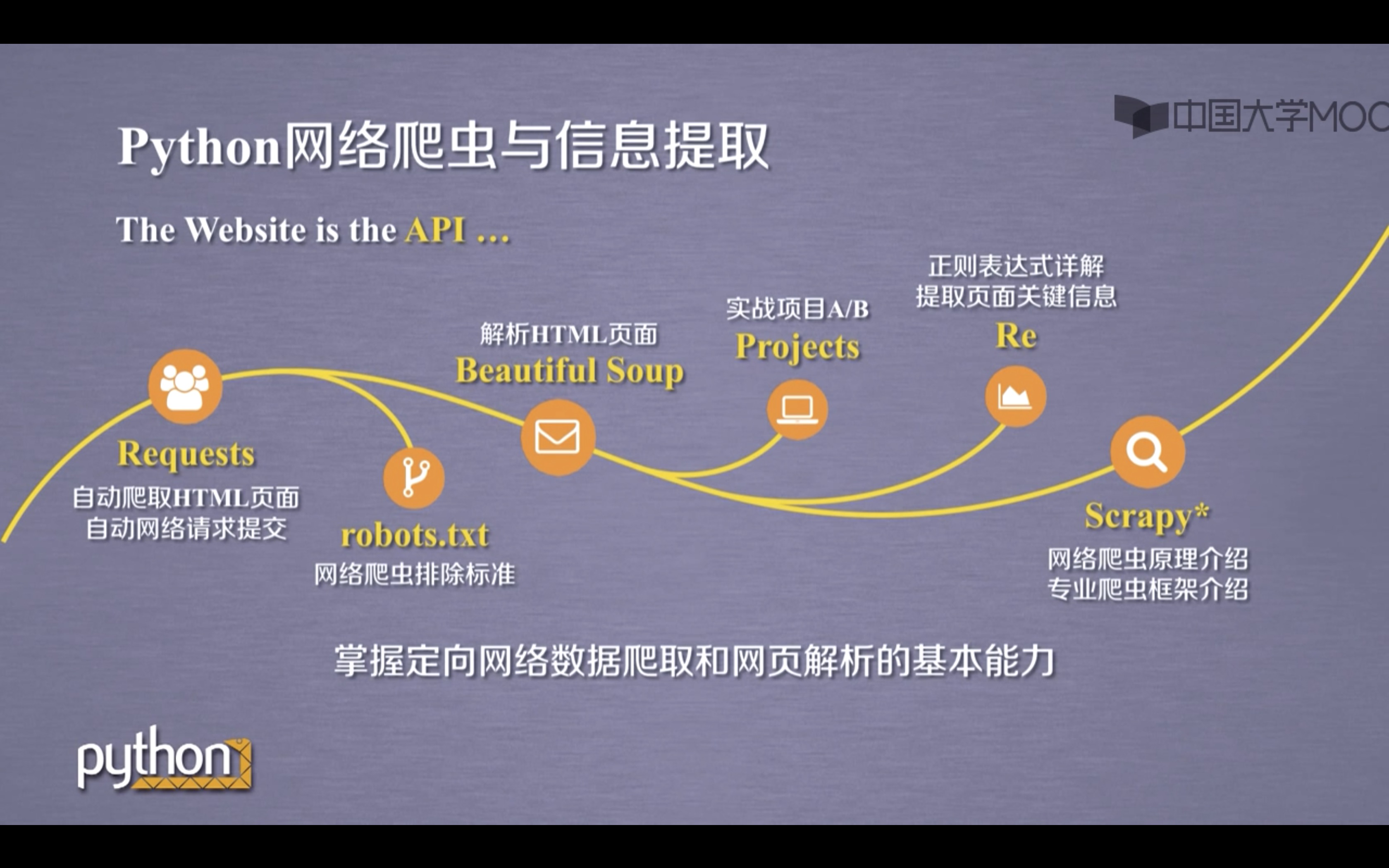
大概框架
Request库的安装
- 爬取网页最好用的第三方库
- 直接安装即可(用于OS X)
pip3 install requests - request库的常用方法:

