参考链接:
1、https://software.intel.com/en-us/articles/intel-mkl-link-line-advisor/
2、https://blog.csdn.net/liang19890820/article/details/51774724
3、http://www.it1352.com/367668.html
4、http://eigen.tuxfamily.org/dox/TopicUsingIntelMKL.html
1、直接上代码,首先配置.pro文件。如下
QT += core
QT -= gui
CONFIG += c++11
TARGET = testEigenProcess
CONFIG += console
CONFIG -= app_bundle
TEMPLATE = app
SOURCES += main.cpp
# The following define makes your compiler emit warnings if you use
# any feature of Qt which as been marked deprecated (the exact warnings
# depend on your compiler). Please consult the documentation of the
# deprecated API in order to know how to port your code away from it.
DEFINES += QT_DEPRECATED_WARNINGS
# You can also make your code fail to compile if you use deprecated APIs.
# In order to do so, uncomment the following line.
# You can also select to disable deprecated APIs only up to a certain version of Qt.
#DEFINES += QT_DISABLE_DEPRECATED_BEFORE=0x060000 # disables all the APIs deprecated before Qt 6.0.0
# Eigen
INCLUDEPATH += \
/home/david/MySoft/myeigen
# openMP
QMAKE_CXXFLAGS += -fopenmp
LIBS += -fopenmp
# intel MKL
unix:INCLUDEPATH += /opt/intel/mkl/include
unix:LIBS += -L/opt/intel/mkl/lib/intel64 \
-lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core \
-L/opt/intel/lib/intel64 \
-liomp5 -lpthread -ldl -lm
2、测试代码如下:
#define EIGEN_USE_MKL_ALL
#include <QCoreApplication>
#include <Eigen/Dense>
#include <iostream>
#include <time.h>
#include <omp.h>
using namespace Eigen;
using namespace std;
void testOpenMP();
void print_xiao(char i)
{
cout << "omp_get_num_threads : " << omp_get_num_threads() << endl;
cout << "omp_get_max_threads: " << omp_get_max_threads() << endl;
cout << "omp_get_thread_num: " << omp_get_thread_num() << endl;
cout << "omp_get_num_procs: " << omp_get_num_procs() << endl;
cout << i << endl;
}
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
initParallel();
// use openMP
