20]
[1] 40
选取vector1中的第10,15,20个元素
> vector1[c(10,15,20)]
[1] 20 30 40
选取vector1中的第10到20个元素
> vector1[10:20]
[1] 20 22 24 26 28 30 32 34 36 38 40
选取vector1中值大于40的元素
> vector1[vector1>40]
[1] 42 44 46 48 50

3.向量、矩阵和数组
3.1向量
(1)向量
向量是R中最简单的数据结构,其是一系列有序同类型元素的集合。(向量是一维的)
(2) 向量的创建
- 向量可以用c()函数创建,其元素用逗号分隔,放在c()的参数列表中。
- 用rep(x,y)函数创建。
- 用冒号运算符(:)创建向量。
- 用seq()函数创建向量
- by参数需与from to参数匹配
- by可以是小数
- 随机数向量的生成(后面)
> 5:8
[1] 5 6 7 8
> 5:1
[1] 5 4 3 2 1
> seq(from=12,to=30,by=3)
[1] 12 15 18 21 24 27 30
> seq(from=30,to=12,by=-3)
[1] 30 27 24 21 18 15 12
> seq(from=30,to=12,by=3)
Error in seq.default(from = 30, to = 12, by = 3) : 'by'参数的正負號不对
> seq(from=1.2,to=1.5,by=0.1)
[1] 1.2 1.3 1.4 1.5
> c(1,3,5)
[1] 1 3 5
> c("Lee","Jack")
[1] "Lee" "Jack"

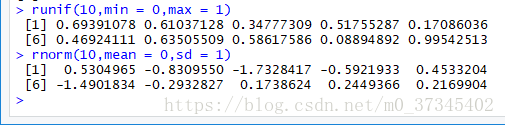
- 向量: 随机数的生成
> runif(10,min = 0,max = 1)
[1] 0.69391078 0.61037128 0.34777309 0.51755287 0.17086036
[6] 0.46924111 0.63505509 0.58617586 0.08894892 0.99542513
> rnorm(10,mean = 0,sd = 1)
[1] 0.5304965 -0.8309550 -1.7328417 -0.5921933 0.4533204
[6] -1.4901834 -0.2932827 0.1738624 0.2449366 0.2169904
(3) 向量的索引
- 下标索引
下标为向量;
下标元素可以是正整数,也可以是负整数。
- 逻辑向量索引:用等维的逻辑向量来筛选出需要选的元素。
将TRUE所在的位置的元素筛选出来。
- 名字属性索引
(名字的)字符串索引。
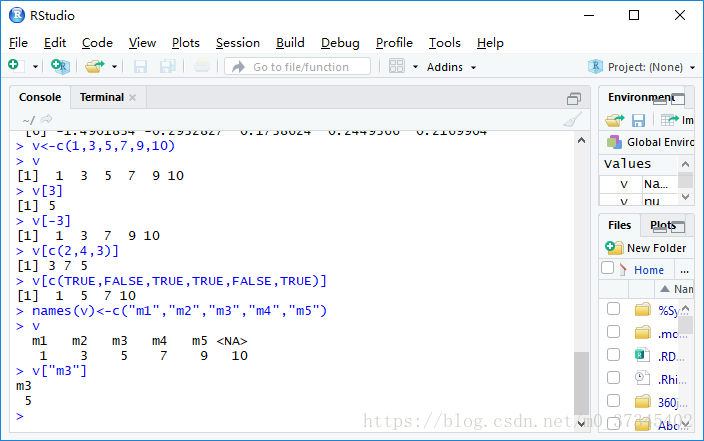
> v<-c(1,3,5,7,9,10)
> v
[1] 1 3 5 7 9 10
> v[3]
[1] 5
> v[-3]
[1] 1 3 7 9 10
> v[c(2,4,3)]
[1] 3 7 5
> v[c(TRUE,FALSE,TRUE,TRUE,FALSE,TRUE)]
[1] 1 5 7 10
> names(v)<-c("m1","m2","m3","m4","m5")
> v
m1 m2 m3 m4 m5 <NA>
1 3 5 7 9 10
> v["m3"]
m3
5
(4) 向量的运算
- 普通运算符+-*/都是元素与元素相+-*/。
- 循环补齐规则:在对两个向量使用运算符时,若要求这两个向量具有相同的长度,R会自动循环补齐,即重复较短的向量,直到它与另一个向量长度相匹配。
- 一些函数
all()/any(): 参数中是否“all为TRUE/any为TRUE”。
强筛选函数subset() : 剔除NA值。
> a<-c(1,3,5,7,9,NA,2,4,6,8)
> a
[1] 1 3 5 7 9 NA 2 4 6 8
> a[a>5]
[1] 7 9 NA 6 8
> subset(a,a>5)
[1] 7 9 6 8

