1、安装scrapy
pip3 install scrapy
2、打开terminal,cd 到想要创建程序的目录下
3、创建一个scrapy项目
在终端输入:scrapy startproject my_first_scrapy(项目名)
4、在终端输入:cd my_first_scrapy 进入到项目目录下
5、新建爬虫:
输入: scrapy genspider chouti chouti.com (chouti: 爬虫名称, chouti.com : 要爬取的网站的起始网址)
6、在pycharm中打开my_first_scrapy,就可以看到刚才创建的项目:

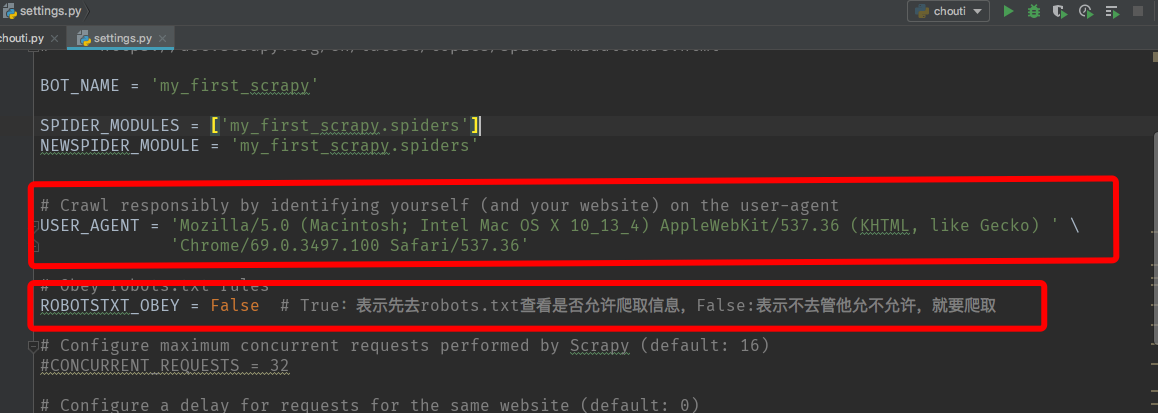
7、打开settings.py可以对项目相关参数进行设置,如设置userAgent:
扫描二维码关注公众号,回复:
3640642 查看本文章

8、打开chouti.py编写代码:


# -*- coding: utf-8 -*- """ 获取抽屉新热榜的标题和内容以及新闻地址保存到本地 """ import scrapy from scrapy.http.response.html import HtmlResponse class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] def parse(self, response): # print(response, type(response)) # <class 'scrapy.http.response.html.HtmlResponse'> # print(response.text) # 解析文本内容, 提取标题和简介,地址 # 去页面中找id=content-list的div标签,再去这个div下找class=item的div with open("news.txt", "a+", encoding="utf-8") as f: items = response.xpath("//div[@id='content-list']/div[@class='item']") # "//"表示从html文件的根部开始找。"/"表示从儿子里面找。".//"表示相对的,及当前目录下的儿子里面找 for item in items: # 当前目录下找class=part1的div标签,再找div标签下的a标签的文本信息text(),并且只取第一个 # a标签后面可以加索引,表示取第几个a标签,如第一个:a[0] title = item.xpath(".//div[@class='part1']/a/text()").extract_first().strip() # 去掉标题两端的空格 href = item.xpath(".//div[@class='part1']/a/@href").extract_first().strip() # 取href属性 summary = item.xpath(".//div[@class='area-summary']/span/text()").extract_first() # print(1, title) # print(2, href) # print(3, summary) f.write(title + "\n" + href + "\n" + summary + "\n" + "------------" + "\n")
9、在终端输入:
scrapy crawl chouti(会打印日志) 或者 scrapy crawl chouti --nolog (不打印日志)
运行爬虫项目。