在linux系统中,许多进程在诞生之初都与其父进程共同用一个存储空间。但是子进程又可以建立自己的存储空间,并与父进程“分道扬镳”,成为与父进程一样真正意义上的进程。
linux系统运行的第一个进程是在初始化阶段“捏造出来的”。而此后的线程或进程都是由一个已存在的进程像细胞分裂一样通过系统调用复制出来的,称为“fork()”或者“clone()”。
1.fork()
关于fork()和exec()的介绍在之前的一篇博文中做了介绍,
一个现有进程可以调用fork()函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。在不同的UNIX (Like)系统下,我们无法确定fork之后是子进程先运行还是父进程先运行,这依赖于系统的实现。所以在移植代码的时候我们不应该对此作出任何的假设。
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。因此fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。
调用fork之后,数据、堆栈有两份,代码仍然为一份但是这个代码段成为两个进程的共享代码段都从fork函数中返回,箭头表示各自的执行处。当父子进程有一个想要修改数据或者堆栈时,两个进程真正分裂。
fork函数的特点概括起来就是“调用一次,返回两次”,在父进程中调用一次,在父进程和子进程中各返回一次。
fork的另一个特性是所有由父进程打开的描述符都被复制到子进程中。父、子进程中相同编号的文件描述符在内核中指向同一个file结构体,也就是说,file结构体的引用计数要增加。

2.vfork()
vfork()会产生一个新的子进程。但是vfork创建的子进程与父进程共享数据段,而且由vfork创建的。子进程将先于父进程运行。
vfork()用法与fork()相似.但是也有区别,具体区别归结为以下几点:
1. fork():子进程拷贝父进程的数据段,代码段. vfork():子进程与父进程共享数据段.
2. fork():父子进程的执行次序不确定.
vfork():保证子进程先运行,在调用exec或exit之前与父进程数据是共享的,在它调用exec或exit之后父进程才可能被调度运行。
3. vfork()保证子进程先运行,在她调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
4.当需要改变共享数据段中变量的值,则拷贝父进程。
从这里可见,vfork()和fork()之间的一个区别是:vfork 保证子进程先运行,在她调用exec 或exit 之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
我们来看下面这段代码:
#include<sys/types.h> #include<unistd.h> #include<stdio.h> int main() { pid_t pid; int cnt = 0; pid = fork(); if(pid<0) printf("error in fork!\n"); else if(pid == 0) { cnt++; printf("cnt=%d\n",cnt); printf("I am the child process,ID is %d\n",getpid()); } else { cnt++; printf("cnt=%d\n",cnt); printf("I am the parent process,ID is %d\n",getpid()); } return 0; }
运行结果为:
cnt=1 I am the child process,ID is 5077 cnt=1 I am the parent process,ID is 5076
为什么不是2 呢?因为我们一次强调fork ()函数子进程拷贝父进程的数据段代码段,所以
cnt++; printf("cnt= %d\n",cnt); return 0
将被父子进程各执行一次,但是子进程执行时使自己的数据段里面的(这个数据段是从父进程那copy 过来的一模一样)count+1,同样父进程执行时使自己的数据段里面的count+1, 他们互不影响,与是便出现了如上的结果。
那么再来看看vfork ()吧。如果将上面程序中的fork ()改成vfork(),运行结果是什么 样子的呢?
cnt=1 I am the child process,ID is 4711 cnt=1 I am the parent process,ID is 4710 段错误
本来vfock()是共享数据段的,结果应该是2,为什么不是预想的2 呢?
