版权声明:转载请注明出处哦~ https://blog.csdn.net/Cassie_zkq/article/details/82875567
初学数据结构,在学习的过程中有了这个疑问,已经理解其中缘由,特写篇博客和大家一起分享交流。
C++中的引用:&
int a=10;
int &ra=a;
注意:此处&是标识符,不是取地址符!
a是目标原名称,ra是引用名,由引用的作用“引用就是某一变量(目标)的一个别名,对引用的操作与对变量直接操作完全一样。”可知当改变ra的值时,a的值也会随之改变。
此处主要讲的是引用的<传递可变参数>的作用,如一下代码
c形式:
void swapint(int *a,int *b)
{
int temp;
temp=*a;
*a=*b;
*b=temp;
}c++形式:
void swapint(int &a,int &b)
{
int temp;
temp=a;
a=b;
b=temp;
}以上两种代码作用相同,c++形式的代码采用了引用的方法,那么该函数结束后a,b的值也会随之改变,
int 是所引用变量的类型
链表结构体指针的引用
我所使用的教材是武汉大学的教学教材,其中结构体结点的定义如下:
typedef struct node{
ElemType data;
struct node *next;
}Linknode;几个常见的链表操作的函数:
bool createlink(linknode * &L,elemtype a[],int n)//创建链表
bool delete(linknode * &L,int i)//删除第i个元素e
其他一些相关的语句:
linknode * L;//创建头结点
L=(linknode *)malloc(sizeof(linknode));//为头结点分配空间linknode * L,即声明了一个结构体的指针,L指向的是这个结构体的首地址,记该地址为A1
malloc 为这个结构体指针类型的变量L分配的一个内存空间,此时即L指向的地址为A2
linknode * &L,即引用了这个结构体指针类型的变量L,引用L则会改变L,记delete函数执行完后L指向的地址为A3
我自己写了个简单的程序,输出这三个地址,发现:A1!=A2, A2=A3
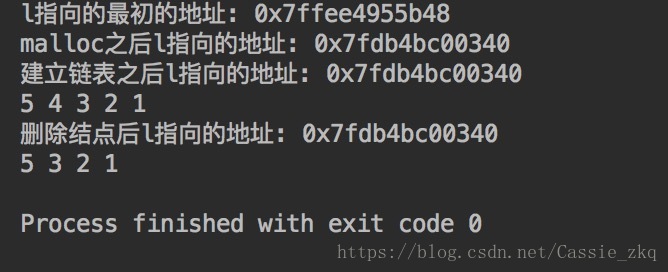
说明在删除一个元素之后L指向的地址并没有发生改变
我试着去掉insert函数用对L的引用符,发现依旧可以正常的删除,那么就没必要用引用符
结论
后来在询问了老师之后,我最终得到了如下结论:
引用L是为了改变L的值,而L指向的是链表的头结点的地址,即要改变头结点的地址,但是一般改链都是对头结点之后的结点进行操作,所以头结点的地址一直没变,故去掉&后函数依旧可以正常执行。之所以会加&,是以防没有链表是没有头结点的那种情况,因为可能会对第一个结点操作,那L的地址就会改变。