一、多job串联实例(倒索引排序)
1.需求
查询每个单词分别在每个文件中出现的个数
预期第一次输出(表示单词分别在个个文件中出现的次数)
apple--a.txt 3
apple--b.txt 1
apple--c.txt 1
grape--a.txt 4
grape--b.txt 3
grape--c.txt 1
pear--a.txt 1
pear--b.txt 2
pear--c.txt 2
预期第二次输出
apple a.txt 3 b.txt 1 c.txt 1
grape a.txt 4 b.txt 3 c.txt 1
pear a.txt 1 b.txt 2 c.txt 2
2.编写第一个Mapper代码
public class OneIndexMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
String name;
private Text k = new Text();
private IntWritable v = new IntWritable();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit)context.getInputSplit();
name = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//切割
String[] fields = line.split(" ");
for (String field : fields) {
//拼接
k.set(field+"--"+name);
//输出
context.write(k,v);
}
}
}3.编写第一个Reducer代码
public class OneIndexReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//汇总
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//输出
context.write(key, new IntWritable(sum));
}
}4.编写第一个Driver代码
public class OneIndexDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar包路径
job.setJarByClass(OneIndexDriver.class);
// 3 管理mapper和reducer类
job.setMapperClass(OneIndexMapper.class);
job.setReducerClass(OneIndexReducer.class);
// 4 设置mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}5.编写第二个Mapper代码
public class TwoIndexMapper extends Mapper<LongWritable,Text,Text,Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//切割
String[] fields = line.split("--");
k.set(fields[0]);
v.set(fields[1]);
//输出
context.write(k,v);
}
}6.编写第二个Reducer代码
public class TwoIndexReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//拼接
StringBuilder sb =new StringBuilder();
for (Text value : values) {
sb.append(value.toString().replace("\t","-->")+"\t");
}
//输出
context.write(key,new Text(sb.toString()));
}
}7.编写第二个Driver代码
public class TwoIndexDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar包路径
job.setJarByClass(TwoIndexDriver.class);
// 3 管理mapper和reducer类
job.setMapperClass(TwoIndexMapper.class);
job.setReducerClass(TwoIndexReducer.class);
// 4 设置mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}8.将第一个的输出路径作为第二个的输入路径
二、ReduceTask工作机制
1.设置ReduceTask并行度
ReduceTask的并行度同样影响整个job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的是个可以直接手动设置的
//默认值是1,手动设置为4
job.setNumReduceTasks(4);2.注意点
-
ReduceTask=0,表示没有Reduce阶段,输出文件个数和map个数一致
-
ReduceTask默认值是1,所以输出文件个数是一个
-
如果数据分布不均匀,可能在reduce阶段出现数据倾斜
-
ReduceTask数量并不是任意设置,还要考虑到业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能设置1个ReduceTask
-
具体的ReduceTask个数需要根据集群性能而定
-
如果分区数不是一个,但是ReduceTask为1,将不会执行分区过程。源码中在分区步骤之前判断了ReduceNum个数。
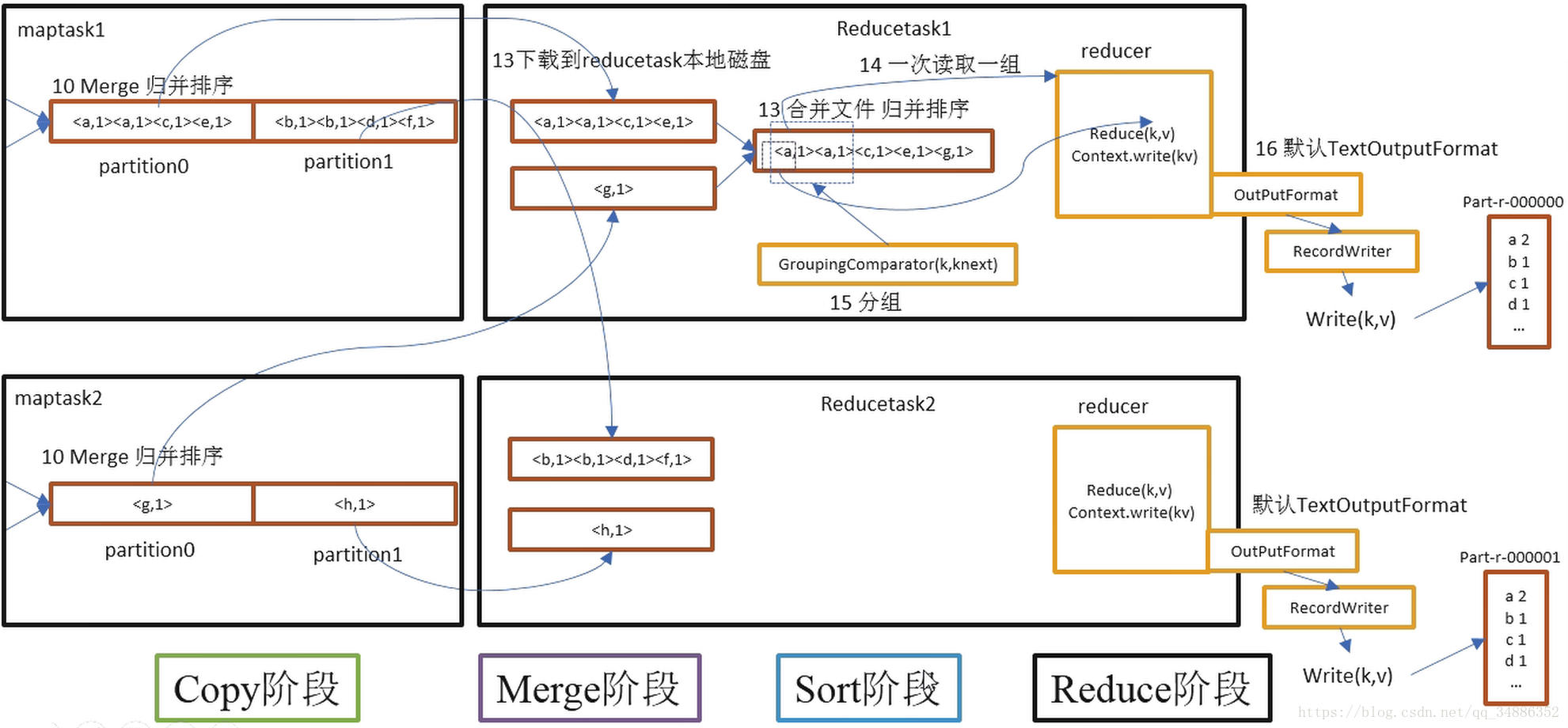
-
Copy阶段:ReduceTask从各中MapTask上远程拷贝一片数据,并针对某一片数据,如果其带下超过阈值,则写到磁盘上,否则放入内存。
-
Merge阶段:在远程拷贝数据的同时,ReduceTask启动两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上的文件过多。
-
Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚集在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现了对自己的处理结果进行了局部排序,因此,ReduceTask只需要对所有数据进行一次归并排序即可。
-
Reduce阶段:reduce()函数将计算结果写到HDFS上。