大数据学习——平台环境部署(详细)
本文利用云服务器对大数据平台进行环境部署,包含:服务使用、环境准备、Hadoop集群完全分布式安装、Zookeeper集群完全分布式安装、HBase完全分布式安装、Hive、Scala、Spark、Sqoop、Flume的安装。如有错误还望指出。
目录
-
一、服务器使用
阿里云服务器,百度云服务器,腾讯云服务器。学生购买会有优惠,但只限一台机器。我用的学生优惠分别在三个平台各买了一台云主机来搭建大数据环境。
1、阿里云(centos7.3)
47.101.62.158公
172.19.46.110私
2、百度云(centos7.3)
180.76.96.39 公
192.168.0.4私
3、腾讯云(centos7.3)
132.232.131.91 公
172.27.0.13 私
4、安全组ssh端口开放
使用服务器这里是关键。服务器如果在各网页界面去操作会效率很低,用Xshell或者putty可以远程连接服务器进行操作。这样就需要设置各服务器安全组打开ssh的22端口,然后进行远程连接。
-
二、环境准备
OS:CentOS 7.0+
远程连接:Xshell
| 序号 |
主机 |
IP |
主机名 |
用户名 |
密码 |
| 1 |
Baidu Cloud |
180.76.96.39 公 192.168.0.4 私 |
Hadoop2 |
root |
*** |
| 2 |
Alibaba Cloud |
47.101.62.158 公 172.19.46.110 私 |
Hadoop1 |
root |
*** |
| 3 |
Tencent Cloud |
132.232.131.91 公 172.27.0.13 私 |
Hadoop3 |
root |
*** |
Package:
http://www.apache.org/(Apache官网)
https://mirrors.tuna.tsinghua.edu.cn/apache/
Hadoop集群安装(伪|全)
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
JDK安装
MySQL安装
如果用wget命令下载会出问题:博客:https://blog.csdn.net/weixin_42039699/article/details/82936624
https://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.41-linux-glibc2.12-x86_64.tar.gz
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
Pig安装
https://mirrors.tuna.tsinghua.edu.cn/apache/pig/pig-0.17.0/pig-0.17.0.tar.gz
Hive安装
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/stable-2/apache-hive-2.3.3-bin.tar.gz
HBase安装
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.2.7/hbase-1.2.7-bin.tar.gz
Zookeeper集群安装
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
Sqoop安装
https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
Spark安装
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
Flume安装
https://mirrors.tuna.tsinghua.edu.cn/apache/flume/stable/apache-flume-1.8.0-bin.tar.gz
Storm安装
https://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.2.2/apache-storm-1.2.2.tar.gz
-
三、Hadoop3.1.1 集群环境安装
设备:
实验设备包括 3 台服务器(CentOS7.0+)
实验所需安装包
步骤:
1.基础环境准备
1.1 集群规划
| 序号 |
主机 |
IP |
主机名 |
用户名 |
密码 |
| 1 |
Baidu Cloud |
180.76.96.39 公 192.168.0.4 私 |
Hadoop2 |
root |
*** |
| 2 |
Alibaba Cloud |
47.101.62.158 公 172.19.46.110 私 |
Hadoop1 |
root |
*** |
| 3 |
Tencent Cloud |
132.232.131.91 公 172.27.0.13 私 |
Hadoop3 |
root |
*** |
1.2 系统准备
3台服务器(CentOS7.0+)
软件安装包存放于tgz目录下:

1.3 网络配置(虚拟机配置,云服务器跳过)
为每个 Hadoop 主机配置相应的 IP 地址,每台的操作方法相同。IP 地址根据
实验环境进行配置,如果实验环境使用的是动态 IP 地址则可以跳过网络配置部分,进入下一步操作。
1.3.1 修改网络配置文件
1、首先,确保在 root 用户下进行操作。通过 vi 命令修改网络配置文件
[root@localhost ~]#
vi /etc/sysconfig/network-scripts/ifcfg-eth0
2、然后按 i 键进入编辑模式,我们需要将其中的 BOOTPROTO=dhcp 改为BOOTPROTO=static 意思是设置为静态 IP,将 ONBOOT=no 改为 ONBOOT=yes 意思是将网卡设置 为开机启用,同时在文字下方添加如下内容:
IPADDR= #静态 IP
GATEWAY= #默认网关
NETMASK= #子网掩码
DNS1= #DNS 配置
3、修改完成以后按 Esc 键退出编辑模式,按 Shift + : 输入 wq 进行保存并退出!修改好的配置截图。
1.3.2 重启网络服务
通过 service network restart 重启网络服务,使修改的配置生效
[root@localhost ~]# service network restart
1.3.3 查看配置是否修改成功
通过 ifconfig 命令来查看当前的 IP 地址信息
通过上面的操作以后分别将三台 hadoop 主机的配置改为 :
hadoop1 IP,hadoop2 IP,hadoop3 IP
1.4 关闭防火墙
三台 hadoop 主机都需要操作关闭防火墙
1、首先,输入 service iptables stop 命令停止防火墙的运行,再通过输入
chkconfig iptables off 命令关闭防火墙开机运行
2、执行命令如下:
[root@localhost ~]# service iptables stop
[root@localhost ~]# chkconfig iptables off
查看防火墙状态:
[root@localhost ~]# service iptables status
iptables: Firewall is not running.