cout << "before set openMP threads: " << omp_get_num_threads() << endl;
int set_thread = 10;
omp_set_num_threads(set_thread);
cout << "after set openMP threads: " << omp_get_num_threads() << endl;
// #pragma omp parallel for
for (char i = 'a'; i <= 'z'; i++)
print_xiao(i);
// test mult-threading
int mat_size = 1000;
MatrixXd matXd, save_mat;
clock_t time_start = 0, time_end = 0;
matXd.resize(mat_size, mat_size);
matXd.setIdentity();
// use parallel maybe Slower for each matrix, but the overall speed will be fast.
// #pragma omp parallel for
for(int i = 0; i < 10;i++)
{
time_start = clock();
// save_mat = matXd.inverse();
save_mat = matXd * matXd;
// cout << save_mat << endl;
time_end = clock();
cout <<i << " -> Elapsed time is "
<< (double)(time_end - time_start)/CLOCKS_PER_SEC<< " seconds." << endl;
}
// testOpenMP();
return a.exec();
}
void testOpenMP()
{
double x,y,i,j;
long count=0,count1=0,count2=0;
clock_t startTime = 0, endTime = 0;
startTime=clock();
#pragma omp parallel sections
{
#pragma omp section
{
for(x=0;x<=0.5;x+=0.0001)
for(y=0;y<=1;y+=0.0001)
{
if(x*x+y*y<=1) count1++;
}
}
#pragma omp section
{
for(i=0.5001;i<=1;i+=0.0001)
for(j=0;j<=1;j+=0.0001)
{
if(i*i+j*j<=1) count2++;
}
}
}
count=count1+count2;
endTime=clock();
cout <<"testOpenMP() Elapsed time is "
<< (double)(endTime - startTime)/CLOCKS_PER_SEC<< " seconds." << endl;
// no parallel
startTime=clock();
#pragma omp parallel sections
{
#pragma omp section
{
for(x=0;x<=0.5;x+=0.0001)
for(y=0;y<=1;y+=0.0001)
{
if(x*x+y*y<=1) count1++;
}
}
#pragma omp section
{
for(i=0.5001;i<=1;i+=0.0001)
for(j=0;j<=1;j+=0.0001)
{
if(i*i+j*j<=1) count2++;
}
}
}
count=count1+count2;
endTime=clock();
cout <<"testOpenMP() Elapsed time is "
<< (double)(endTime - startTime)/CLOCKS_PER_SEC<< " seconds." << endl;
}
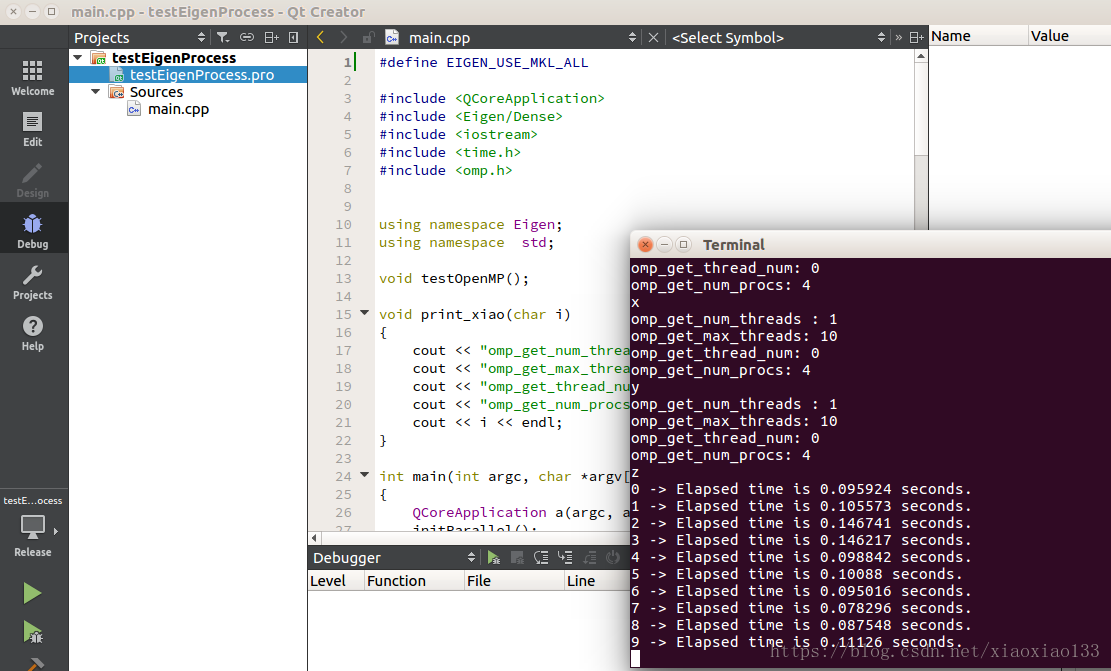
3、真多1000*1000矩阵想乘法,用不用#define EIGEN_USE_MKL_ALL 结果图如下:
不使用如下图:
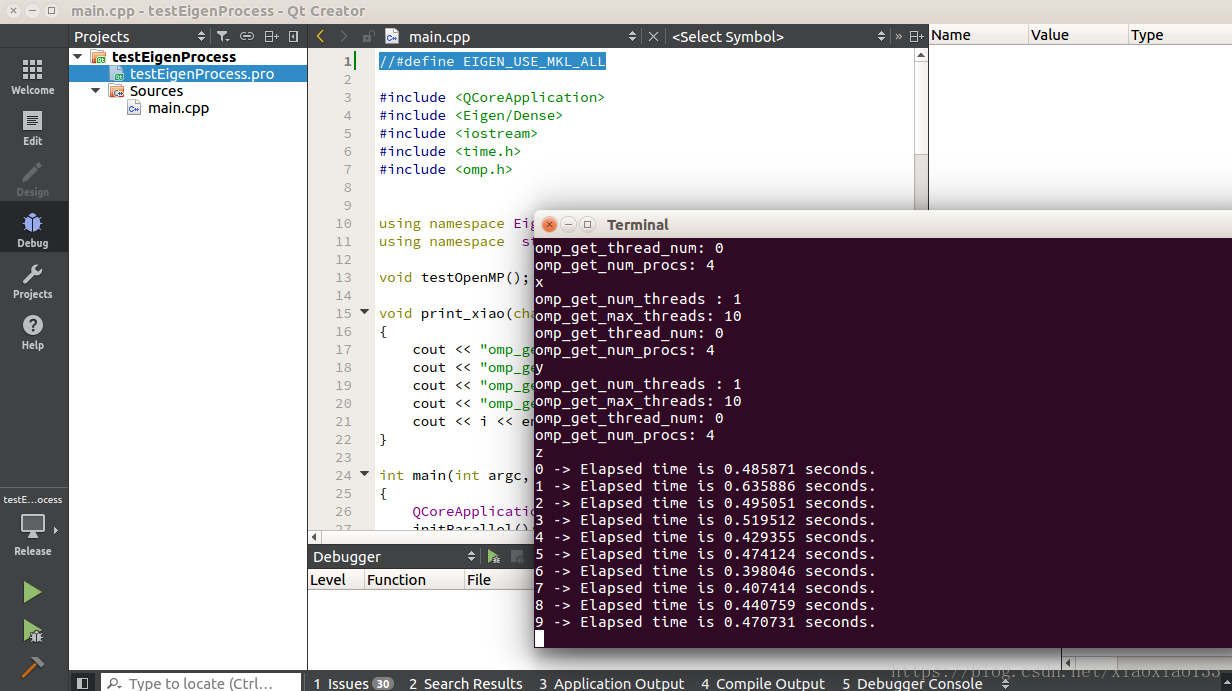
使用MKL如下图: