1.Spark计算都转移到了一个节点上,即只有一个节点在计算。
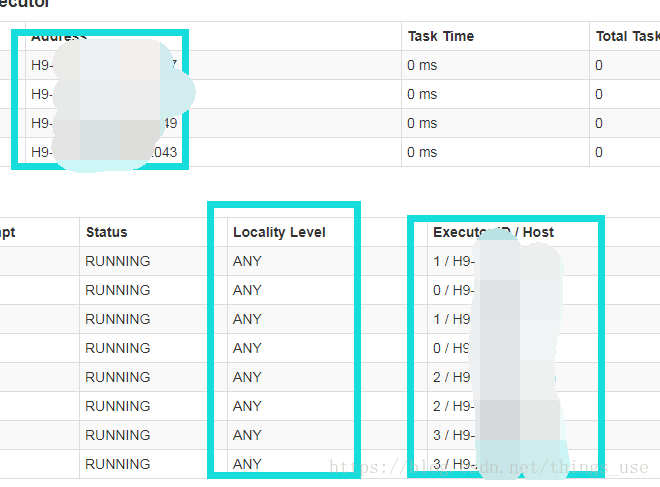
搭建好的spark集群,进行计算的时候发现,所有的slave节点上的task生成后,快速退出,并且生成好多task。查看spark ui上发现,只有主节点上有正常task运行,其他的slave节点都没有分到相应的task。如下所示:
主要是找到错误日志,主节点上的work目录下没有错误输出,然后找到slave节点下的work目录下,找到相应的app目录下,的staerr文件,发现slave节点一直在报错,是与主节点的netty通信异常,结合之前的经验,发现可能是jar包冲突。进入到spark的SPARK_CLASSPATH目录下,发现有两个netty相关的jar包。去掉一个之后,再运行,发现可以正常分发task了。
2.spark读取hbase数据,regionserver总是莫名其妙的挂掉,并出现以下异常:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /hbase/oldWALs/h2%2C16020%2C1536546484765..meta.1537221095269.meta (inode 4464431): File is not open for writing. Holder DFSClient_NONMAPREDUCE_-162643062_1 does not have any open files.
Detected pause in JVM or host machine (eg GC): pause of approximately 2511ms
网上有的说有下面解决方案:
# vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
hdfs-site.xml添加或者修改参数
dfs.datanode.max.xcievers值修改为8192(之前为4096)
还有这个:
清空HDFS上的.trash垃圾数据:hadoop fs –expunge
但是发现都不太适应这个问题,后来发现,是我在计算时, sparkMemory这个参数调的太大了(16G),导致gc时间太长,造成假死状态,调小就好了,regionserver也不挂了。
3.spark报链接zookeeper异常:
Initiating client connection, connectString=localhost:2181 sessionTimeout=90000
发现链接zk异常,配置文件也正常,为什么回去找本地zk?那是因为他没有找到要去哪里找zk,因为是hbase和spark交互,spark读取自己的conf目录下,并没有找到相应的zk地址,所以就默认本地zk,呢肯定是不对的。需要将hbase的hbase-site.xml文件复制到spark的conf目录下,然后spark回去读取这个文件,从而得到zk地址。