注意:
CentOS 7.0+默认使用的是firewall作为防火墙
关闭并禁止firewall开机启动:
停止
systemctl stop firewalld.service
禁止开机启动
systemctl disable firewalld.service
启动/重启Firewalld
#systemctl start firewalld.service
#systemctl restart firewalld.service
开机启动/关闭开机启动
#systemctl enable firewalld.service
#systemctl disable firewalld.service
查看状态
#firewall-cmd --state
开放端口:云主机开放全部端口比较危险,容易被挖矿程序占CPU,建议需要什么端口打开什么。
firewall-cmd --permanent --zone=public --add-port=10-50010/tcp
firewall-cmd --permanent --zone=public --add-port=10-50010/udp
firewall-cmd --reloa
1.5 修改主机名称
修改主机名称目的是为了方便管理,将第一台 hadoop 主机的名称改为 hadoop1,
第二台改为 hadoop2,第三台改为 hadoop3。在三台 hadoop 主机上按下面的方法
修改每台的主机名称
1、首先,确保在 root 用户下进行操作。[root@localhost ~]# vi /etc/sysconfig/network
2、然后按 i 键进入编辑模式,将 HOSTNAME=localhost 改为 HOSTNAME=hadoop1
也就是将该机器名称改为 hadoop1。修改完成后需要输入 reboot 命令重启生效
重启命令:
[root@localhost ~]# reboot
查看当前主机名命令:
[root@localhost ~]# hostname
1.6 修改 hosts 文件
每台 hadoop 主机都加入相同的 hosts 主机记录
1、打开 hosts 文件
[root@hadoop1 ~]# vim /etc/hosts
2、在第三行添加下面的参数
IP hadoop1
IP hadoop2
IP hadoop3
云服务器搭建Hadoop完全分布式hosts配置关键:
在Master服务器上,要将自己的ip设置成内网ip,而将另一台Slave服务器的ip设置成外网ip
同样的在Slave服务器上,要将自己的ip设置成内网ip,而降另一台Master服务器的ip设置成外网ip
1.7时钟同步命令
ntpdate cn.pool.ntp.org
1.8 配置 SSH 免密码登录
hadoop 在执行配置过程中,master 需要对 salves 进行操作,所以我们需要在 hadoop1 节点配置 ssh 免密码登录 hadoop2、hadoop3.在 hadoop1 主机上执行以下的命令:
1、进入 root 管理员目录,执行 ssh-keygen -t rsa 一直回车生成密钥
[root@hadoop1 ~]# cd ~
[root@hadoop1 ~]# ssh-keygen -t rsa
2、进入 ~/.ssh 目录,将生成好的密钥同步到 hadoop2 和 hadoop3 中,在执行
ssh-copy-id 命令后需要输入对应 hadoop 主机的密码
[root@hadoop1 ~]# cd ~/.ssh
[root@hadoop1 .ssh]# ssh-copy-id hadoop2
[root@hadoop1 .ssh]# ssh-copy-id hadoop3
3、执行
[root@hadoop1 .ssh]# cat ~/.ssh/id_rsa.pub >~/.ssh/authorized_keys
4、验证 SSH 免密码登录是否成功
在 hadoop1 主机上可以不用输入密码即可远程访问 hadoop2 和 hadoop3,验证可以连接以后记得使用 exit 命令退出 ssh 连接
验证免密码登录 hadoop2:
[root@hadoop1 .ssh]# ssh hadoop2
退出 hadoop2 连接:
[root@hadoop2 ~]# exit
验证免密码登录 hadoop3:
[root@hadoop1 .ssh]# ssh hadoop3
[root@hadoop2 ~]# exit
退出 hadoop3 连接:
[root@hadoop3 ~]# exit
免密方式2:
hadoop1上执行:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh-add ~/.ssh/id_dsa
scp ~/.ssh/authorized_keys hadoop2
scp ~/.ssh/authorized_keys hadoop3
ssh-copy-id hadoop2
ssh-copy-id hadoop3
ssh hadoop2
ssh hadoop3
遇到问题:
重装openssh
1. 卸载
先查看openssh的相关包rpm -qa openssh*
然后依次卸载
安装 yum install -y
yum install -y openssh-7.4p1-16.el7.x86_64;yum install -y openssh-clients-7.4p1-16.el7.x86_64;yum install -y openssh-server-7.4p1-16.el7.x86_64
然后重新启动ssh服务
systemctl start sshd.service
通过ssh-keygen -t rsa和ssh-copy-id -i 操作后,免密登录依然需要输入密码问题解决:
目录文件的权限
.ssh父目录的权限是755,.ssh目录权限是700,authorized_keys文件 600

还是有问题。
目录的属主
如果上面方法还没有解决问题,那可能是.ssh父目录的属主存在问题。
这里发现.ssh父目录(..)的属主存在问题。
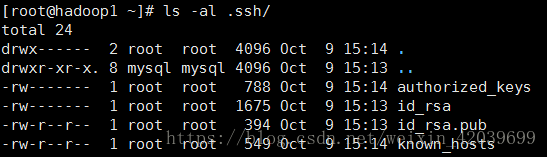
解决方法:
chown root:root /root
1.9 安装 JDK 环境

用wget命令直接下载的JDK,这是问题的根源。 去Oracle官网下载过jdk,下载之前需要同意Oracle的安装协议,不然不能下载,但是用wget的方式,默认是不同意,虽然能下载下来,但是下载下来的文件会有问题,所以在Linux上解压一直失败。去官网下载好,然后传到服务器上,再解压就没有问题了。
使用Xshell本地传送JDK到服务器上:
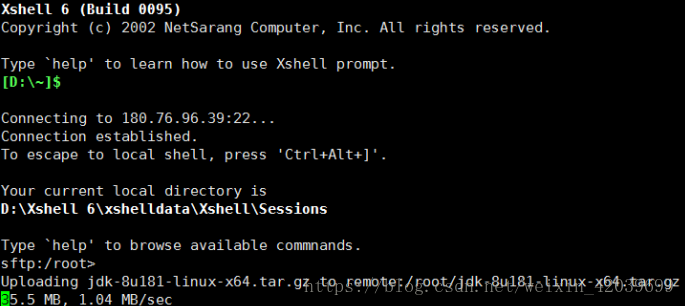
三台 hadoop 主机都需要按照下面步骤安装 JDK 环境
注:安装所需要的软件都在tgz目录下
1、首先执行 java -version 查看 jdk 是否已经安装,如果看到以下内容则表示
已经安装了则可以跳过这一步骤,进入环境部署环节,另外如果版本低于 java version "1.8.0_181"则需要升级到对应版本
[root@hadoop1]# java -version
2、进入软件包位置,将 jdk 安装包复制到/usr/lib/
[root@hadoop1 ~]# cd ~/tgz/