- request库一共有七个常用方法。一个基本方法是request方法,其他的方法都是调用request方法实现的。
get方法
- 获取网页最简单的方法就是get方法
r = requests.get(url) - 通过get方法+url获得一个向服务器请求资源的Request对象。注意python是严格区分大小写的,这个Request和我们说的request是不同的。
- request.get()返回一个Response对象,就是我们的变量r。
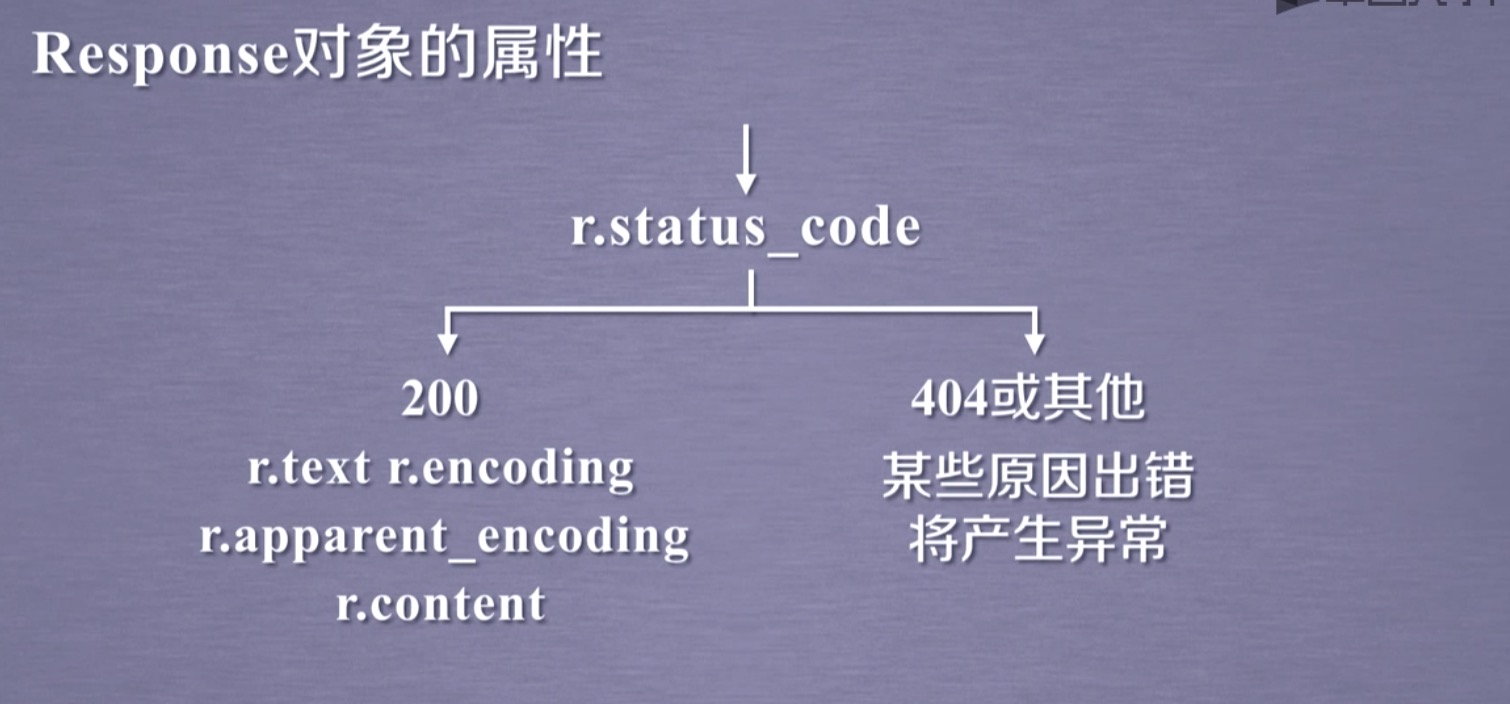
Response对象
看一段代码:

Response对象包含了服务器返回的所有信息。
- Response对象的属性:

