-
域名解析->域名 ->缓存->根域dns->顶级域dns->本域dns->服务器IP
1.搜索浏览器自身DNS缓存,如果不存在或者过期(>60s)放弃
2.搜索操作系统自身的dns缓存
3.读取本地的HOST文件
4.浏览器发起一个DNS的系统调用 域名解析
5.客户端通过随机端口使用tcp协议服务器ip的80端口发起连接请求 三次握手
6.tcp/ip连接请求建立后浏览器可以向服务器发起http请求
7.http客户端发起请求,创建端口,解析用户操作,拼接请求头信息
8.http客户端并向服务器的该端口发送request头信息
9.服务器监听端口 如80
10.http监听到发到80端口的请求头信息
11.http服务器解析头信息
12.http服务器 按照请求头信息,返回相应响应头信息response
13.响应头信息发送给http客户端,客户端解析响应头信息,并完成其他操作
14.完成一次http请求上文来自 https://www.cnblogs.com/greatluoluo/p/5725082.html
-
在浏览器中敲入一个 URL 到获取网页内容发生了一个怎样的过程?
先了解一下 URI 和 URL
URI 全称为 UniformResource Identifier,即统一资源标志符,
URL 全称为 Universal Resource Locator,即统一资源定位符。超文本
超文本英文名称叫做 Hypertext,我们在浏览器里面看到的网页就是超文本解析而成的,其网页源代码是一系列 HTML 代码,而这网页的源代码HTML 就可以称作超文本。http
HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫做超文本传输协议,
HTTP协议是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证传送高效而准确地传送超文本文档。
在URL 的开头会有 http 或 https,这个就是访问资源需要的协议类型,有时我们还会看到 ftp、sftp、smb 开头的 URL -
http请求过程
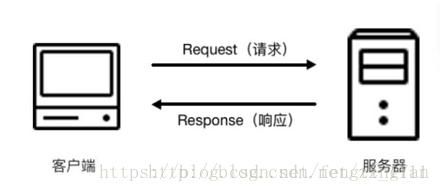
我们在浏览器中输入一个 URL,回车之后便会在浏览器中观察到页面内容,实际上这个过程是浏览器向网站所在的服务器发送了一个 Request,即请求,网站服务器接收到这个 Request 之后进行处理和解析,然后返回对应的一个 Response,即响应,然后传回给浏览器,Response里面就包含了页面的源代码等内容,浏览器再对其进行解析便将网页呈现了出来,模型如图所示: -
http://www.baidu.com/,输入该 URL,敲击回车访问这个页面,观察一下在这个过程中发生了怎样的网络请求?
F12 -> Network.
这一个条目的各列分别代表:
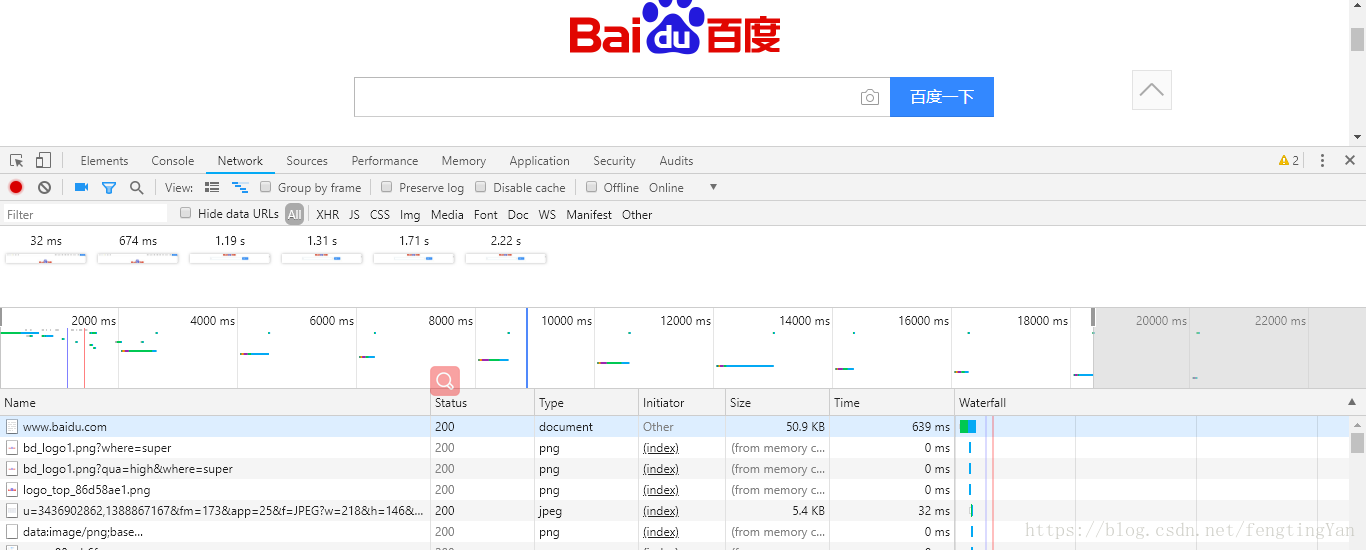
第一列 Name,即 Request 的名称。一般会用URL的最后一部分内容当做名称。
第二列 Status,即 Response 的状态码。这里显示为 200,代表 Response 是正常的,通过状态码我们可以判断发送了 Request 之后是否得到了正常的 Response。
第三列 Type,即 Request 请求的文档类型。这里为 document,代表我们这次请求的是一个 HTML 文档,内容就是一些 HTML 代码。
第四列 Initiator,即请求源。用来标记 Request 是由哪个对象或进程发起的。
第五列 Size,即从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源则该列会显示 from cache。
第六列 Time,即发起 Request 到获取到 Response 所用的总时间。
第七列 Timeline,即网络请求的可视化瀑布流。

General
Request URL: https://www.baidu.com/