[root@hadoop1 tgz]# cp jdk-8u181-linux-x64.tar.gz /usr/lib
3、进入/usr/lib 目录并解压 jdk-8u181-linux-x64.tar.gz
[root@hadoop1 tgz]# cd /usr/lib
[root@hadoop1 lib]# tar -zxvf jdk-8u181-linux-x64.tar.gz
4、修改环境变量
[root@hadoop1 lib]# vim /etc/profile
添加以下内容:
export JAVA_HOME=/usr/lib/jdk1.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
5、更新环境变量
[root@hadoop1 lib]# source /etc/profile
6、执行 java -version 查看是否安装或者更新成功
[root@hadoop1]# java -version

2.hadoop集群环境部署
注:安装所需要的软件都在tgz目录下
2.1 安装 hadoop3.1.1
我们通过在hadoop1进行安装hadoop,然后配置相应的配置文件,最后将hadooop所有文件同步到其它 hadooop 节点(hadoop2、hadoop3)。Hadoop 路径配置为/opt/hadoop-3.1.1
在 hadoop1 执行以下操作:
1、 首先进入软件包目录
[root@localhost ~]# cd /opt/tgz/
2、通过 cp 命令将 hadoop 安装包(hadoop-3.1.1.tar.gz)复制到/opt 目录下
[root@localhost tgz]# cp hadoop-3.1.1.tar.gz /opt/
3、 进入/opt 目录,并解压 hadoop-3.1.1.tar.gz 压缩包
[root@localhost tgz]# cd /opt/
[root@localhost opt]# tar -zxvf hadoop-3.1.1.tar.gz
2.2 配置 hadoop 配置文件
2.2.1 修改 core-site.xml 配置文件
通过 vi 命令修改 core-site.xml 配置文件,在 <configuration>
</configuration>中间添加以下命令,fs.defaultFS 是用来定义 HDFS 的默认名
称节点路径。就是我们将来访问 HDFS 文件时,如果没有指定路径,就会联系这
里定义的路径的主机,去联系这台主机去寻找其路径。
1、打开 core-site.xml 配置文件命令:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/core-site.xml
2、添加内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.1/tmp</value>
</property>
2.2.2 修改 hdfs-site.xml 配置文件
通过 vi 命令修改 hdfs-site.xml 配置文件,在 <configuration>
</configuration>中间添加第 2 步的内容
1、打开 hdfs-site.xml 配置文件:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
2、添加内容:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9001</value>
</property>
2.2.3 修改 workers 配置文件
通过 vi 命令修改 workers 配置文件,将第一行的localhost改成hadoop1,并在第二行中加入 hadoop2 和 hadoop3
1、打开 workers 配置文件
[root@hadoop1]# vim /opt/hadoop-3.1.0/etc/hadoop/workers
2、添加内容
hadoop1
hadoop2
hadoop3
2.2.4 修改 mapred-site.xml 配置文件
通过 vi 命令修改 mapred-site.xml 配置文件,在 <configuration>
</configuration>中间添加第 2 步的内容
1、打开 mapred-site.xml 配置文件命令:
[root@hadoop1]# vim /opt/hadoop-3.1.0/etc/hadoop/mapred-site.xml
2、添加内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/hadoop-3.1.1/etc/hadoop,
/opt/hadoop-3.1.1/share/hadoop/common/*,
/opt/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/hadoop-3.1.1/share/hadoop/hdfs/*,
/opt/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.1.1/share/hadoop/mapreduce/*,
/opt/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.1.1/share/hadoop/yarn/*,
/opt/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
2.2.5 修改 yarn-site.xml 配置文件
通过 vi 命令修改 yarn-site.xml 配置文件,在 <configuration>
</configuration>中间添加第 2 步的内容
1、打开 yarn-site.xml 配置文件命令:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/yarn-site.xml
2、添加内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
取消yarn运行模式的运行内存检测,这样就算内存达不到要求也不会kill掉任务
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.2.6 修改 hadoop-env.sh 配置文件
通过 vi 命令修改 hadoop-env.sh 配置文件,在第二行中添加第 2 步的内容
1、打开 hadoop-env.sh 配置文件命令:
[root@hadoop1]# vim /opt/hadoop-3.1.1/etc/hadoop/hadoop-env.sh
2、添加内容
export JAVA_HOME=/usr/lib/jdk1.8
4、更新配置文件
[root@hadoop1 ~]# source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
2.2.7 修改 start-dfs.sh 和 stop-dfs.sh 配置文件
1、打开 start-dfs.sh 配置文件,在第二行中添加以下命令
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/start-dfs.sh
