继上一篇Lucene使用笔记后继续介绍后端java代码对于elasticsearch的常用方法,我的elasticsearch版本是6.4的
1. 配置文档po类和@Document、@Field解释
首先想要和elasticsearch本地库联系就要创建最基础的文档po(相当于mysql和基础po类的关系一样)
这里以Item类举例:

@Document源码解释

@Field源码解释
2. 对于索引库的基本使用(使用springboot整合好的模板类)
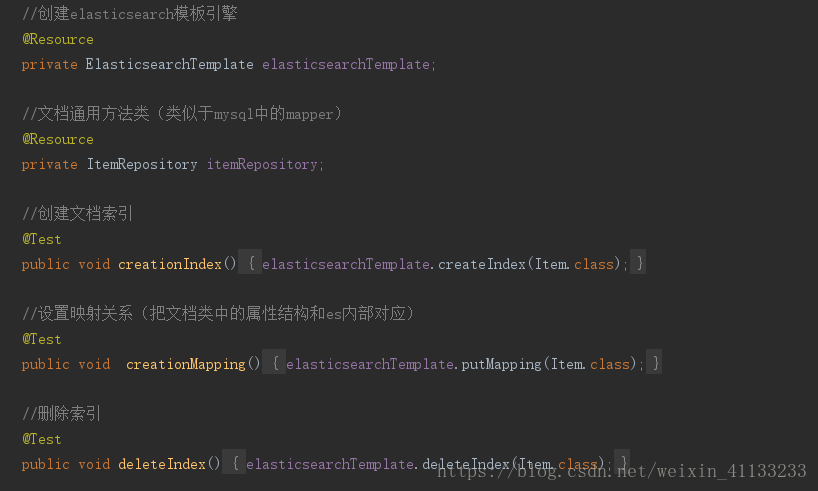
3. 对于文档的增删改查(使用文档通用方法类)
itemRepository类在下文:Dao类中举例中有详细抒写
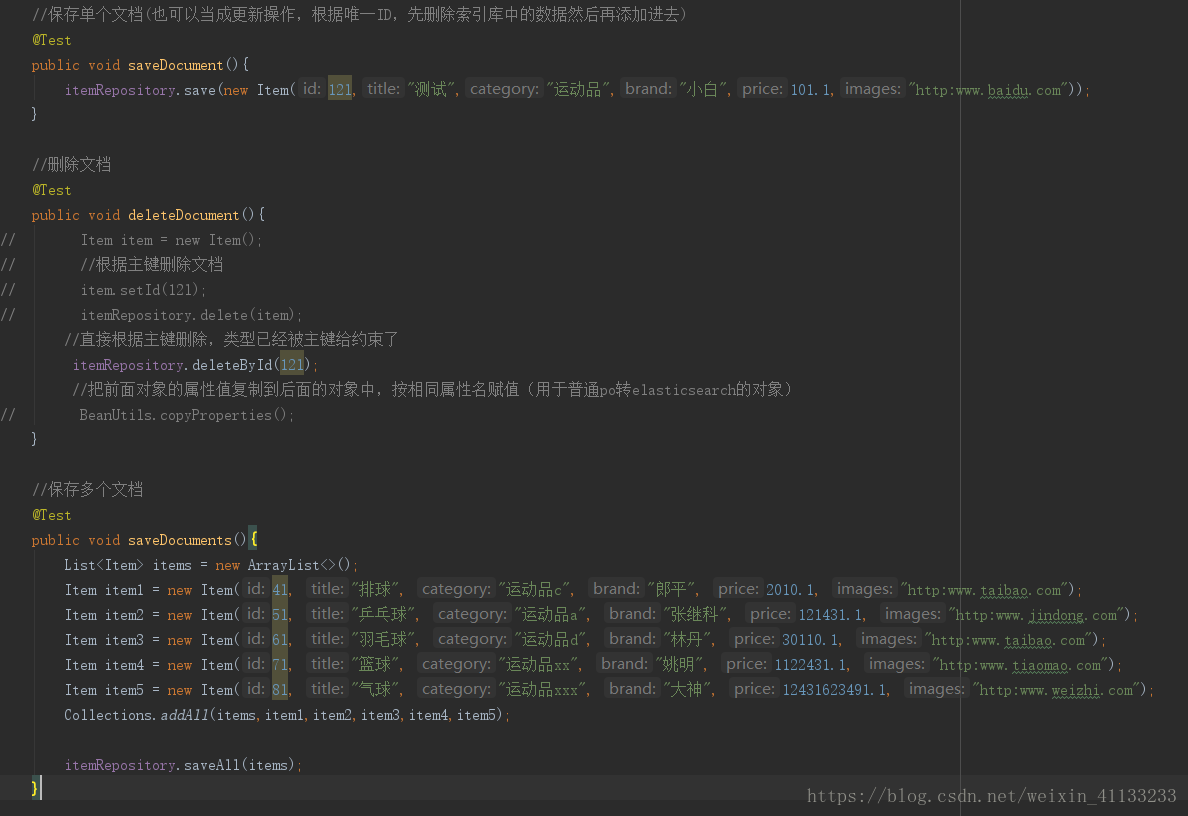
增删:
更新:
elasticsearch和Lucene一样没有提供更新方法,所以想要更新就需要重新添加但必须保持文档主键一致,这里的文档主键是文档的ID
搜索基于Lucene也是比较多的
分页查询
@Test
public void fenYeSearch(){
//第一个参数是分页数,从零开始计数表示第一页
//第二个参数是分页的条目数
Page<Item> all = itemRepository.findAll(PageRequest.of(0, 2));
for (Item i:all
) {
System.out.println(i);
}
}
按指定字段排序查询
@Test
public void testSort(){
//查询所有的里面指定排序的字段,并可以继续调用排序方式(升ascending降descending),默认降序
Iterable<Item> items = itemRepository.findAll(Sort.by("price").descending());
for (Item i:items
) {
System.out.println(i);
}
}
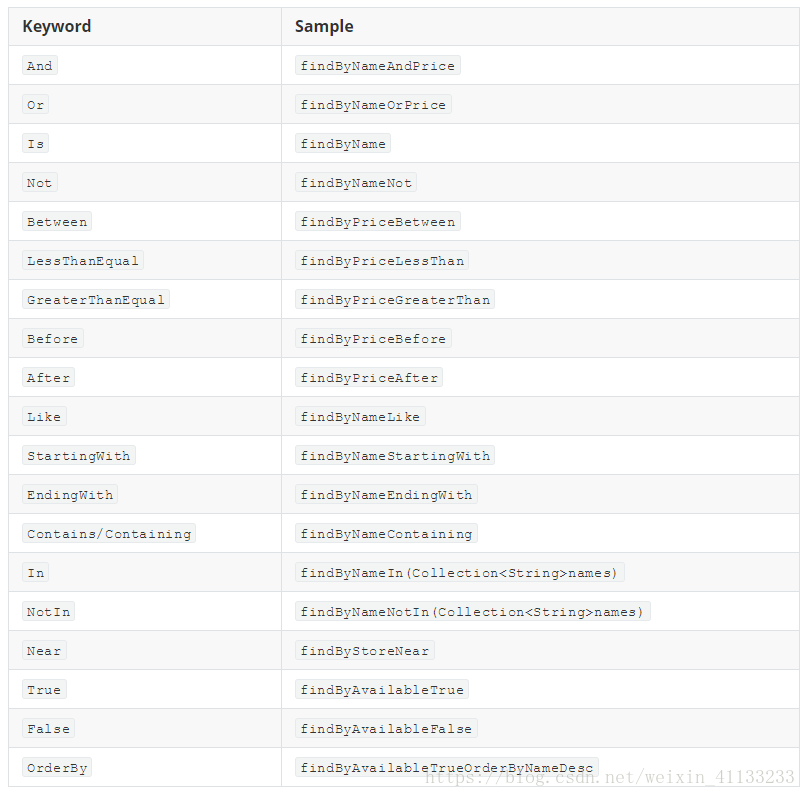
自定义方法查询(在文档通用方法类中添加)
方法名抒写规范
Dao类中举例:
// 第一个参数是需要操作的实体类,第二个参数是实体类中的主键类型
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
/**
* 根据标题查询
* @param title
* @return
*/
public List<Item> findByTitle(String title);
/**
* 根据两个数值区间查询
* @param d1
* @param d2
* @return
*/
public List<Item> findByPriceBetween(Double d1,Double d2);
}
只需要根据命名规则去抒写,方法体elasticsearch已经帮你实现了
词条查询
//根据指定的字段词条查询 (调用文档对象的dao类中的方法,根据名称去抒写功能已经完成,自定义方法)
@Test
public void termSearch(){
List<Item> list = itemRepository.findByTitle("高尔夫");
for (Item t:list
) {
System.out.println(t);
}
}
范围查询
//根据指定字段大小范围查询
@Test
public void numberSearch(){
List<Item> list = itemRepository.findByPriceBetween(8000.0, 15000.0);
for (Item b:list
) {
System.out.println(b);
}
}
自定义查询(自己构造查询条件,对比基础查询,搜索内容有了条件)
term查询
@Test
public void termSearch1(){
//创建查询条件生成器 (相当于Lucene中的查询文档对象)
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.termQuery("category","运动品a"));
//查询到的结果,自动分页,默认第一页,每页条目数是10条(itemRepository相当于文档读取器,参数中的文档查询对象需要构建下)
//在查询条件生成器中生成查询对象所以去build构建
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
match匹配查询(相当于词条匹配查询,自定义查询)
@Test
public void matchSearch(){
