在前面的一系列文章 全文检索-》反向索引 -》相关度排名 ,我们基本上已经对Lucene有了一个初步了解,知道它是什么,可以做什么,什么场景下适用。接下来将带你深入了解Lucene的构成及设计理念等。
1.整体架构
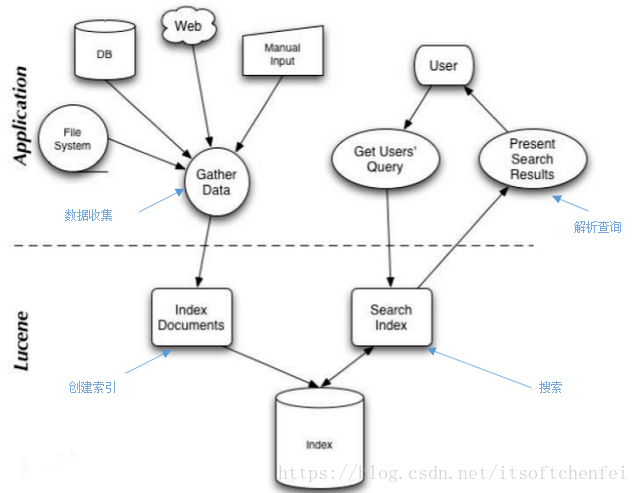
上图非常重要,可以分解为以下关键组件
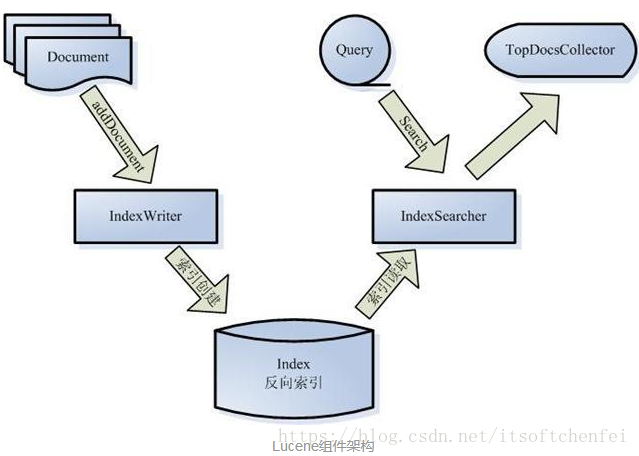
2.术语
| Index-索引库 | 文档的集合组成索引; 和一般的数据库不一样,Lucene不支持定义主键,在Lucene中不存在一个叫做Index的类,通过IndexWriter来写索引,通过IndexReader来读索引; 索引库在物理形式上一般是位于一个路径下的一系列文件; |
| Analyzer-分析器 | 一段有意义的文字需要通过Analyzer分析器分割成一个个词语后才能按关键字搜索; StandardAnalyzer是Lucene中最常用的分析器,不同的语言可以使用不同的搜索器; |
| Token-词 | Analyzer返回的结果是一串Token; Token包含一个代表词本身含义的字符串和该词在文章中相应的起止偏移位置,Token还包含一个用来存储词类型的字符串; |
| Document-文档 | 一个Document代表索引库中的一条记录,也叫做文档; 要搜索的信息封装成Document后通过IndexWriter写入索引库,调用Searcher接口按关键词搜索后,返回的也是一个封装后的Document列表; |
| Field-文档列 | 一个Document可以包含多个列,叫做Field; 创建这些列对象以后,可通过Document的add方法增加这些列; 与一般数据库不同,一个文档的一个列可以有多个值 |
| Term-词语 | 是搜索语法的最小单位,复杂的搜索语法会分解成一个Term查询; Term由两部分组成:它表示的词语和这个词语所出现的Field; |
3.核心模块
3.1 系统要求
JDK1.8 及以上版本
3.2 maven中下载
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.4.0</version>
</dependency>
3.3 Lucene模块
| 模块路径 |
功能描述 |
| org.apache.lucene.analysis |
分词器定义、标准分词器的实现 |
| org.apache.lucene.codes |
编解码 |
| org.apache.lucene.document |
文档相关 |
| org.apache.lucene.geo |
地理空间相关 |
| org.apache.lucene.index |
索引相关 |
| org.apache.lucene.search |
搜索相关 |
| org.apache.lucene.store |
存储相关 |
| org.apache.lucene.util |
其他 |
3.4 核心对象模型
| IndexWriter | lucene中最重要的的类之一,它主要是用来将文档加入索引,同时控制索引过程中的一些参数使用 |
| Analyzer | 分析器,主要用于分析搜索引擎遇到的各种文本。常用的有StandardAnalyzer分析器,StopAnalyzer分析器,WhitespaceAnalyzer分析器等。 |
| Directory | 索引存放的位置;lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。 |
| Document | Document相当于一个要进行索引的单元,任何可以想要被索引的文件都必须转化为Document对象才能进行索引 |
| Field | 字段,参阅Field域 |
| IndexSearcher | 是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具 |
| Query | 查询,lucene中支持模糊查询,语义查询,短语查询,组合查询等等, 有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类 |
| QueryParser | 是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象 |
| Hits | 在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。 在Lucene中,搜索的结果的集合是用Hits类的实例来表示的。 |
4. 示例代码
到这里如果可以没有什么直觉的话,那就从代码中体会快感
public class Lucene_test {
private String directoryPath = "target";
@Test
public void go_simple_create() throws IOException {
Directory directory = FSDirectory.open(Paths.get(directoryPath));
IndexWriterConfig config = new IndexWriterConfig();
IndexWriter writer = new IndexWriter(directory, config);//1.创建IndexWriter
System.out.println(writer.getConfig());
//支持分词索引,存储
TextField name = new TextField("name", "Donald Trump", Field.Store.YES);
Document doc = new Document(); //构建索引文档
doc.add(name);
writer.addDocument(doc); //做索引库
System.out.println("创建完成, 索引的存放位置在:" + directory);
writer.close();
directory.close();
}
@Test
public void go_simple_query() throws IOException, ParseException {
Directory directory = FSDirectory.open(Paths.get(directoryPath));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader); //打开索引
String filedName = "name";
//MultiFieldQueryParser parser = new MultiFieldQueryParser(new String[] { "name"},new StandardAnalyzer());
QueryParser parser = new QueryParser(filedName, new StandardAnalyzer());//new IKAnalyzer4Lucene7(true));
Query query = parser.parse("Trump");//解析查询
TopDocs results = searcher.search(query, 100);//检索并取回前100个文档号
for (ScoreDoc hit : results.scoreDocs) {
Document hitDoc = searcher.doc(hit.doc);//真正取文档
System.out.println(hitDoc.get(filedName));
System.out.println("doc:" + JSON.toJSONString(hitDoc));
}
reader.close();
directory.close();
}
}待补充中