函数which():返回向量中元素为TRUE的序列号。
思考题
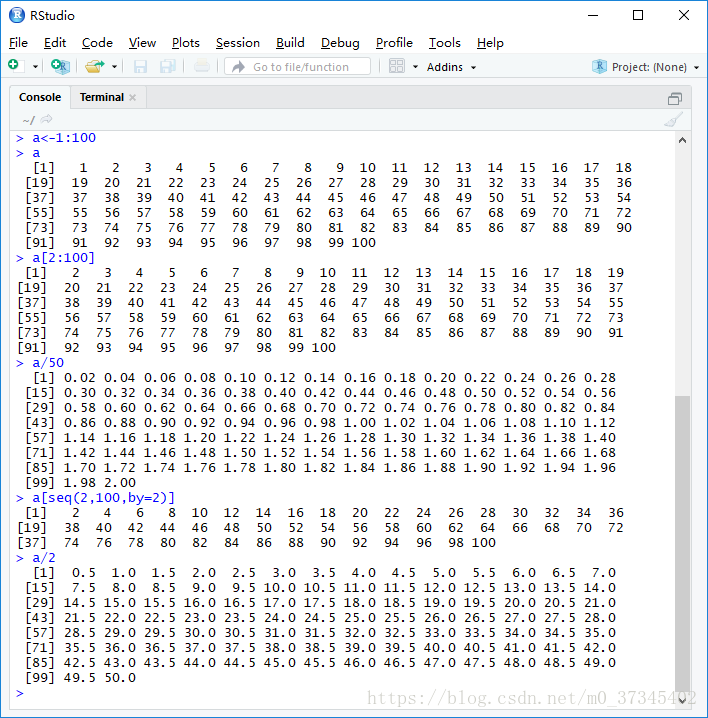
1.已知a<-1:100,若要取出向量a中的偶数位置上的元素,表达式应为(C)。
A. a[2:100] B. a/50 C.a[seq(2,100,by=2)] D.a/2
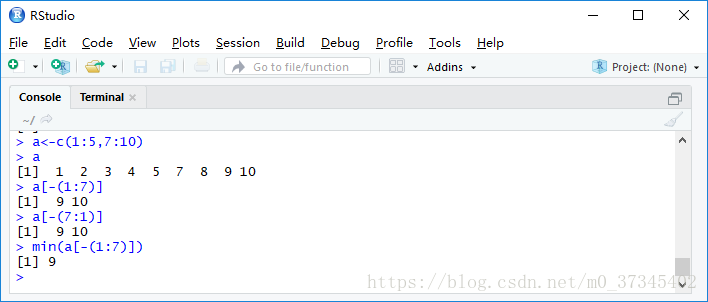
2. 已知a<-1:10,下列(D)不能输出([1] 6 7 8 9 10)。
A. a[-(1:5)] B.a[6:10] C.a[a>5] D.a>5
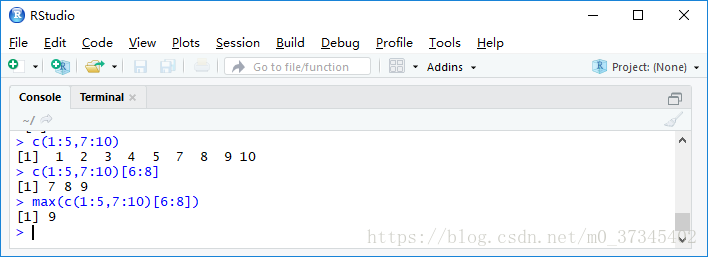
3. 表达式max(c(1:5,7:10)[6:8])的结果是(D)。
A. 1 B.6 C.7 D.9
4. 已知a<-c(1:5,7:10),则max(a[6:8]<-3:1)的结果是(B)。
A. 1 B.3 C.9 D.10
5. 已知a<-c(1:5,7:10),则min(a[-(1:7)])的结果是(C)。
A. 1 B.3 C.9 D.10


3.2矩阵
(1)矩阵:二维相同类型的元素的组合。
(2)矩阵的创建
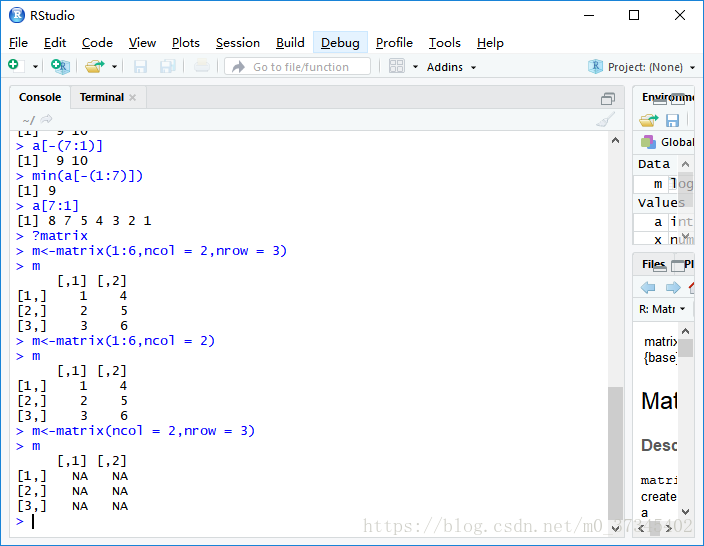
① matrix()函数
- 标准创建matrix的方法。
- 可以省略不必要的参数。
- 可以创建NA矩阵。
> ?matrix
> m<-matrix(1:6,ncol = 2,nrow = 3)
> m
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m<-matrix(1:6,ncol = 2)
> m
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m<-matrix(ncol = 2,nrow = 3)
> m
[,1] [,2]
[1,] NA NA
[2,] NA NA
[3,] NA NA
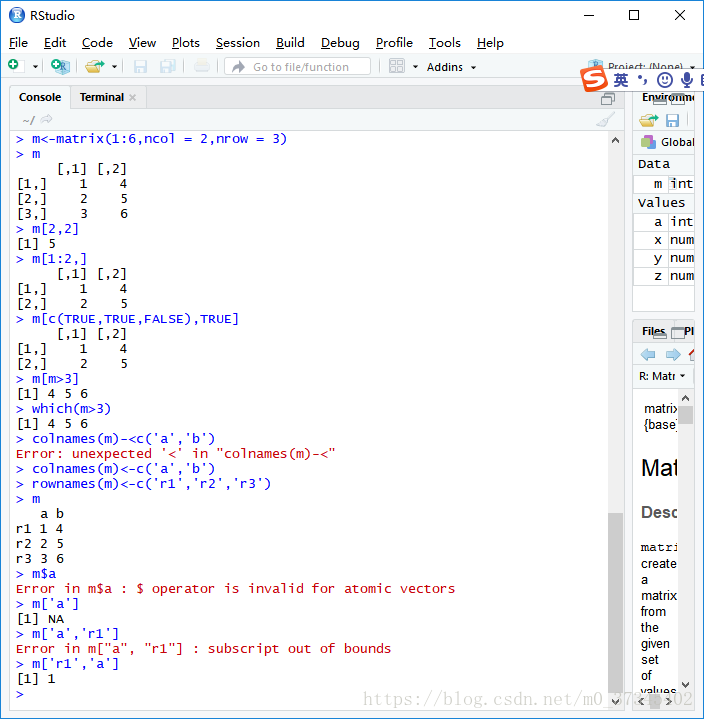
(3)元素的引用:
- 下标索引
- 逻辑向量筛选
- 名字索引——字符串索引
- [注] 向量、矩阵和数组不可用$来引用对象。
> m<-matrix(1:6,ncol = 2,nrow = 3)
> m
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m[2,2]
[1] 5
> m[1:2,]
[,1] [,2]
[1,] 1 4
[2,] 2 5
> m[c(TRUE,TRUE,FALSE),TRUE]
[,1] [,2]
[1,] 1 4
[2,] 2 5
> m[m>3]
[1] 4 5 6
> which(m>3)
[1] 4 5 6
> colnames(m)<-c('a','b')
> rownames(m)<-c('r1','r2','r3')
> m
a b
r1 1 4
r2 2 5
r3 3 6
> m$a
Error in m$a : $ operator is invalid for atomic vectors
> m['a']
[1] NA
> m['a','r1']
Error in m["a", "r1"] : subscript out of bounds
> m['r1','a']
[1] 1
(4)矩阵的运算
①线性代数运算:%*%
②apply():对矩阵的行(或列)调用函数的函数
- apply(m,dimcode,f,fargs)
- m是目标矩阵
- dimcode是维度编号:沿着此维度提取出对象的分量,然后对各分量应用对应的函数。
1代表对每一行应用函数,2代表对每一列应用函数。
- f是应用在行或列上的函数。
- fargs是f的可选参数集
- apply每一次对行或列运用函数f()时得到的结果是列矩阵
> #对矩阵z的每一列应用函数mean()
> z=matrix(1:6,nrow = 3)
> z
