在x86 CPU中分页机制引入了线性地址和物理地址的概念,从而在一个独立的物理地址空间上,能够同时存在多个相同且独立的线性地址空间。在分页使能的情况下,CPU访问内存的时候,线性地址首先通过页表查询的机制转化为物理地址,然后再通过物理地址完成物理内存的访问。
对于64位的x86 CPU,若采用4级的分页机制,其基本结构如下图所示:
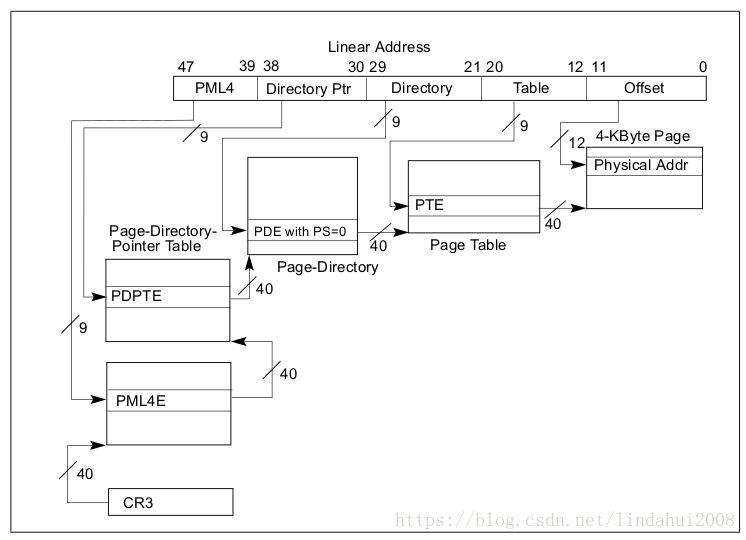
首先CR3寄存器存放着分级地址转换页表的入口地址,该地址指向第一级页表PML4(Page Map Level 4),PML4表中的每一项都会包含一个PDPTR(Page Directory Pointer Table )表的指针,然后PDPTR表中的每一项都会包含一个PD(Page Directory Table)表的指针,接着PD表中的每一项都会包含一个PT(Page Table)表的指针,最后每个Page Table表中的每一项都会包含一个Page Frame的地址,即目标物理内存页,将物理内存页的基地址加上偏移量Offset就可以得到最终的物理地址。通常情况下,对于采用4KB页的情况而言,PML4、PDPTR、PDE和PTE的宽度都为9bit,即每个页表的大小为512个entry,即每个entry的大小为64bit,Offset的宽度为12bit,正好可以索引4KB的空间。各级页表的索引值都是直接来自线性地址对应的地址位。当完成地址转换得到最终的物理内存地址的时候,CPU才会将物理地址打包到内存访问请求包中,发送到内存控制器上,完成最终的内存访问请求。
在没有任何加速的情况下,一次线性地址的访问需要多次的内存访问,至少需要4次的页表访问和一次最终的目标物理地址访问;若页表不存在(Page Fault),则需要的内存访问次数将会大大提升。所以从CPU的角度来看,即使是直接的物理内存访问,速度也不快。
下面是从 https://gist.github.com/jboner/2841832 引用的一个比较有参考性的时延表格:
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms对于没有任何cache帮助的物理内存访问而言,其时延(100ns)将会是L1 cache命中(0.5ns)的200倍,是L2 cache命中(7ns)的20倍左右。从这个可以很清楚地看出cache对于CPU性能的重要性。
为了提高CPU的性能,CPU内部实现了很多种类的cache,一种是直接将物理内存的数据cache过来,也就是我们通常所理解的L1 cache、L2 cache甚至是L3 cache,即直接将目标数据放到CPU的cache上。另外一种则是为了加快地址转换的cache,也就是这里要讨论的。
x86 CPU为了加快内存地址转换引入了两种cache,即TLB(Translation Lookaside Buffers)和Paging-Structure Cache。
- TLB用于直接将线性地址的高位(即page number)直接转换到物理内存页(即page frame)基地址,然后加上偏移量,即一步到位地将线性地址转换为物理地址。这种地址转换最快,只需要一次的TLB索引就可以完成,不需要访问地址转换页表。
- Paging-Structure Cache,即cache的对象是地址转换页表,直接加快地址转换页表的访问速度,最终达到地址转换加速的效果。
对于一个4级的页表来说,它包含了如下种类的paging-structure cache:
- PML4 cache,该cache的索引值(输入)来自线性地址的47:39位,对应到线性地址的PML4,cache的目标为PML4E的物理地址,通过该cache,可以直接得到PML4E;
- PDPTE cache,该cache的索引值来自线性地址的47:30位,对应线性地址的PML4和Directory Ptr,通过该cache,可以直接得到PDPTE;