Request Method: GET
Status Code: 200 OK
Remote Address: 61.135.169.125:443
Referrer Policy: no-referrer-when-downgrade扫描二维码关注公众号,回复: 3646634 查看本文章
首先是 General 部分,
Request URL 为 Request 的 URL,
RequestMethod 为请求的方法,.
Status Code 为响应状态码,
Remote Address 为远程服务器的地址和端口,
Referrer Policy 为 Referrer 判别策略。
Response Headers
Bdpagetype: 2
Bdqid: 0x81a0a6a90003fce2
Cache-Control: private
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Fri, 12 Oct 2018 08:27:51 GMT
Expires: Fri, 12 Oct 2018 08:27:51 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=319; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=1438_27215_21122_20928; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Transfer-Encoding: chunked
X-Ua-Compatible: IE=Edge,chrome=1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
Request Headers
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Cookie: BAIDUID=91549D75F9BB27A514CBC4671D78FCF3:FG=1; BIDUPSID=91549D75F9BB27A514CBC4671D78FCF3; PSTM=1536133533; BD_UPN=12314753; MSA_WH=388_483; MCITY=-176%3A; ispeed_lsm=2; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=FBFdFJQQVo4eUROWTVtSjZBWHhhdzlxa2JZZk1lZGNJfms4eEczcVpoSmMyZVpiQUFBQUFBJCQAAAAAAAAAAAEAAAAPIGWVMzIxeWZ0MDAxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFxMv1tcTL9bc; H_PS_PSSID=1438_27215_21122_20928; delPer=0; BD_CK_SAM=1; PSINO=2; BD_HOME=1
DNT: 1
Host: www.baidu.com
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36
再继续往下看可以看到有一个
Response Headers 和一个 Request Headers,这分别代表响应头和请求头,
请求头里面带有许多请求信息,例如浏览器标识、Cookies、Host 等信息,这是Request 的一部分,服务器会根据请求头内的信息判断请求是否合法,进而作出对应的响应,返回Response,那么在图中看到的 Response Headers 就是 Response 的一部分,例如其中包含了服务器的类型、文档类型、日期等信息,浏览器接受到 Response 后,会解析响应内容,进而呈现网页内容。
详细解释往下看
5. 请求 Request 和响应 Response 都包含了哪些内容?