添加内容:
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2、打开 stop-dfs.sh 配置文件,在第二行中添加以下命令
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/stop-dfs.sh
添加内容:
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.2.8 修改 start-yarn.sh 和 stop-yarn.sh 配置文件
1、打开 start-yarn.sh 配置文件,在第二行中添加以下命令
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/start-yarn.sh
添加内容:
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
2、打开 stop-yarn.sh 配置文件,在第二行中添加以下命令
[root@localhost ~]# vi /opt/hadoop-3.1.1/sbin/stop-yarn.sh
添加内容:
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
2.2.9 取消打印警告信息
由于系统预装的 glibc 库时 2.12 版本,而 hadoop3.1.0 期待的是 2.14 版本,所
以后期启动服务的时候会打印报警信息,我们可以配置取消打印警告信息
1、打开 log4j.properties 配置文件,在首行中添加第 2 步的内容
[root@hadoop1 ~]# vim /opt/hadoop-3.1.1/etc/hadoop/log4j.properties
2、添加内容
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
2.2.10 同步 hadoop1 配置到 hadoop2 和 hadoop3 中
1、同步已经配置好的 hadoop 文件到 hadoop2 上
[root@hadoop1 ~]# cd /opt/
[root@hadoop1 opt]# scp -r hadoop-3.1.1root@hadoop2:/opt/
2、同步已经配置好的 hadoop 文件到 hadoop3 上
[root@hadoop1 ~]# cd /opt/
[root@hadoop1 opt]# scp -r hadoop-3.1.0 root@hadoop3:/opt/
2.2.11 配置三台 hadoop 主机的 profile 文件
1、打开 profile 文件,在最后面添加第 2 步的参数内容
[root@hadoop1 ~]# vim /etc/profile
2、添加内容
#SET HADOOP
HADOOP_HOME=/opt/hadoop-3.1.1
PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_HOME PATH
4、更新环境变量
[root@localhost ~]# source /etc/profile
[root@localhost ~]# source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
2.3 格式化 HDFS 文件系统
在 hadoop1 上通过 hdfs namenode -format 命令来格式化 HDFS 文件系统
[root@hadoop1 ~]# hdfs namenode -format
表示格式化 HDFS 文件系统完成
3.启动集群
3.1 启动集群
1、启动 hadoop 集群验证是否能正常启动,进入到/opt/hadoop-3.1.1/sbin/目
录下通过./start-all.sh 命令执行启动
[root@hadoop1 ~]# cd /opt/hadoop-3.1.1/sbin/
[root@hadoop1 sbin]# ./start-all.sh
2、在各 hadoop 节点上执行 jps 命令查看 hadoop 进程
[root@hadoop1 ~]# jps
3、通过 web 访问 HDFS 文件系统和 yarn
可以通过以下链接访问 hdfs 和 yarn
公网ip:8088或ip:9870
http://47.101.62.158:8088/cluster
-
四、Zookeeper 集群安装部署
步骤:
1.基础环境准备
2.环境部署
2.1 安装 zookeeper3.4.10
2.1.1 首先进入软件包目录
[root@hadoop1 ~]# cd tgz/
2.1.2 把 zookeeper 安装包(zookeeper-3.4.10.tar.gz)解压到/opt 目录下
[root@hadoop1 tgz]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/
2.1.3 解压完成后在环境变量中添加 Zookeeper 的安装路径,更新配置文件,使变量生效。
[root@hadoop1 tgz]# vi /etc/profile
添加以下内容:
#SET ZOOKEEPER
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
退出后执行 source /etc/profile 命令更新环境变量
[root@hadoop1 opt]# source /etc/profile
2.2 配置 zookeeper 配置文件
1、进入 zookeeper 配置文件目录:
[root@hadoop1]# cd /opt/zookeeper-3.4.10/conf
2、复制 zoo_sample.cfg 文件为 zoo.cfg
[root@hadoop1]# cp zoo_sample.cfg zoo.cfg
3、创建存放数据的文件夹:
[root@hadoop1 conf]# mkdir /opt/zookeeper-3.4.10/data
4、创建 myid 文件,并加入数字 0 (主节点为 0,从节点分别为 1,2)
[root@hadoop1 conf]# vi /opt/zookeeper-3.4.10/data/myid
5、修改 zoo.cfg 配置文件
[root@hadoop1 conf]# vi /opt/zookeeper-3.4.10/conf/zoo.cfg
将配置文件中 dataDir 的路径改为/opt/zookeeper-3.4.10/data
并在底部中加入以下参数:
server.0=hadoop1:2888:3888
server.1=hadoop2:2888:3888
server.2=hadoop3:2888:3888
zoo.cfg 各语句的含义
tickTime:服务器与客户端之间交互的基本时间单元(ms)
initLimit:允许 follower 连接并同步到 leader 的初始化时间,它以 tickTime
的倍数来表示。当超过设置倍数的 tickTime 时间,则连接失败
syncLimit:Leader 服务器与 follower 服务器之间信息同步允许的最大时间间
隔,如果超过次间隔,默认 follower 服务器与 leader 服务器之间断开链接
dataDir:保存 zookeeper 数据路径