- 一般的解析流程:
一个例子

- 状态编码为200,说明返回信息成功。
- 但是我们查看r的text属性时,却发现了乱码,于是我们去检查r的编码方式:
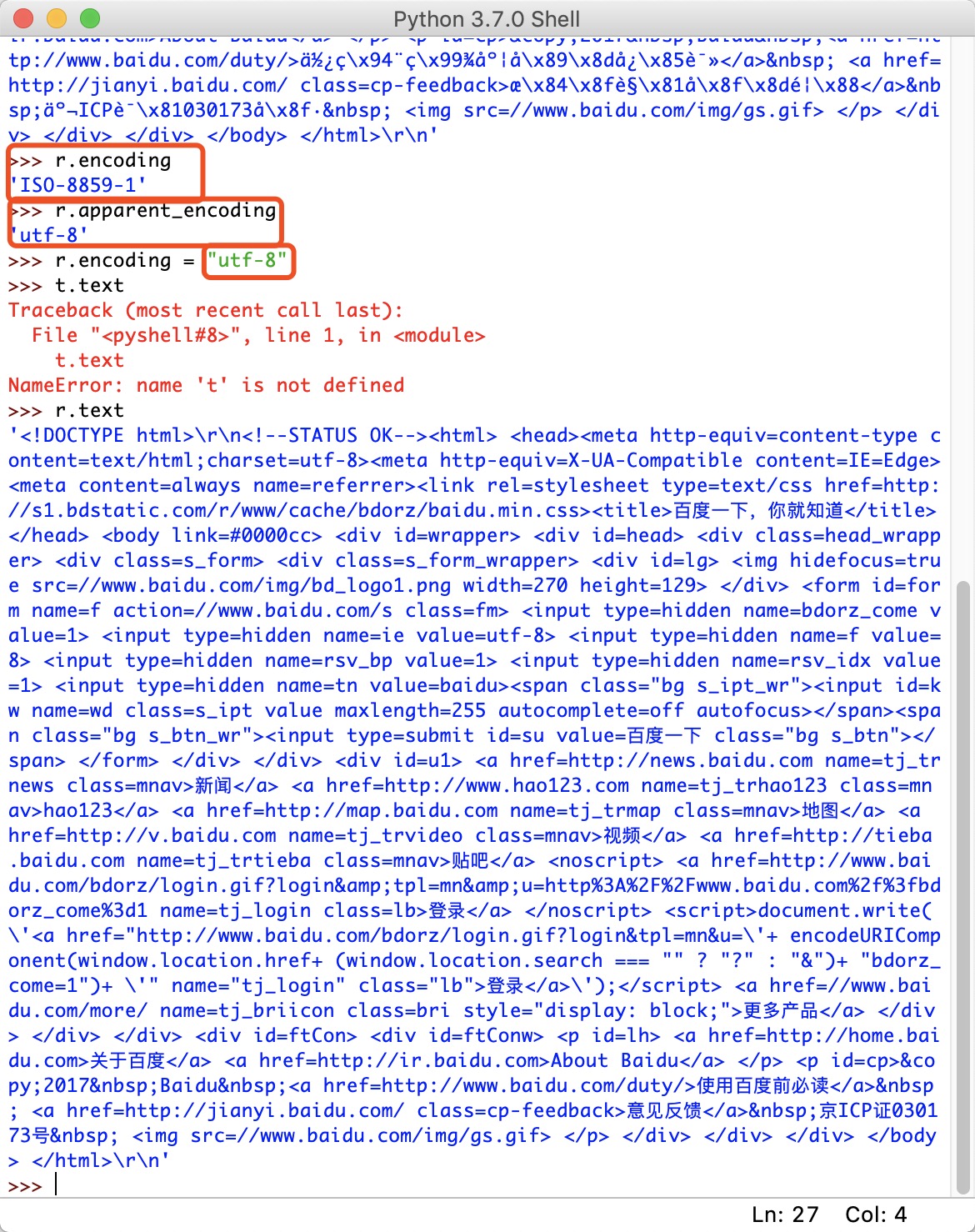
- 用r.apparent_encoding的utf-8编码替换r.encoding的ISO编码方式可以正常显示中文信息。这是为什么呢?

- r.encoding是从header中提取charset字段的编码方式,但是并非所有网站都有charset字段,如果没有charset字段时默认返回ISO-8859-1类型,而这个类型是不能解析中文的。
- r.apparent_encoding是根据http的内容部分实实在在分析内容的可能编码类型,更加准确!