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> apply(z,2,mean)
[1] 2 5
> f<-function(x) x/c(2,8)
> y<-apply(z,1,f)
> y
[,1] [,2] [,3]
[1,] 0.5 1.000 1.50
[2,] 0.5 0.625 0.75

③ 矩阵的融合:
- 按行融合两个矩阵:rbind()
- 按列融合两个矩阵:cbind()
> one=c(1,1,1,1)
> one
[1] 1 1 1 1
> z<-matrix(c(1,2,3,4,1,1,0,0,1,0,1,0),nrow = 4,ncol = 3)
> z
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 2 1 0
[3,] 3 0 1
[4,] 4 0 0
> cbind(one,z)
one
[1,] 1 1 1 1
[2,] 1 2 1 0
[3,] 1 3 0 1
[4,] 1 4 0 0
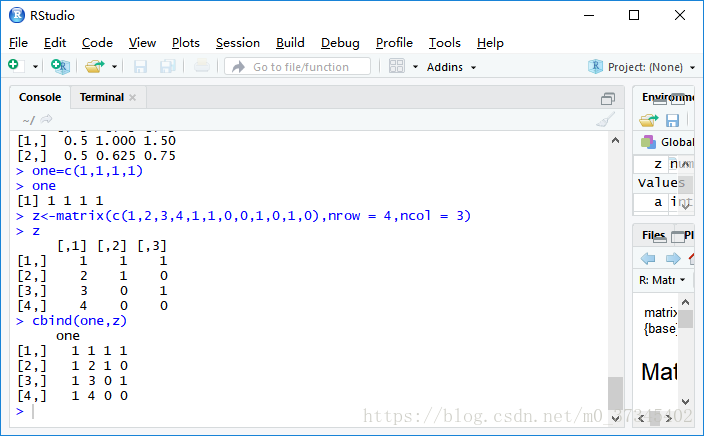
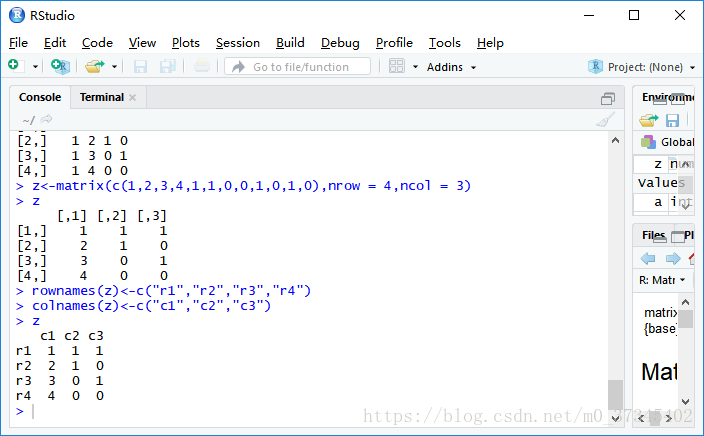
矩阵的行或列命名:
- Row命名:rownames()
- Column命名:colnames()
> z<-matrix(c(1,2,3,4,1,1,0,0,1,0,1,0),nrow = 4,ncol = 3)
> z
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 2 1 0
[3,] 3 0 1
[4,] 4 0 0
> rownames(z)<-c("r1","r2","r3","r4")
> colnames(z)<-c("c1","c2","c3")
> z
c1 c2 c3
r1 1 1 1
r2 2 1 0
r3 3 0 1
r4 4 0 0
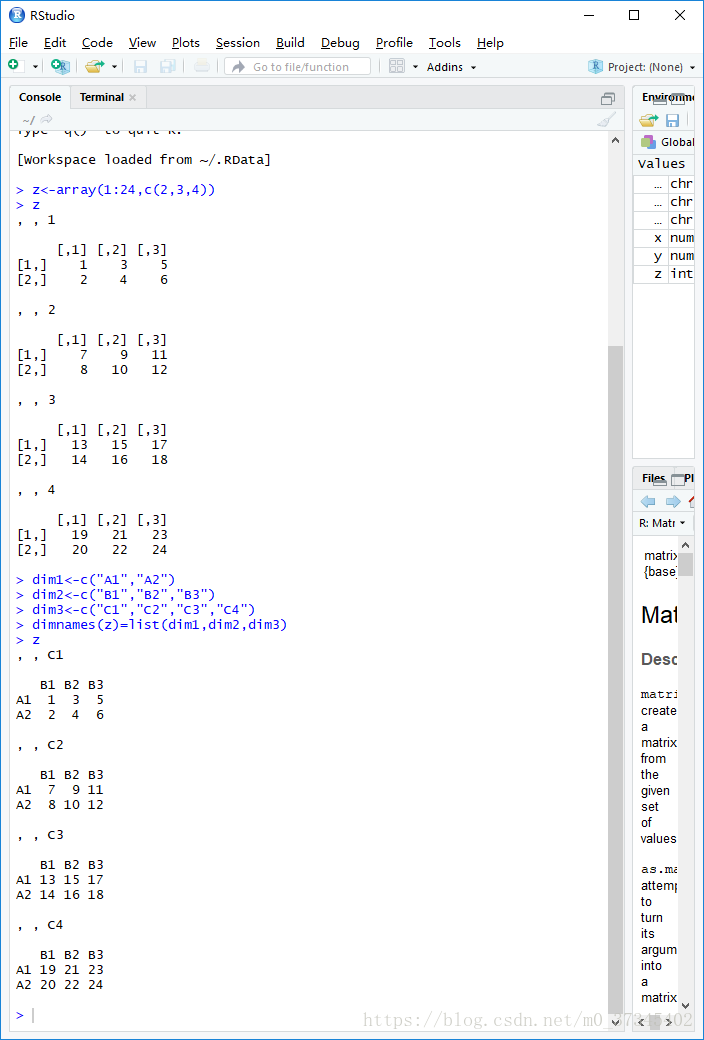
3.3数组的创建与元素的引用
(1)数组:数组是超过2维的相同元素的集合。
矩阵就是二维的数组。
(2)数组的创建
array函数来创建数组。
> z<-array(1:24,c(2,3,4))
> z
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
, , 3
[,1] [,2] [,3]
[1,] 13 15 17
[2,] 14 16 18
, , 4
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
> dim1<-c("A1","A2")
> dim2<-c("B1","B2","B3")
> dim3<-c("C1","C2","C3","C4")
> dimnames(z)=list(dim1,dim2,dim3)
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
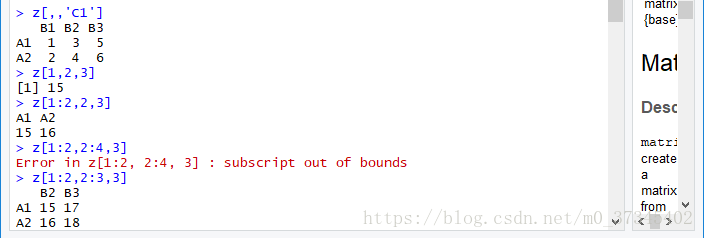
(3)元素的引用:
- 下标索引。
- 名字索引。
- 同维度逻辑对象筛选。
> z[,,'C1']
B1 B2 B3
A1 1 3 5
A2 2 4 6
> z[1,2,3]
[1] 15
> z[1:2,2,3]
A1 A2
15 16
> z[1:2,2:4,3]
Error in z[1:2, 2:4, 3] : subscript out of bounds
> z[1:2,2:3,3]
B2 B3
A1 15 17
A2 16 18
4.列表和数据框
4.1列表
-
列表是一种泛化的向量,其并没有要求所有元素都是同一类型,其元素甚至可为任意类型。
- 列表格式自由,为统计的计算结果的返回提供了极便利的方法。
(1)列表的创建
可以用list()函数创建列表。
模板:mylist<-list(name1=object1,…) 其中name可以省略
(2)元素的引用