//创建查询条件生成器 (相当于Lucene中的查询文档对象)
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.matchQuery("title","足球"));
//查询到的结果,自动分页,默认第一页,每页条目数是10条(itemRepository相当于文档读取器,参数中的文档查询对象需要构建下)
//在查询条件生成器中生成查询对象所以去build构建
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
布尔查询(综合查询)
@Test
public void booleanSearch(){
//创建查询条件生成器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("title","篮球")).must(QueryBuilders.matchQuery("category","运动品a")));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
容错查询(最多错两个)
@Test
public void fuzzSearch(){
//创建查询条件生成器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.fuzzyQuery("title","球"));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
模糊查询
注意: ? 表示询问一个未知的占位符,* 表示询问0到n个任意占位符
@Test
public void wildCardSearch(){
//创建查询条件生成器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.wildcardQuery("title","*球*"));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
分页查询(只是在查询条件生成器中多构建了一个分页而已,基于模糊查询的分页)
@Test
public void feYeSearch(){
//创建查询条件生成器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.wildcardQuery("title","*球"));
//构建分页
nativeSearchQueryBuilder.withPageable(PageRequest.of(0,3));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
排序查询(使查询结果按指定字段排序,基于模糊查询)
@Test
public void sortSearch(){
//构建查询条件生成器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.wildcardQuery("title","*球"));
//构建排序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
组合模糊查询,分页,排序
@Test
public void mfpSearch(){
//创建查询条件构造器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.wildcardQuery("title","*球"));
//构建分页
nativeSearchQueryBuilder.withPageable(PageRequest.of(0,5));
//构建排序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC));
//查询
Page<Item> search = itemRepository.search(nativeSearchQueryBuilder.build());
for (Item i:search
) {
System.out.println(i);
}
}
由此可见,查询条件只要不违反规则是可以累加的
下面小熙来介绍elasticsearch最厉害的聚合查询吧,其查询广度、分组处理、度量计算、子聚合(类似于mysql的子查询)是小熙所膜拜的。
单一聚合查询
@Test
public void jhSearch(){
//创建查询条件构造器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
// nativeSearchQueryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