- PDE cache,该cache的索引值来自线性地址的47:21位,对应到线性地址的PML4、Directory Ptr和Directory这几个区域,通过该cache可以得到PDE。
可以看出PML4 cache、PDPTE cache和PDE cache的关系是对地址转换页表的一级一级延伸,同时也可以将TLB看做是PTE cache,因为TLB中,它利用线性地址的47:12位来索引cache,对应到线性地址的PML4、Directory Ptr、Directory和Table这几个区域,通过它可以找到最终的page frame的基地址。如下图所示:
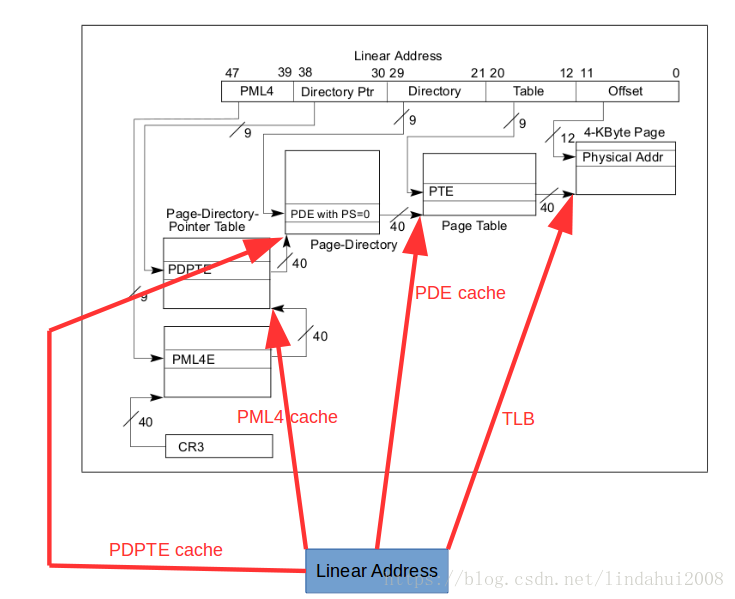
TLB cache直接省去了所有地址转换页表的访问;PDE cache则省去了对PML4 Table、Page Directory Pointer Table和Page Directory Table的访问;PDPTE cache则省去了PML4 Table和Page Directory Pointer Table的访问;PML4 cache则省去了对PML4 table的访问。这些用于地址转换的cache就是通过省去对地址转换页表的访问来达到加速的效果。
如上图所示,当CPU尝试去访问一个线性地址的时候,它会进行如下操作:
- 首先CPU会利用线性地址的47:12位作为索引,到TLB中去查找是否有相应的项,如果有,则直接利用TLB entry提供的物理页基地址进行最终的内存访问;如果没有则继续到第2步。
- CPU利用线性地址的47:21位,去PDE cache中查找,如果有相依的cache项,则直接利用该cache项提供的Page DirectoryTable地址,结合线性地址中PTE的值,直接访问页表查找Page Table的地址,从那开始正常的地址转换流程。如果PDE 中找不到相应项,则继续到第3步。
- CPU利用线性地址的47:30位,去PDPTE cache中查找,如果有相应的cache项,则直接利用该cache项提供的Page Directory Pointer Table地址,结合线性地址中PDE的值,直接访问页表查找Page Directory Table的地址,从那开始正常的地址转换流程。如果在PDPTE cache中找不到对应项,则继续到第4步。
- CPU利用线性地址的47:39位,去PML4 cache中查找,如果有相应的cache项,则利用该cache提供的PML4 Table地址,集合线性地址中的PDPTE的值,直接访问页表,查找Page Directory Pointer Table的地址,从那开始正常的地址转换流程。如果在PML4 cache中查找不到对应项,则继续到第5步。
- 到这里说明地址转换没有任何cache可用,则只能老老实实从CR3提供的物理地址中,一步一步地走地址转换的流程,这也是最慢的地址转换方法。
因为在操作系统中,不同的进程的线性地址空间是独立的,且可用线性地址空间的范围是一致的,这就导致如果发生进程切换的时候,为了不使切换进来的进程不会使用到被切换出去的进程的地址转换cache,就需要对这些cache进行flush操作,即将这些cache全部清除掉,这样会影响到系统的性能。为了解决这一问题,引入了PCID(Processor Context Identifiers)机制,即这些地址转换的cache被打上了PCID的标签(系统中,每个进程的PCID不一样,并且PCID在进程被切换进来的时候会被写到CR3寄存器的11:0位),当CPU内部查找地址转换的cache的时候,会先对cache里面的PCID信息和当前的PCID,即存放的CR3寄存器的11:0的值做比较,只有两个地方的PCID相等,CPU才可能会采用该cache项。这样就可以在每次进程切换的时候都需要对地址转换的cache进行flush的操作,同时可以保证不同的线性地址空间之间不会产生相互干扰。
总之,x86 CPU中就是通过引入cache的方式来加快线性地址的转换。
欢迎关注同名微信公众号“河马虚拟化”第一时间获取最新文章。