clientPort:客户端访问 zookeeper 时经过服务器端时的端口号
2.2.2 文件同步
1、将 hadoop1 上配置好的 zookeeper 文件同步到 haoop2、hadoop3 节点上:
[root@hadoop1]# scp -r /opt/zookeeper-3.4.10/ root@hadoop2:/opt
[root@hadoop1]# scp -r /opt/zookeeper-3.4.10/ root@hadoop3:/opt
2、将 hadoop1 的环境变量同步到 haoop2、hadoop3 节点上::
[root@hadoop1]# scp -r /etc/profile/ root@hadoop2:/etc/profile
[root@hadoop1]# scp -r /etc/profile/ root@hadoop3:/etc/profile
3、在其它节点上使环境生效:
[root@hadoop2]# source /etc/profile
[root@hadoop3]# source /etc/profile
4、修改 hadoop2 和 hadoop3 上的 myid
在 hadoop2 上将 myid 修改为 1
命令如下:
[root@hadoop2]# vi /opt/zookeeper-3.4.10/data/myid
hadoop1 下的 myid:
hadoop2 下的 myid
hadoop3 下的 myid
启动 zookeeper 集群并测试
3.1 启动 zookeeper
1、分别启动 hadoop1、hadoop2、hadoop3 节点的 zookeeper 集群命令
[root@hadoop1]# zkServer.sh start
[root@hadoop2]# zkServer.sh start
[root@hadoop3]# zkServer.sh start
2、查看是否启动成功命令:
[root@hadoop1]# zkServer.sh status
问题:
1.执行zkServer.sh start 后显示:
JMX enabled by default
Using config:/home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.jps后发现没有QuorumPeerMain进程
3.查看zookeeper-3.4.5/data下的zookeeper-3.4.5.out,如果提示 binding to port 0.0.0.0/0.0.0.0:2181
ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally java.net.BindException: Address already in use
说明2181端口被占用,通过netstat -nltp | grep 2181检查是否已被占用,如果有则把对应的进程kill掉(kill 进程的pid),然后再启动zookeeper
4..jps后发现有QuorumPeerMain进程,然后执行zkServer.sh status,如果显示:
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
说明未启动成功,通过查看zookeeper-3.4.5.out,如果提示
Cannot open channel to 1 at election address hadoop05/10.37.129.105:3888
java.net.NoRouteToHostException: No route to host,说明无法连接远程电脑10.37.129.105:3888,很有可能开启了防火墙
通过sudo service iptables status检查,如果确实开启,则通过sudo service iptables stop将其关闭,最后再查看状态zkServer.sh status
此时,基本都能够正常启动了,提示:
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader(或follower)
#查看端口有没有被占用
netstat -ntpl | grep 端口号
Top查看进程
Kill -9 进程
-
五、Hbase 完全分布式安装
步骤:
1.1 解压安装包 hbase
1.1.1 首先进入软件包目录
[root@hadoop ~]# cd tgz/
1.1.2 解压安装压缩包 将 hbase 安装包(hbase-1.2.7-bin.tar.gz)解压缩到 /opt 目录下
[root@hadoop tgz]# tar -zxvf hbase-1.2.7-bin.tar.gz -C /opt
1.1.3 进入到/opt 目录
[root@hadoop ~]# cd /opt
1.1.4 将解压的安装包重命名
[root@hadoop ~]# mv hbase-1.2.7 /opt/hbase
1.1.5 配置环境变量 加入 hbase 的安装路径
[root@hadoop conf]# vi /etc/profile
在文件的最底部加入下面内容
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
配置如图:
退出后执行 source /etc/profile 命令更新环境变量
[root@hadoop conf]# source /etc/profile
1.2:搭建 Hbase 伪分布模式
hadoop1
NameNode
DataNode
NodeManager
ResourceManager
SecondaryNameNode
HMaster
QuorumPeerMain
HRegionServer
1.2.1 按照上述 1.1 解压缩后进入到配置文件 conf 目录
[root@hadoop opt]# cd /opt/hbase/conf/
1.2.2 编辑 hbase-site.xml
[root@hadoop conf]# vi hbase-site.xml
添加内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
配置参数说明:
hbase.rootdir:该参数制定了 HReion 服务器的位置,即数据存放的位置。主要端口
号要和 Hadoop 相应配置一致。
hbase.cluster.distributed:HBase 的运行模式。false 是单机模式,true 是分布式模式。
若为 false, HBase 和 Zookeeper 会运行在同一个 JVM 里面。默认为 false。
1.2.3 编辑 hbase-env.sh 设置 JAVA_HOME
[root@hadoop conf]# vi hbase-env.sh
修改 export JAVA_HOME=/usr/lib/jdk1.8/
修改后如下:
1.2.4 启动 hbase
进入到 hbase 的 bin 目录
[root@hadoop conf]# cd /opt/hbase/bin/
启动 hbase
[root@hadoop bin]# ./start-hbase.sh
1.3:搭建 Hbase 完全分布模式
序号 主机 角色 Ip 主机名 账户 密码
hadoop1
NameNode