- 列表通过双方括号提取其元素。
- 双方括号一次只能提取列表的一个组件。
- 单括号引用的为子列表,而非元素本身的类型。
- 列表可通过$加分量名字的方式来提取。
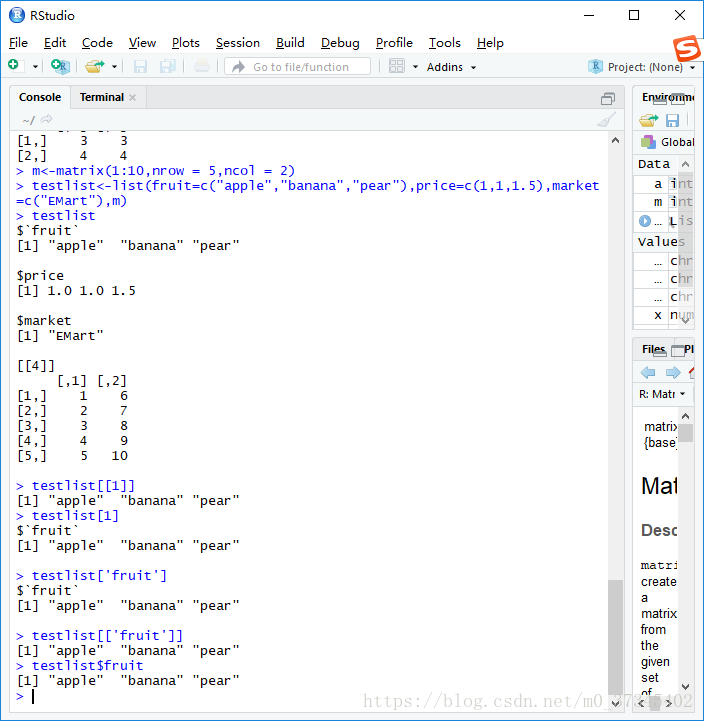
> m<-matrix(1:10,nrow = 5,ncol = 2)
> testlist<-list(fruit=c("apple","banana","pear"),price=c(1,1,1.5),market=c("EMart"),m)
> testlist
$`fruit`
[1] "apple" "banana" "pear"
$price
[1] 1.0 1.0 1.5
$market
[1] "EMart"
[[4]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
> testlist[[1]]
[1] "apple" "banana" "pear"
> testlist[1]$`fruit`
[1] "apple" "banana" "pear"
> testlist['fruit']
$`fruit`
[1] "apple" "banana" "pear"
> testlist[['fruit']]
[1] "apple" "banana" "pear"
> testlist$fruit
[1] "apple" "banana" "pear"
(3)列表的操作
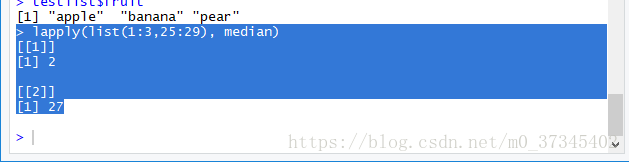
- lapply() 代表list apply,对列表(或强制转换成列表的向量)的每个组件执行给定的函数,并返回一个列表。
> lapply(list(1:3,25:29), median)
[[1]]
[1] 2
[[2]]
[1] 27
- 几个列表可以用连接函数c() 连接起来,结果仍为一个列表,其元素为各自变量的列表元素。如 > list.ABC<-c(list.A,list.B,list.C)
4.2数据框
- 数据框的mode()属性为list,因此data.frame是一种特殊的list: data.frame是对象长度都相同的list。
- 若data.frame的向量元素长度不一致,长度不够的向量自动循环补齐。
(1)数据框的创建
数据框用data.frame()生成,用法与list()函数相同。 mydf<-data.frame(name1=col1,…)
- 其中name可以省略
- 若自变量是一个变量,则变量的值变成数据框的元素,变量的名字自动变成框列名。
- 矩阵可用data.frame()转换为数据框,若该列无列名,系统默认取名 x1,x2,…。
(2)数据框元素的引用
- 数据框是特殊的list,因此可用list方式对其进行引用。
- 数据框是特殊的matrix,因此也可用matrix方法来引用其元素。
a本身是一个矩阵,而定义dimnames=list()则表示其每一个元素都被命名且命名方式是列表(list),因此在调用a中的元素的时候可以调用a[]或者a[[]]都可以。a[]是调用a本身的第几个元素,a[[]]是命名中的第几个名字下的元素。
> patientID<-c(1,2,3,4)
> age<-c(25,34,28,52)
> diabetes<-c("Type1","Type2","Type1","Type1")
> status<-c("Poor","Improved","Excellent","Poor")
> patientdata<-data.frame(patientID,age,diabetes,status)
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
> patientdata[1]
patientID
1 1
2 2
3 3
4 4
> patientdata[[1]]
[1] 1 2 3 4
> patientdata$patientID
[1] 1 2 3 4
> patientdata[1,2]
