kafka不仅仅是一个简单的消息队列,这个很片面,它是一个完备的流式数据平台,具备下面三个特点
1 类似消息系统
2 数据存储功能
3 能够对实时事件流进行流式处理分析
展开来说:
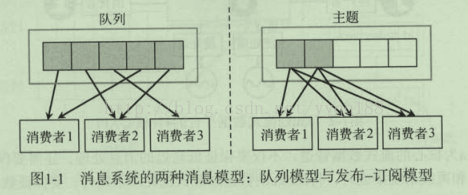
消息系统有两种消息模型,队列和发布订阅模型
存储系统是数据会保存到磁盘中。
流处理系统:简单的处理,可以直接使用kafka的生产者和消费者的API来完成,但对于复杂的业务逻辑处理,直接操作原始API需要做的工作非常多,,kafka为开发者提供了完整的流处理API,例如流的聚合,连接各种转换操作,同时kafka的流处理框架内部解决了很多流处理应用程序都会面临的问题:乱序和延迟(也是flink的主打功能),重新处理输入数据,窗口和状态操作等。
kafka主要包括下面4种核心的API
生产者 应用程序发布事件流到kafka的一个或多个主题
消费者 应用程序订阅kafka的一个或多个主题,并处理时间流
连接器 将kafka主题和已有数据源进行连接,数据可以互相导入和导出
流处理 从kafka主题消费输入流,经过处理后,产生输出流到输出主题

kafka中消息的格式样式

消息由生产者发布到kafka集群后,会被消费者消费。消息的消费模型有两种:推送模型(push)和拉取模型(pull)。kafka采用的拉取模型,由消费者自己记录消费状态。每个消费这互相独立的顺序读取每个分区的消息。
同一个消费组下多个消费者互相协调消费工作,kafka会将所有的分区平均的分配给所有的消费者实例,这样每个消费者都可以分配到数量均等的分区,kafka的消费组管理协议会动态的维护消费组的成员列表,当一个新的消费者加入消费组,或者有消费者离开消费组,都会触发再平衡操作。
重点:Kafka的消费者消费消息时,只保证在一个分区内消息的完全有序性,并不保证同一个主题中多个分区的消息顺序。而且,消费者读取一个分区消息的顺序和生产者写入到这个分区的顺序是一致的。如果业务上需要保证所有消息完全一致,只能通过设置一个分区完成,但这种做法的缺陷是最多只能有一个消费者进行消费。一般来说,只需要保证每个分区的有序性,再对消息加上健来保证相同键的所有消息都落入到同一个分区,这就可以满足绝大多数的应用。
kafka底层实现上的一些设计细节
1 人们普遍认为一旦涉及磁盘的访问,读写的性能就会严重下降,实际上,操作系统会将主内存剩余的所有空闲内存空间都用作磁盘缓存,所有的磁盘读写操作都会经过统一的磁盘缓存。如果针对磁盘的顺序访问,某些情况下,它可能比随机的内存访问都要快,甚至可以和网络速度相差无几。
2 数据到来时都会立即写入文件系统的持久化日志文件,但不进行刷新数据的任何调用,数据会首先被传输到磁盘缓存,操作系统随后会将这些数据定期自动刷新到物理磁盘。生产者会将多条消息按照分区进行分组,并采用批量的方式一次发送一个消息集,并且对消息集进行压缩,就可以减少网络的带宽,进一步提高数据的传输效率。
3 消费者消费采用了领拷贝的技术,只需将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面直接发送到网络中,消息使用的速度基本上等同于连接的速度了。假设有10个消费者,传统复制方式的数据复制次数是4*10=40 ,而零拷贝技术只需要1 + 10 = 11次,一次从磁盘复制到页面缓存,另外10次表示10个消费着各读取一次页面缓存。
4 kafka的生产者将消息直接发送给分区主副本所在的消息代理节点,并不需要经过任何的中间路由层,为了做到这一点,所有消息代理节点都会保存一份相同的元数据,这份元数据记录了每个主题分区对应的主副本节点。生产者客户端在发送消息之前,会向任意一个代理节点请求元数据,并确定每条消息对应的目标节点,然后把消息直接发送给对应的目标节点。
5 生产者客户端有两种方式决定发布的消息归属于哪个分区:1 通过随机方式将请求负载到不同的消息代理节点,或者使用 分区语义函数 将相同键的所有消息发布到同一个分区,对于分区语义,kafka暴露了一个接口,允许用户指定消息的键如何参与分区。
6 生产者采用批量发送消息集的方式解决了网络请求过多的问题。生产者在一个请求中一次发送一批数据,可以在生产者客户端设置 “在指定的时间内收集不超过指定数量的消息”,例如设置消息大小上限64字节,延迟在100毫秒内。100毫秒内达到64字节立即发送,100毫秒内达不到64字节到时间了也要发送
7 kafka的消费者会定时的将分区的消费进度保存成检查点文件,表示 在这个位置之前的消息都已经消费过了
8 和生产者采用批量发送消息类似,消费者拉取消息时也是一次拉取一批消息。但是消息者拉取方式有个缺点:如果消息代理没有数据或很少不够一批的了,消费这就会不断的轮询,等待新消息的到来。解决方法是:允许消费者的拉取请求以阻塞式,才轮询的方式等待,直到有新的数据到来。我们也可以指定消费者客户端设置 指定的字节的数量,在消息代理没有收集足够的数据时,客户端的拉取请求就不会立即返回。
9 备份副本始终尽量与主副本的数据同步。备份副本的日志文件和主副本的日志总是相同的,
也有相同的偏移量。
10 kafka对节点的存活定义有两个条件:
1) 节点必须和zk保持会话
2) 如果这个节点的某个分区的备份,复制主副本的进度不能落后太多
每个分区的主副本会跟踪正在同步中的备份副本(in-sync replice)ISR ,如果一个备份副本挂掉,没有响应,主副本就会将其从同步副本集合中移除。
11 一条消息只有被ISR集合中的所有副本都运用到了本地日志文件,才会认为消息被成功提交了,只有已经提交的消息才会被消费者消费。