上面程序中的fork ()改成vfork()后,vfork ()创建子进程并没有调用exec 或exit, 所以最终将导致死锁。
那么,对程序做下面的修改,
#include<sys/types.h> #include<unistd.h> #include<stdio.h> int main() { pid_t pid; int cnt = 0; pid = vfork(); if(pid<0) printf("error in fork!\n"); else if(pid == 0) { cnt++; printf("cnt=%d\n",cnt); printf("I am the child process,ID is %d\n",getpid()); _exit(0); } else { cnt++; printf("cnt=%d\n",cnt); printf("I am the parent process,ID is %d\n",getpid()); } return 0; }
如果没有_exit(0)的话,子进程没有调用exec 或exit,所以父进程是不可能执行的,在子进程调用exec 或exit 之后父进程才可能被调度运行。
所以我们加上_exit(0);使得子进程退出,父进程执行,这样else 后的语句就会被父进程执行,又因在子进程调用exec 或exit之前与父进程数据是共享的,所以子进程退出后把父进程的数据段count改成1 了,子进程退出后,父进程又执行,最终就将count变成了2。
运行结果:
cnt=1 I am the child process,ID is 4711 cnt=2 I am the parent process,ID is 4710
3.扩展
有这样一段代码:
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(void) { int var; var = 88; if ((pid = vfork()) < 0) { printf("vfork error"); exit(-1); } else if (pid == 0) { /* 子进程 */ var++; return 0; } printf("pid=%d, glob=%d, var=%d\n", getpid(), glob, var); return 0; }
上述代码一运行就挂掉了,但如果把子进程的return改成exit(0)就没事。这是为什么呢?
首先说一下fork和vfork的差别:
- fork 是 创建一个子进程,并把父进程的内存数据copy到子进程中。
- vfork是 创建一个子进程,并和父进程的内存数据share一起用。
这两个的差别是,一个是copy,一个是share。
你 man vfork 一下,你可以看到,vfork是这样的工作的,
1)保证子进程先执行。 2)当子进程调用exit()或exec()后,父进程往下执行。
那么,为什么要干出一个vfork这个玩意? 原因在man page也讲得很清楚了:
Historic Description
Under Linux, fork(2) is implemented using copy-on-write pages, so the only penalty incurred by fork(2) is the time and memory required to duplicate the parent’s page tables, and to create a unique task structure for the child. However, in the bad old days a fork(2) would require making a complete copy of the caller’s data space, often needlessly, since usually immediately afterwards an exec(3) is done. Thus, for greater efficiency, BSD introduced the vfork() system call, which did not fully copy the address space of the parent process, but borrowed the parent’s memory and thread of control until a call to execve(2) or an exit occurred. The parent process was suspended while the child was using its resources. The use of vfork() was tricky: for example, not modifying data in the parent process depended on knowing which variables are held in a register.