ResourceManager
HMaster
QuorumPeerMain
hadoop2
DataNode
NodeManager
HRegionServer
QuorumPeerMain
hadoop3
NodeManager
DataNode
HRegionServer
QuorumPeerMain
1.3.1 完全配置好的 hadoop 集群(需要启动)
参考 hadoop 完全分布式搭建
1.3.2 完全配置好的 zookeeper 集群(需要启动)
参考 zookeeper 完全分布式搭建
1.3.3 按照上述 1.1 解压缩后进入到配置文件 conf 目录
[root@hadoop1 opt]# cd /opt/hbase/conf/
如上图:需要修改 hbase-site.xml、regionservers、hbase-env.sh 三个配置文件
1.3.4 编辑 hbase-site.xml
[root@hadoop1 conf]# vi hbase-site.xml
加入下面内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
</configuration>
配置参数说明:
在上面的配置文件中,第一个属性指定本机的 hbase 的存储目录;第二个属性指定 hbase 的运行
模式,true 代表全分布模式;第三属性是关于 Zookeeper 集群的配置。我的 Zookeeper 安装在 hadoop1
和 hadoop2、hadoop3 上。
1.3.5 修改 regionservers
[root@hadoop1 conf]# vi regionservers
在 regionservers 文件中添加如下内容 (删除原来里面的 localhost)
hadoop2
hadoop3
1.3.7 编辑 hbase-env.sh 设置 JAVA_HOME
[root@hadoop conf]# vi hbase-env.sh
修改 export JAVA_HOME=/usr/lib/jdk1.8/
修改 export HBASE_MANAGES_ZK=false (使用我们自己搭建的 zookeeper 集群)
1.3.8 将在 hadoop1 上配置好的安装包分发到 hadoop2 和 hadoop3 上
scp -r /opt/hbase/ hadoop2:/opt
scp -r /opt/hbase/ hadoop3:/opt
1.3.9 启动 hbase 集群
在 hadoop1 上进入到 hbase 的 bin 目录
[root@hadoop conf]# cd /opt/hbase/bin/
启动 hbase
[root@hadoop bin]# ./start-hbase.sh
在每个节点上分别用 jps 查看进程
hadoop1 上 HMaster
hadoop2 上 HRegionServer
hadoop3 上 HRegionServer
2:Hbase 基本操作
2.1、Hbase Shell 命令
使用 hbase shell 命令来连接正在运行的 Hbase 实例 按照上述 1 步骤配置好环境变量
后可以直接在命令行输入 hbase shell 来启动 hbase
启动成功如下:
2.2:显示 HBase Shell 帮助文档
输入 help 并按 Enter 键,可以显示 HBase Shell 的基本使用信息
2.3:退出 HBase Shell
使用 quit 命令,退出 HBase Shell 并且断开和集群的连接,但此时 HBase 仍然在后台运
行,也可以直接 ctrl+c
2.4:查看 HBase 状态 直接输入 status 回车
3、hbase 数据定义(DDL)操作
3.1:创建新表
使用 create 命令来创建一个新的表。在创建的时候,必须指定表名和列族名。
create 'user', 'info '
3.2: 列举表信息
使用 list 命令
list 'user'
3.3:获取表描述
使用 describe 命令
describe 'user'
3.4:检查表是否存在
使用 exists 命令
exists 'user'
操作结果图如下:
3.5:删除表
删除表之前,先 disable 表,再使用 drop 命令实现删除表的功能
drop 'user'
操作结果图如下:
4、数据管理(DML)操作
4.1:在上述步骤 3 中删除了 user 表,重新创建一张 user 表
create 'user', 'info'
4.2:向表中插入数据
使用 put 命令,将数据插入表中:
put 'user', 'row1', 'info:a', 'value1'
4.3:一次性扫描全表数据
一种获取 HBase 数据的方法是扫描,使用 scan 命令来扫描表的数据。(可以限制扫描的
范围)
scan 'user'
4.4:获取一个行数据
使用 get 命令来获得某一行的数据:
get 'user', 'row1'
4.5:禁用一个表
如果你想要删除一个表或是修改它的设置,或者是其它的情况,都需要首先禁用该表。
使用 disable 命令禁用表,enable 命令重新启用表。
disable 'user'
enable 'user'
如下图所示:
6:删除数据
删除行中的某个列值
# 语法:delete <table>, <rowkey>, <family:column> , <timestamp>
delete 'user','rowkey001','info:a'
删除行
# 语法:deleteall <table>, <rowkey>, <family:column> , <timestamp>
deleteall 'user','row1'
删除表中的所有数据
# 语法: truncate <table>
truncate 'user'
-
六、Hive安装
1.安装Mysql
1.1首先进入软件包目录
[root@hadoop1 ~]# cd tgz/
1.2解压缩mysql到/usr/local目录
[root@hadoop1 haoodp-install]# tar -zxvf mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
1.3进入到/usr/local目录并重命名
[root@hadoop1 haoodp-install]# cd /usr/local/
[root@hadoop1 local]# mv mysql-5.6.40-linux-glibc2.12-x86_64 mysql
1.4添加组用户
[root@hadoop1 local]# groupadd mysql
添加用户mysql 到用户组mysql
[root@hadoop1 local]# useradd -g mysql mysql
1.5安装mysql
Centos7将默认数据库mysql替换成了Mariadb
[root@localhost ~]# rpm -qa|grep mariadb // 查询出来已安装的mariadb
[root@localhost ~]# rpm -e --nodeps 文件名 // 卸载mariadb,文件名为上述命令查询出来的文件
yum remove mariadb
rm -rf /etc/my.cnf
rm -rf /var/lib/mysql/
