什么是索引?
是为了提升SQL语句查询效率的一种数据结构,类似于一本书的目录,由此可知:
数据库系统中不仅保存着数据信息,还维护这一种特定的查数据结构,这种数据结构能够使得用户能够更快的查找到需要的数据。这种数据结构就是索引。
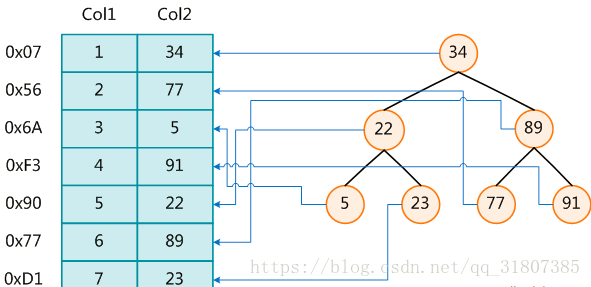
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。索引的好处显而易见,能够加大SQL语句的查询速度。但是,索引的建立也有一定的劣势:
索引的劣势:
如果用户过多的操作insert 等DML语句的时候,同时也需要维护索引。表进行INSERT、UPDATE和DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
当我们给某一个表的主键建立索引之后,每次往这个表中添加数据的时候,该索引都会去维护主键和主键之间的顺序关系,如二分搜索树,以方便下次能够非常快速的查询到存储在改表中的内容。索引也是一张表,我们在给该表建立索引的时候,可以将索引的名字理解为整颗二分搜索树的名字,而往表中添加的一个又一个的值将变成这个二分搜索树的一个又一个节点。
索引的分类:
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
演示:建表的同时创建索引:
mysql> create table customer(id int(10) unsigned auto_increment,customer_no varchar(200),customer_name varchar(200),primary key(id), key(customer_name));
Query OK, 0 rows affected (0.05 sec)
然后,我们查看我们建立的索引;
mysql> show index from customer;
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer | 1 | customer_name | 1 | customer_name | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
接下来,我们用另外一种方式建立索引—>单独建单值索引,然后查询索引:
mysql> create index idx_customer_name on customer(customer_name);
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from customer;
+----------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer | 1 | customer_name | 1 | customer_name | A | 0 | NULL | NULL | YES | BTREE | | |
| customer | 1 | idx_customer_name | 1 | customer_name | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
删除索引,并查询索引:
mysql> drop index idx_customer_name on customer;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from customer;
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer | 1 | customer_name | 1 | customer_name | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
唯一索引:索引列的值必须唯一,但是可以为空:
随表创建索引:
mysql> create table customer1(id int(10) unsigned auto_increment,customer_no varchar(200),customer_name varchar(200),primary key(id), unique(customer_no));
Query OK, 0 rows affected (0.01 sec)
mysql> show index from customer1;
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer1 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer1 | 0 | customer_no | 1 | customer_no | A | 0 | NULL | NULL | YES | BTREE | | |
+-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
单独创建唯一索引:
mysql> create unique index idx_customer1_no on customer1(customer_no);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from customer1;
+-----------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer1 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer1 | 0 | customer_no | 1 | customer_no | A | 0 | NULL | NULL | YES | BTREE | | |
| customer1 | 0 | idx_customer1_no | 1 | customer_no | A | 0 | NULL | NULL | YES | BTREE | | |
+-----------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
主键索引:假如为某一个表建立主键之后,数据库会自动给主键所在的字段建立索引:
删除主键索引就等于删除主键:修改主键索引必须drop掉原来的索引,在新建主键索引
上例已经演示
主键和unique的区别:主键有联合主键,唯一键不存在,主键等于非空+唯一
复合主键:(如果给某一个字段设置了自增长,那么该字段必须为主键)
mysql> show index from customer3;
+-----------+------------+-------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+-------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| customer3 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| customer3 | 1 | customer_no | 1 | customer_no | A | 0 | NULL | NULL | YES | BTREE | | |
| customer3 | 1 | customer_no | 2 | customer_name | A | 0 | NULL | NULL | YES | BTREE | | |
+-----------+------------+-------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
何时使用索引?
主键自动建立索引:
对于
select * from t_emp where id = x;
为什么建议加上where 子句 ,且使用id字段,因为id字段一般是主键,主键是有索引的,因此能够提升查询的效率。
频繁作为查询条件的字段应该建立索引;
有主外键关系的字段需要建立索引,可以这样理解,我们在做连接查询的时候,会使用到 on ,on后跟随的是主键,外键关系,经常会被使用到,所以我们最好在这个字段行建立索引。
单键和组合索引的选择问题,组合索引的性价比更高;排序的字段,添加上索引,效率会更高;查询中统计(聚合函数)会分组的字段,添加上索引,效率会更高。
哪些情况下不需要建立索引?
表的记录太少;经常删改的字段或者是表;where里面用不到的字段不用建立索引;过滤性不好的字段(比如带范围的,比如sex字段)不用建立索引。