[1] 25

(3)数据框命名
数据框可看成特殊的列表:可用names()对其组件命名。
数据框有矩阵特性:可用rownames(),colnames()对行列命名。
数据框colnames属性为names属性。
在数据框中行名不能有重复。
> attributes(patientdata)
$`names`
[1] "patientID" "age" "diabetes" "status"
$class
[1] "data.frame"
$row.names
[1] 1 2 3 4
> colnames(patientdata)<-c("id","age","dia","sta")> attributes(patientdata)
$`names`
[1] "id" "age" "dia" "sta"
$class
[1] "data.frame"
$row.names
[1] 1 2 3 4
> patientdata
id age dia sta
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
> rownames(patientdata)<-c("R1","R2","R3","R4")> patientdata
id age dia sta
R1 1 25 Type1 Poor
R2 2 34 Type2 Improved
R3 3 28 Type1 Excellent
R4 4 52 Type1 Poor

(4)数据框的操作
- 当行数或列数相同时,rbind()和cbind()可以用于数据框。
- lapply()可以用于数据框,结果为一个列表。
5.因子
5.1因子
- 因子的设计思想来源于统计学的名义变量,或称为分类变量。
- 分类变量的值本质上不是数字,而是对应为分类/分组。
- 因子分为无序因子和有序因子。
- 因子的类别称为level,结合level,因子在内部被编码为指向level的正整数序号。
- 函数str():Compactly Display the Structure of an Arbitrary R Object
- 回忆为了了解R Object的函数:length(),typeof(),class(); attributes(),attr();str(),summary()
5.2因子的创建与基本操作
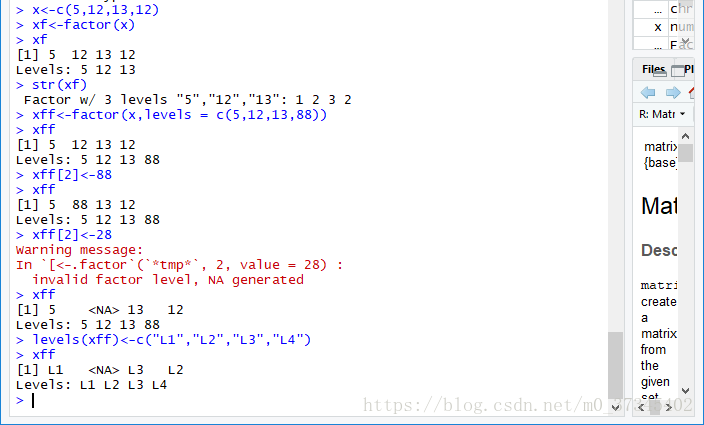
- 无序因子通过factor()创建,可带有level参数设定level取值。
- 语法是factor(data, levels, labels, ...),其中data是数据,levels是因子水平向量,labels是因子的标签向量。
- 设定level后不能添加非法level的元素;可以通过levels()修改因子的level。
- 有序因子通过ordered()创建。
> x<-c(5,12,13,12)
> xf<-factor(x)
> xf
[1] 5 12 13 12
Levels: 5 12 13
> str(xf)
Factor w/ 3 levels "5","12","13": 1 2 3 2
> xff<-factor(x,levels = c(5,12,13,88))
> xff
[1] 5 12 13 12
Levels: 5 12 13 88
> xff[2]<-88
> xff
[1] 5 88 13 12
Levels: 5 12 13 88
> xff[2]<-28
Warning message:In `[<-.factor`(`*tmp*`, 2, value = 28) : invalid factor level, NA generated
> xff
[1] 5 <NA> 13 12
Levels: 5 12 13 88
> levels(xff)<-c("L1","L2","L3","L4")
> xff
[1] L1 <NA> L3 L2
Levels: L1 L2 L3 L4
6.R语言编程结构
6.1控制语句
(1)基本概念
- 语句(statement)是一条单独的R语句或一组复合语句(包括在花括号{}中的一组语句,使用分号分隔);
- 条件(cond)是一条被解析为真(TRUE)或假(FALSE)的表达式;
- 表达式(expr)是会产生一个值,它可以放在任何需要一个值的地方;
- 序列(seq)是一个数值序列或字符串序列。
A<-B 语句
A 若计算结果是逻辑值,则为cond
A 若计算结果是数值或者字符串,则为expr
A 特殊向量对象:需为序列
(2)重复和循环
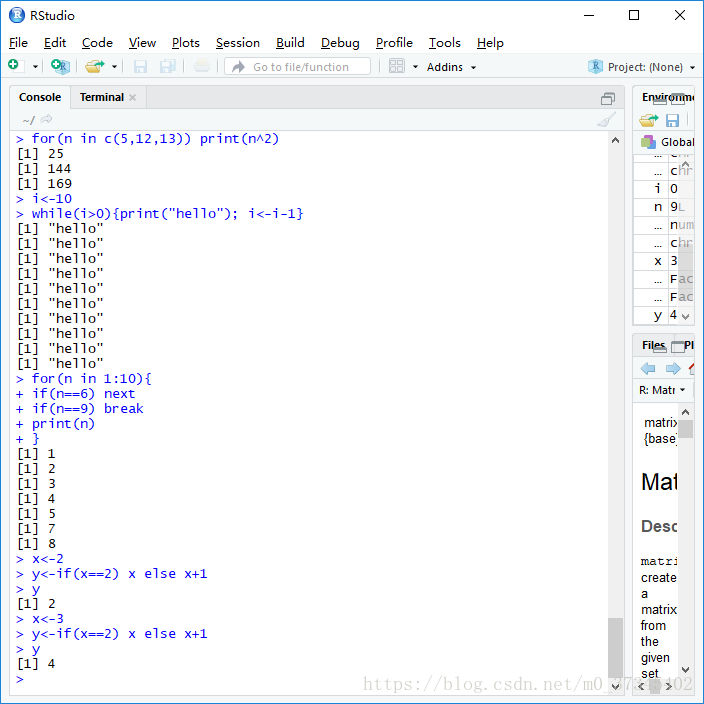
① for语句
- 语法:for (var in seq) statement
- var会依次取seq的元素值,循环执行statement
② while语句
- 语法: while (cond) statement
- 当cond为真,循环执行statement,否则跳出循环。
③next 跳过本次循环的剩余部分,直接进入下一次迭代。
④break无条件跳出循环。
> for(n in c(5,12,13)) print(n^2)
[1] 25
[1] 144
[1] 169
> i<-10> while(i>0){print("hello"); i<-i-1}
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
[1] "hello"
> for(n in 1:10){
+ if(n==6) next
+ if(n==9) break
+ print(n)
+ }
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 7
[1] 8
> x<-2
> y<-if(x==2) x else x+1
> y
[1] 2
> x<-3
> y<-if(x==2) x else x+1
> y
[1] 4
(3)判断结构
① if-else结构
- 语法:if (cond) statement
- if (cond) statement1 else statement2
② ifesle结构
- 语法: ifelse (cond, statement1,statement2)
- 当cond为真,执行statement1,否则执行statement2。
③ if-else语句条件为真返回statement1,条件为假返回statement2
6.2基本运算符

6.3函数
(1)函数
形式参数列表
- 语法:myfunction <- function(arg1,arg2=object,…) {
statements 函数体
return(object)
}
arg2称为named argument,如果不用默认值,需在调用函数时,对参数进行赋值。
返回值:函数返回值可以是任何对象,但是一般是列表。
- R函数也是一个对象:函数对象
function()是R内置的一个函数,其用来创建一个函数。
function()的形参列表和函数体可以通过函数formals()和body()获得。
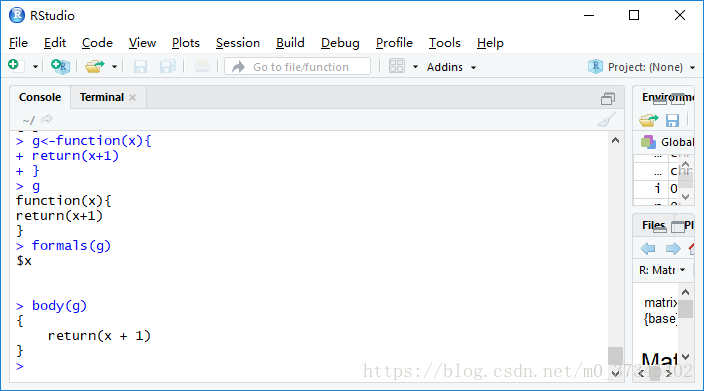
> g<-function(x){
+ return(x+1)
+ }
> g
function(x){
return(x+1)
}
> formals(g)
$x
> body(g)
{
return(x + 1)
}
- 函数是一个对象,因此可以给他们复制,也可以用作其他函数的参数。
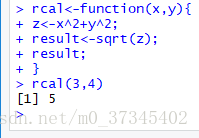
> f1<-function(a,b) return(a+b)
> f2<-function(a,b) return(a-b)
> f<-f1> f(3,2)
[1] 5
> f<-f2> f(3,2)
[1] 1
> g<-function(h,a,b) h(a,b)
> g(f1,3,2)
[1] 5
> g(f2,3,2)
[1] 1

(2)函数的环境
- 函数包括形参表,函数体还有环境空间。