(1) Request
Request,即请求,由客户端向服务端发出。
可以将 Request 划分为四部分内容:
Request Method、Request URL、Request Headers、Request Body,
即请求方式、请求链接、请求头、请求体。
Request Method
请求方式,请求方式常见的有两种类型,GET 和 POST。
GET 请求: 浏览器中直接输入一个 URL 并回车,这便发起了一个 GET 请求
POST 请求: 表单提交
> 我们在浏览器中直接输入一个 URL 并回车,这便发起了一个 GET 请求,请求的参数会直接包含到 URL 里,例如百度搜索Python,这就是一个 GET 请求,链接为:https://www.baidu.com/s?wd=Python,URL中包含了请求的参数信息,这里参数 wd 就是要搜寻的关键字。
> POST 请求大多为表单提交发起,如一个登录表单,输入用户名密码,点击登录按钮,这通常会发起一个 POST 请求,其数据通常以 Form Data,即表单的形式传输,不会体现在 URL 中。
GET 和 POST 请求方法有如下区别:
GET 方式请求中参数是包含在 URL 里面的,数据可以在 URL 中看到,而 POST 请求的 URL 不会包含这些数据,数据都是通过表单的形式传输,会包含在 Request Body 中。
GET 方式请求提交的数据最多只有 1024 字节,而 POST 方式没有限制。
所以一般来说,网站登录验证的时候,需要提交用户名密码,这里包含了敏感信息,使用GET方式请求的话密码就会暴露在URL里面,造成密码泄露,所以这里最好以POST方式发送。文件的上传时,由于文件内容比较大,也会选用POST方式。
我们平常遇到的绝大部分请求都是 GET 或 POST 请求,另外还有一些请求方式,如 HEAD、PUT、DELETE、OPTIONS、CONNECT、TRACE,我们简单将其总结如下:
方法描述 GET请求指定的页面信息,并返回实体主体。
HEAD类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。
POST向指定资源提交数据进行处理请求,数据被包含在请求体中。
PUT从客户端向服务器传送的数据取代指定的文档的内容。
DELETE请求服务器删除指定的页面。
CONNECTHTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS允许客户端查看服务器的性能。
TRACE回显服务器收到的请求,主要用于测试或诊断。
本表参考:http://www.runoob.com/http/http-methods.html。
Request Headers
请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、Referer、User-Agent等,下面将一些常用的头信息说明如下:
Accept,请求报头域,用于指定客户端可接受哪些类型的信息。
Accept-Language,指定客户端可接受的语言类型。
Accept-Encoding,指定客户端可接受的内容编码。
Host,用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置。从 HTTP 1.1 版本开始,Request 必须包含此内容。
Cookie,也常用复数形式 Cookies,是网站为了辨别用户进行 Session 跟踪而储存在用户本地的数据。Cookies 的主要功能就是维持当前访问会话,例如我们输入用户名密码登录了某个网站,登录成功之后服务器会用 Session 保存我们的登录状态信息,后面我们每次刷新或请求该站点的其他页面时会发现都是保持着登录状态的,在这里就是 Cookies 的功劳,Cookies 里有信息标识了我们所对应的服务器的 Session 会话,每次浏览器在请求该站点的页面时都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录的状态,所以返回的结果就是登录之后才能看到的网页内容。
Referer,此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、做防盗链处理等。
User-Agent,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息可以伪装为浏览器,如果不加很可能会被识别出为爬虫。
Content-Type,即 Internet Media Type,互联网媒体类型,也叫做 MIME 类型,在 HTTP 协议消息头中,使用它来表示具体请求中的媒体类型信息。例如 text/html 代表 HTML 格式,image/gif 代表 GIF 图片,application/json 代表 Json 类型,
更多对应关系可以查看此对照表:http://tool.oschina.net/commons。
Request Body
即请求体,一般承载的内容是 POST 请求中的 Form Data,即表单数据,而对于 GET 请求 Request Body 则为空。
(2)Response
Response,即响应,由服务端返回给客户端。
Response 可以划分为三部分,Response Status Code、Response Headers、Response Body。
Response Status Code
响应状态码,此状态码表示了服务器的响应状态,
如
200 则代表服务器正常响应,
404 则代表页面未找到,
500 则代表服务器内部发生错误。
Response Headers
响应头,其中包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等,下面将一些常用的头信息说明如下:
Date,标识 Response 产生的时间。
Last-Modified,指定资源的最后修改时间。
Content-Encoding,指定 Response 内容的编码。
Server,包含了服务器的信息,名称,版本号等。
Content-Type,文档类型,指定了返回的数据类型是什么,如text/html 则代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回了图片。
Set-Cookie,设置Cookie,Response Headers 中的 Set-Cookie即告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
Expires,指定 Response 的过期时间,使用它可以控制代理服务器或浏览器将内容更新到缓存中,如果再次访问时,直接从缓存中加载,降低服务器负载,缩短加载时间。
Resposne Body
即响应体,最重要的当属响应体内容了,响应的正文数据都是在响应体中,如请求一个网页,它的响应体就是网页的 HTML 代码,请求一张图片,它的响应体就是图片的二进制数据。所以最主要的数据都包含在响应体中了
响应体内容
我们在浏览器开发者工具中点击 Preview,就可以看到网页的源代码,这也就是响应体内容,是解析的目标。
我们在做爬虫时主要解析的内容就是 Resposne Body,通过 Resposne Body 我们可以得到网页的源代码、Json 数据等等,然后从中做相应内容的提取。
以上便是 Response 的组成部分。
转载请务必附上原博主博文链接:https://blog.csdn.net/zz_1111/article/details/79192167?utm_source=copy
他的实习导师http://blog.csdn.net/a15020059230/article/category/6961754