yum --setopt=tsflags=noscripts remove MariaDB-client.x86_64;
删除etc目录下的my.cnf
1.5.1进入到安装包目录
[root@hadoop1 local]# cd /usr/local/mysql
1.5.2创建data目录下mysql文件夹
[root@hadoop1 mysql]# mkdir ./data/mysql
cd data
chown -R mysql:mysql mysql
依赖问题:
yum install -y perl perl-devel autoconf
yum install -y libaio.so.1
yum remove libnuma.so.1
yum -y install numactl.x86_64
1.5.3授权并执行脚本
[root@hadoop1 mysql]# chown -R mysql:mysql ./
[root@hadoop1 mysql]# chown -R mysql:mysql /usr/local/mysql
[root@hadoop1 mysql]# ./scripts/mysql_install_db --user=mysql --datadir=/usr/local/mysql/data/mysql
1.5.4复制mysql服务文件到/etc/init.d目录下并重命名
[root@hadoop1 mysql]# cp support-files/mysql.server /etc/init.d/mysqld
1.5.5修改服务文件权限
[root@hadoop1 mysql]# chmod 777 /etc/init.d/mysqld
1.5.6复制mysql的配置文件并重命名
[root@hadoop1 mysql]# cp support-files/my-default.cnf /etc/my.cnf
1.5.7修改mysql启动脚本
[root@hadoop1 mysql]# vi /etc/init.d/mysqld
修改下面内容
basedir=/usr/local/mysql/
datadir=/usr/local/mysql/data/mysql
1.5.8配置环境变量 加入mysql的安装路径
[root@hadoop1 conf]# vi /etc/profile
在文件的最底部加入下面内容
export PATH=$PATH:/usr/local/mysql/bin
退出后执行source /etc/profile命令更新环境变量
[root@hadoop1 conf]# source /etc/profile
1.5.10给mysql添加远程登录
[root@hadoop1 mysql]# vi /etc/my.cnf
在[mysqld]下面加
skip-name-resolve
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port=3306
server_id=1
socket=/tmp/mysql.sock
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
1.5.11初始化mysql
[root@hadoop1 mysql]# /usr/local/mysql/scripts/mysql_install_db --user=mysql
1.5.12启动mysql服务
[root@hadoop1 mysql]# service mysqld start
查看mysql服务状态
[root@hadoop1 ~]# service mysqld status
1.5.13登录mysql
[root@hadoop1 ~]# mysql -u root -p
第一次登录不需要密码,直接回车
1.5.14设置本机mysql用户名和密码
mysql> use mysql;
mysql> update user set password =password('root') where user ='root';
1.5.15添加远程登录用户
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
1.5.14创建hive数据库,来存储hive元数据信息
mysql>create database hive;
可以直接Ctrl+c 退出mysql或者exit
2.安装Hive
2.1首先进入软件包目录
[root@hadoop ~]# cd tgz/
2.2解压安装压缩包 将hive安装包(apache-hive-2.3.3-bin.tar.gz)解压缩到/opt目录下
[root@hadoop tgz]# tar -zxvf apache-hive-2.3.3-bin.tar.gz -C /opt
2.3进入到/opt目录
[root@hadoop ~]# cd /opt
2.4将解压的安装包重命名
[root@hadoop opt]# mv apache-hive-2.3.3-bin hive
2.5配置环境变量 加入hive的安装路径
[root@hadoop conf]# vi /etc/profile
在文件的最底部加入下面内容
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
退出后执行source /etc/profile命令更新环境变量
[root@hadoop conf]# source /etc/profile
2.6.配置hive
2.6.1 进入到hive的配置文件目录
[root@hadoop opt]# cd /opt/hive/conf/
2.6.2 复制hive-env.sh.template 一份并重命名为hive-env.sh
[root@hadoop conf]# cp hive-env.sh.template hive-env.sh
修改hive-env.sh,设置加入HADOOP_HOME=/opt/hadoop-3.1.1
[root@hadoop conf]# vi hive-env.sh
2.6.3 新建hive-site.xml
[root@hadoop conf]# vi hive-site.xml
需要在 hive-site.xml 文件中配置 MySQL 数据库连接信息 复制下面内容到新建文件中
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
2.6.4 配置mysql的驱动 将mysql驱动放到hive安装路径的lib目录下
[root@hadoop1]# cp tgz/mysql-connector-java-5.1.47.jar /opt/hive/lib/
2.6.5 hive在启动前到进行元数据初始化
[root@hadoop1 conf]# schematool -dbType mysql -initSchema
看到schemaTool completed 则初始化完成

检测hive 是否成功 直接在命令行输入hive即可hive (需要hadoop安装并启动)
启动成功如下:
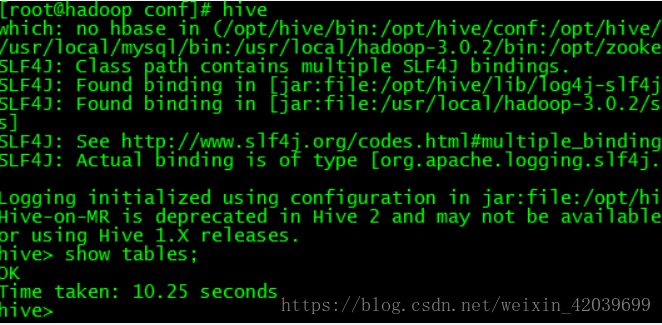
-
七、Scala安装
scala下载:https://www.scala-lang.org/download/