//添加聚合 (此聚合类型为terms,聚合名称是:categorys,聚合字段是category)
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("categorys").field("category"));
//查询(结果修改为聚合类分页结果)
AggregatedPage<Item> search = (AggregatedPage<Item> )itemRepository.search(nativeSearchQueryBuilder.build());
//结果中找到对应的聚合(根据聚合名称)
StringTerms category = (StringTerms)search.getAggregation("categorys");
//获取查询到的桶
List<StringTerms.Bucket> buckets = category.getBuckets();
for (StringTerms.Bucket s:buckets
) {
//获取桶中的key(就是字段下的名称)
String keyAsString = s.getKeyAsString();
System.out.println( keyAsString);
//获取桶中的数量(即为查询到的文档数量)
long docCount = s.getDocCount();
System.out.println(docCount);
}
}
包含子聚合的聚合查询
@Test
public void jh2Search(){
//创建查询条件构造器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("brands").field("brand")
//创建子聚合工程(对父聚合工程的结果进行求取平均值)
.subAggregation(AggregationBuilders.avg("avg").field("price"))
);
//查询
AggregatedPage<Item> search = (AggregatedPage<Item>)itemRepository.search(nativeSearchQueryBuilder.build());
//根据聚合名称获取对应聚合
StringTerms brands = (StringTerms)search.getAggregation("brands");
//获取查询到的桶
List<StringTerms.Bucket> buckets = brands.getBuckets();
for (StringTerms.Bucket b:buckets
) {
//获取父聚合的字段名
System.out.print("品牌名称:"+b.getKeyAsString() + "查到的文档数:"+b.getDocCount());
//获取父聚合中桶中数量
System.out.println();
//获取子聚合,转为Map集合,获取构建子聚合时价格平均值的key,这里指定的是avg(强转为平均值)。
InternalAvg avg = (InternalAvg)b.getAggregations().asMap().get("avg");
System.out.println("\t\t平均价格是:"+avg.getValue());
}
}
如果要使用head插件在浏览器中查看需要在配置文件中配置(我的配置文件是yml的)
spring:
data:
elasticsearch:
# 访问集群名称,自己修改为昵称了
cluster-name: chengxi
# 注意不要写协议名,否则会报错(访问节点ip和端口号)
cluster-nodes: 127.0.0.1:9300
补述
今天小熙想在一个索引库中,创建两个type类,但是抛错:
`Rejecting mapping update to [XXX] as the final mapping would have more than 1 type: [XXX, XX]"`,
纠结了好久,原来才发现我的elasticsearch是6.4.0版本的,但是官方宣布6.0的版本不允许一个index下面有多个type,并且官方说是在接下来的7.0版本中会删掉type。所以一个索引库中只能创建一个type了。
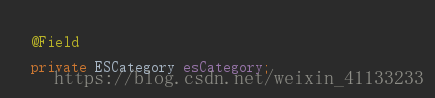
附上小熙创建的,文档类型字段的创建过程:
后台字段创建
前台head插件显示:
本次小熙的分享到此结束了,个人理解难免有失偏颇,如有误解还望不吝赐教。
(本文仅供学习交流,如有转载请注明出处)