版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sinat_15153911/article/details/82942693
企业数据爬虫项目(艳辉VIP项目)
第一天:下载解析网站页面
以爬取某电影网上的电影信息为例,通过xpath,regex获取网页上的字段。通过三大sevice,下载网页service,解析网页service和数据存储service,全面爬取网站上的信息。
爬虫开始——>下载网页——>解析网页——>存数数据
三步走,分成三大service,例如存数数据,可以用jdbcService,也可以用hbaseService,这样方便扩展业务。
/**
* 开启一个爬虫入口
*/
public void startSpider(){
while(true){
//从队列中提取需要解析的url
String url = urlQueue.poll();
//判断url是否为空
if(StringUtils.isNotBlank(url)){
//下载
Page page = this.downloadPage(url);
//解析
this.processPage(page);
List<String> urlList = page.getUrlList();
for(String eachurl : urlList){
this.urlQueue.add(eachurl);
}
//if(page.getUrl().startsWith("http://list.youku.com/show_page")){
//存储数据
this.storePageInfo(page);
//}
}else{
System.out.println("url解析完毕!");
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
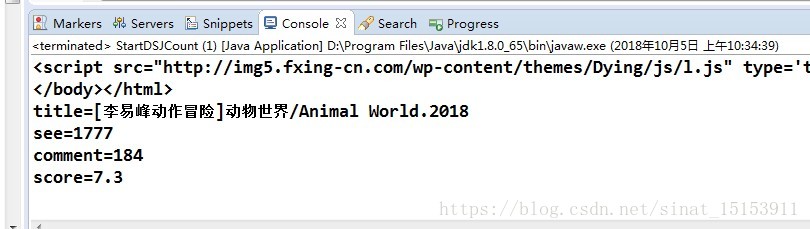
先爬取电影的标题,电影访问的次数,评论的人数,电影豆瓣的评分等信息。
String seeNum = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("seeXpath"),
LoadPropertyUtil.getYOUKU("seeRegex"));
page.setSeeNum(seeNum);
// 获取评论数
String commentNum = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("commentXpath"),
LoadPropertyUtil.getYOUKU("commentRegex"));
page.setCommentNum(commentNum);
// 获取豆瓣评分
String score = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("scoreXpath"),
LoadPropertyUtil.getYOUKU("scoreRegex"));
page.setScore(score);
String title = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("titleXpath"),
LoadPropertyUtil.getYOUKU("titleRegex"));
page.setTitle(title);
需要下载源码可点击 艳学网
下载源码后,记住分享哟!
第一步:微信关注公众号艳学网!
第二步:关注后打开菜单“艳辉福利”——“java福利”,转发文章至朋友圈。
长按自动识别二维码,即可关注微信公众号“艳学网”