- 函数的环境是由调用函数时出现的对象构成的集合。
调用函数时临时创建,退出时自动还给内存
- 函数可以嵌套,此时其环境空间也嵌套。

(3)输入输出函数
① 输入函数
read.table()------文本文件
- mydataframe<-read.table(file,options)
- 参数:file是一个带分隔符的ASCII的文本文件的文件名,options是控制如何处理数据的选项。
- 常用options选项:
header 表示文件是否在第一行包含了变量名的逻辑型变量。
row.names 指定那一列为行名的列。
sep数据中用来分开数据的分隔符。
colClasses 设置每一列的类型。当选NULL可以跳过对应列。
如设置colClasses=c(“numeric”,”Character”,”NULL”,”numeric”):第一列为数字型,第二列为字符型,跳过第三列。
读入Excel文件 数据量较大时用read.table函数从外部txt文件读取
- 将Excel中的数据另存为.txt格式(制表符间隔)或.csv格式。
- 用read.table()或read.csv()函数将数据读入R工作空间,并赋值给一个对象。
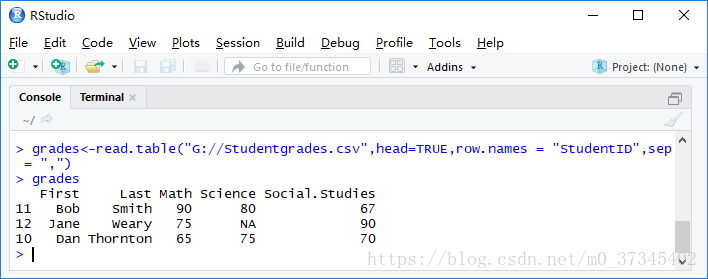
例.一个名为 studentgrades.csv的文本文件,内容如下
StudentID,First,Last,Math,Science,Social Studies
011,Bob,Smith,90,80,67
012,Jane,Weary,75,,90
010,Dan,Thornton,65,75,70
> grades<-read.table(“Studentgrades.csv”,head=TRUE,row.names=“StudentID”,sep=“,”)
> grades
First Last Math Science Social Studies
11 Bob Smith 90 80 67
12 Jane Weary 75 NA 90
10 Dan Thornton 65 75 70
返回值是数据框,字符对象转化为因子。
read.csv()------文本文件
- csv是comma separated value的英文缩写,其读取逗号分隔的文本文件。
- read.csv()与read.table()的区别可以看他们的默认参数值。
- read.table(file, header = FALSE, sep ="")
- read.csv(file,header=TRUE,sep=“,”)
② 输出函数
- write.table()是read.table()的相反操作。
- 常用方式:write.table(df, file = “文件名", row.names = FALSE, quote = FALSE)
df是待写入的数据框对象。
- write.csv()常用方式:write.csv(df, file = “文件名", row.names = FALSE, quote = FALSE)
计算均值 mean(x) 计算中位数median(x) 计算标准差sd(x) 计算方差var(x)
练习:数据读取
将下表中的数据录入Excel,另存为test1.txt文件。 用read.table函数读取该文件。
对变量test.data中的数据求均值和方差,并将其作为新列融入到表中,然后写入text2.txt文件中。
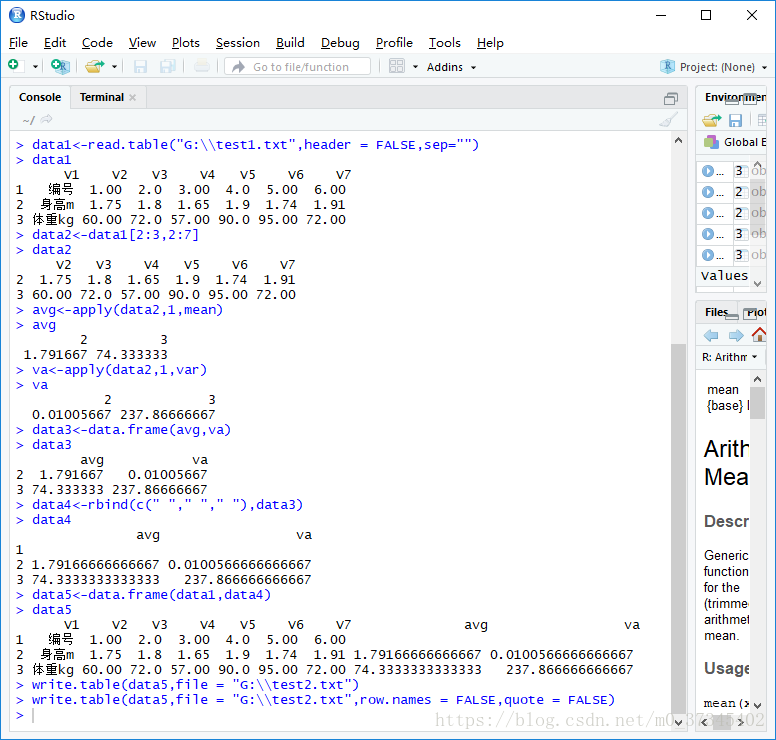
> data1<-read.table("G:\\test1.txt",header = FALSE,sep="")
> data1
V1 V2 V3 V4 V5 V6 V7
1 编号 1.00 2.0 3.00 4.0 5.00 6.00
2 身高m 1.75 1.8 1.65 1.9 1.74 1.91
3 体重kg 60.00 72.0 57.00 90.0 95.00 72.00
> data2<-data1[2:3,2:7]
> data2
V2 V3 V4 V5 V6 V7