意思是这样的—— 起初只有fork,但是很多程序在fork一个子进程后就exec一个外部程序,于是fork需要copy父进程的数据这个动作就变得毫无意了,这样干显得很重(因为拷贝了所有内容)。
所以,BSD搞出了个父子进程共享的 vfork,这样成本比较低。因此,vfork本就是为了exec而生。
为什么return会挂掉,exit()不会?
从上面我们知道,结束子进程的调用是exit()而不是return,如果你在vfork中return了,那么,这就意味main()函数return了,注意因为函数栈父子进程共享,所以整个程序的栈就跪了。
如果你在子进程中return,那么基本是下面的过程:
1)子进程的main() 函数 return了,于是程序的函数栈发生了变化。
2)而main()函数return后,通常会调用 exit()或相似的函数(如:_exit(),exitgroup())
3)这时,父进程收到子进程exit(),开始从vfork返回,但是父进程的栈都被子进程给return干废掉了,父进程无法执行
(注:栈会返回一个诡异一个栈地址,对于某些内核版本的实现,直接报“栈错误”就给跪了,然而,对于某些内核版本的实现,于是有可能会再次调用main(),于是进入了一个无限循环的结果,直到vfork 调用返回 error)
好了,现在再回到 return 和 exit,return会释放局部变量,并弹栈,回到上级函数执行。exit直接退掉。如果你用c++ 你就知道,return会调用局部对象的析构函数,exit不会。(注:exit不是系统调用,是glibc对系统调用 _exit()或_exitgroup()的封装)
可见,子进程调用exit() 没有修改函数栈,所以,父进程得以顺利执行。
关于fork的优化
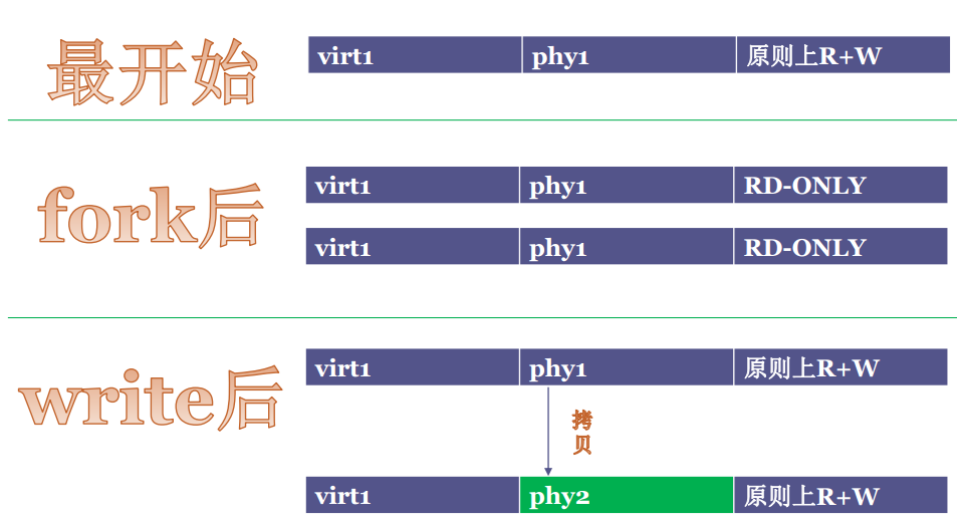
很明显,fork太重,而vfork又太危险,所以,就有人开始优化fork这个系统调用。优化的技术用到了著名的写时拷贝(COW)。
也就是说,对于fork后并不是马上拷贝内存,而是只有你在需要改变的时候,才会从父进程中拷贝到子进程中,这样fork后立马执行exec的成本就非常小了。所以,Linux的Man Page中并不鼓励使用vfork() ——
“ It is rather unfortunate that Linux revived this specter from the past. The BSD man page states: “This system call will be eliminated when proper system sharing mechanisms are implemented. Users should not depend on the memory sharing semantics of vfork() as it will, in that case, be made synonymous to fork(2).””
于是,从BSD4.4开始,他们让vfork和fork变成一样的了
但在后来,NetBSD 1.3 又把传统的vfork给捡了回来,说是vfork的性能在 Pentium Pro 200MHz 的机器(这机器好古董啊)上有可以提高几秒钟的性能。详情见——“NetBSD Documentation: Why implement traditional vfork()”
今天的Linux下,fork和vfork还是各是各的,不过,还是建议你不要用vfork,除非你非常关注性能。
4.图说
在最后,放两张fork()和vfork()的图,我们自己体会。。。
fork():
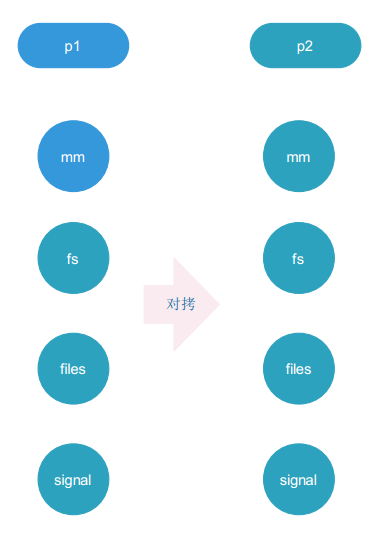
vfork():
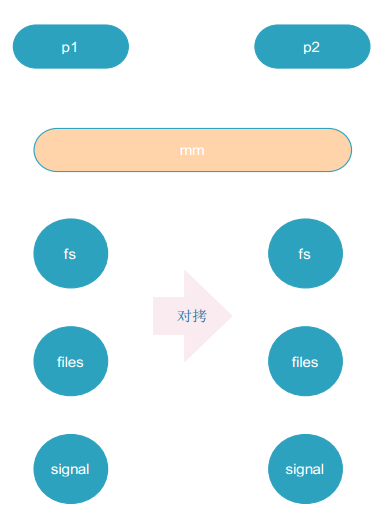
写时拷贝:
参考:
https://www.cnblogs.com/lovemdx/p/3308057.html
https://www.cnblogs.com/1932238825qq/p/7373443.html