https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
解压到/opt下
vim /etc/profile
export PATH=$PATH:/opt/scala/bin
source /etc/profile
$ scala
-
八、Spark安装
安装前提
Java1.8 zookeeper hadoop Scala
集群规划
二 集群安装
1 解压缩
tar zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /opt/
mv spark-2.3.1-bin-hadoop2.7 spark
2 修改配置文件
(1)进入配置文件所在目录cd /opt//spark/conf/
(2)复制spark-env.sh.template并重命名为spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
编辑并在文件末尾添加如下配置内容
export JAVA_HOME=/usr/lib/jdk1.8
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=hadoop1
#指定master提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定master节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=1
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/opt/hadoop-3.1.1/etc/hadoop
#指定整个集群状态是通过zookeeper来维护的,包括集群恢复
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181
-Dspark.deploy.zookeeper.dir=/spark"
cd /opt/spark/conf
cp log4j.properties.template log4j.properties
Log4j.rootCategory=INFO, console修改为
Log4j.rootCategory=WARN, console
(3)复制slaves.template成slaves,并修改配置内容
cp slaves.template slaves
vi slaves
修改从节点
hadoop1
hadoop2
hadoop3
(4)将安装包分发给其他节点
修改hadoop2节点上conf/spark-env.sh配置的MasterIP为SPARK_MASTER_IP=hadoop2
修改hadoop3节点上conf/spark-env.sh配置的MasterIP为SPARK_MASTER_IP=hadoop3
3 配置环境变量
所有节点均要配置
vi /etc/profile
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile
三 启动集群
1 启动zookeeper集群
所有zookeeper节点均要执行
zkServer.sh start
2 启动Hadoop集群
3 启动Spark集群
启动spark:启动master节点:sbin/start-master.sh 启动worker节点:sbin/start-slaves.sh
或者:sbin/start-all.sh
注意:备用master节点hadoop2,hadoop3需要手动启动
sbin/start-master.sh
4 查看进程
启动spark
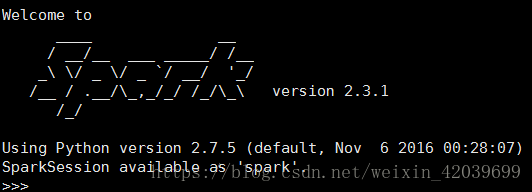
cd /opt/spark/bin
./pyspark
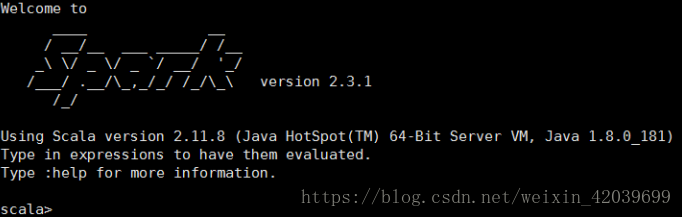
./spark-shell
-
九、Sqoop安装
解压缩
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/
cd /opt/
重命名mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
修改环境变量vi /etc/profile
export SQOOP_HOME=/opt/sqoop
export PATH=$SQOOP_HOME/bin:$PATH
source /etc/profile
将MySQL的驱动拷贝到lib下:
修改$SQOOP_HOME/bin/configure-sqoop
注释掉HCatalog,Accumulo检查(除非你准备使用HCatalog,Accumulo等HADOOP上的组件)
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HCAT_HOME}" ]; then
# echo "Warning: $HCAT_HOME does not exist! HCatalog jobs willfail."
# echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
#fi
#if [ ! -d "${ACCUMULO_HOME}" ];then
# echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports willfail."
# echo 'Please set $ACCUMULO_HOME to the root of your Accumuloinstallation.'
#fi
执行:sqoop version
测试连接:显示mysql数据库列表:
sqoop list-databases --connect jdbc:mysql://ip:3306/ --username hive --password hive
显示数据库里所有表:
sqoop list-tables --connect jdbc:mysql://ip:3306/hive --username hive --password hive
-
十、flume安装
环境
centos:7.3
JDK:1.8
Flume:1.8
一、Flume 安装
1、下载
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
2、解压
tar –zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin /usr/local/flume
3、设置环境变量
export FLUME_HOME=/opt/flume
export PATH=$FLUME_HOME/bin:$PATH
Source /etc/profile
4、配置java_home
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/usr/lib/jdk1.8
export HADOOP_HOME=/opt/hadoop-3.1.1
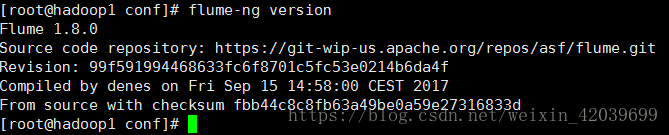
查看版本:flume-ng version
至此大数据环境平台基本搭建完成,各环节具体配置文件还需视情况而配。此文仅供参考,如有错误,望指出。感激不尽!