2 1.75 1.8 1.65 1.9 1.74 1.91
3 60.00 72.0 57.00 90.0 95.00 72.00
> avg<-apply(data2,1,mean)
> avg
2 3
1.791667 74.333333
> va<-apply(data2,1,var)
> va
2 3
0.01005667 237.86666667
> data3<-data.frame(avg,va)
> data3
avg va
2 1.791667 0.01005667
3 74.333333 237.86666667
> data4<-rbind(c(" "," "," "),data3)
> data4
avg va
1
2 1.79166666666667 0.0100566666666667
3 74.3333333333333 237.866666666667
> data5<-data.frame(data1,data4)
> data5
V1 V2 V3 V4 V5 V6 V7 avg va
1 编号 1.00 2.0 3.00 4.0 5.00 6.00
2 身高m 1.75 1.8 1.65 1.9 1.74 1.91 1.79166666666667 0.0100566666666667
3 体重kg 60.00 72.0 57.00 90.0 95.00 72.00 74.3333333333333 237.866666666667
> write.table(data5,file = "G:\\test2.txt",row.names = FALSE,quote = FALSE)

(4)作图
① R作图的三步骤
- 新增一个绘图窗口
windows用windows()或打开一个文件如pdf(“my.pdf”)
平台通用: dev系列函数
新增一个绘图窗口:dev.new()
切换:dev.next()、dev.prev()
关闭绘图窗口:dev.off()
- 用高级绘图指令画出基本盘,包括坐标轴等。
- 用line等低级绘图指令在基本盘上补充。
② 高级绘图函数
- 高级绘图函数可以根据数据显示完整的图形(chart),包括坐标轴,标签、标题、序列等。而低级绘图命令自身无法生成图形,只能在高级作图命令产生的图形的基础上增加新的图形。
- plot(x,y): x(在x轴上)与(在y轴上)的二元作图。
- pie(x): x中元素数值的饼图。 x中元素必须是正的。
- hist(x) x的频率直方图。
- barplot(x) x的值的条形图。
③ 高级绘图函数的可选参数
| add=T |
使函数向低级图形函数那样不是开始一个新图形而是在原图基础上添加。 |
| axes=F |
暂不画坐标轴,随后可以用axis()函数更精确地规定坐标轴的画法。缺省值是axes=T,即有坐标轴。 |
| log="x" log="y"log="xy" |
把x轴,y轴或两个坐标轴用对数刻度绘制。 |
| type= "p" "l" "b" "o" "h" "n" |
规定绘图方式: 绘点 画线 绘点并在中间用线连接 绘点并画线穿过各点 从点到横轴画垂线 不画任何点、线,但仍画坐标轴并建立坐标系,适用于后面用低级图形函数作图。 |
| xlab="字符串" ylab="字符串" main="字符串" sub="字符串" |
定义x轴和y轴的标签。缺省时使用对象名。 图形的标题。图形的小标题,用较小字体画在x轴下方。 |

④ 低级绘图函数

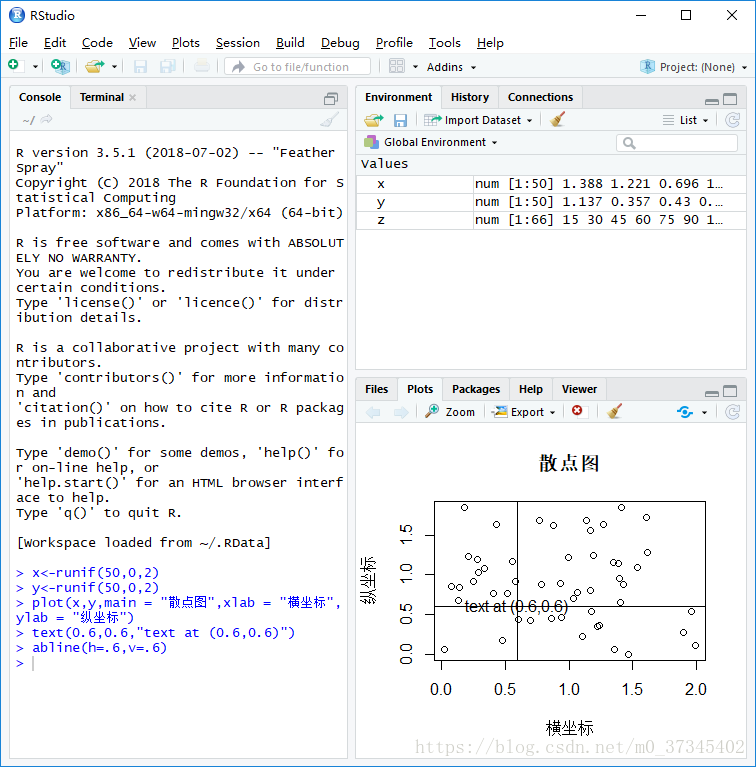
例:
#生成0到2之间的50个随机数,分别命名为x,y
> x<-runif(50,0,2)
> y<-runif(50,0,2)
#绘图:将主标题命名为“散点图”, 横轴命名为”横坐标”, 纵轴命名为“纵坐标”
> plot(x,y,main = "散点图",xlab = "横坐标",ylab = "纵坐标")
> text(0.6,0.6,"text at (0.6,0.6)")
> abline(h=.6,v=.6)