目录
一、使用Logistic和NaiveVayes建模
二、 Score Card原理
三、Naive Bayes评分卡
四、Logistics评分卡
这篇文章讲的第一章 ,利用使用Logistic和NaiveVayes建模
信用评分是指根据客户的信用历史资料,利用一定的信用评分模型,得到不同等级的信用分数。根据客户的信用分数, 授信者可以分析客户按时还款的可能性。据此, 授信者可以决定是否准予授信以及授信的额度和利率。虽然授信者通过分析客户的信用历史资料,同样可以得到这样的分析结果,但利用信用评分却更加快速、更加客观、更具有一致性。
所用的数据:链接:https://pan.baidu.com/s/1jIxkNRK 密码:es2f
加载包:
library(ggplot2)
library(sqldf)
#install.packages("klaR")
library(MASS)
library(klaR)根据你自己存的目录来写file路径:
german_credit<-read.csv("F:\\项目资料\\german_credit.csv",stringsAsFactors = TRUE)
str(german_credit)
贷款目的等。由于上面的数据大都都是数值型的,故需要根据实际情况将数值变量转换成因子型变量。
自定义函数将数值型转换为因子变量:
#自定义函数
fun<-function(x){as.factor(x)}
for (i in 1:21) {
german_credit[,i]<-fun(german_credit[,i])
}#个别数据在转换为数值型
german_credit$Duration.of.Credit..month.<-as.numeric(german_credit$Duration.of.Credit..month.)
german_credit$Credit.Amount<-as.numeric(german_credit$Credit.Amount)
german_credit$Age..years.<-as.numeric(german_credit$Age..years.)good<-german_credit[german_credit$Creditability==1,]
bad<-german_credit[german_credit$Creditability==0,]#取出数据的变量名
a<-colnames(german_credit)

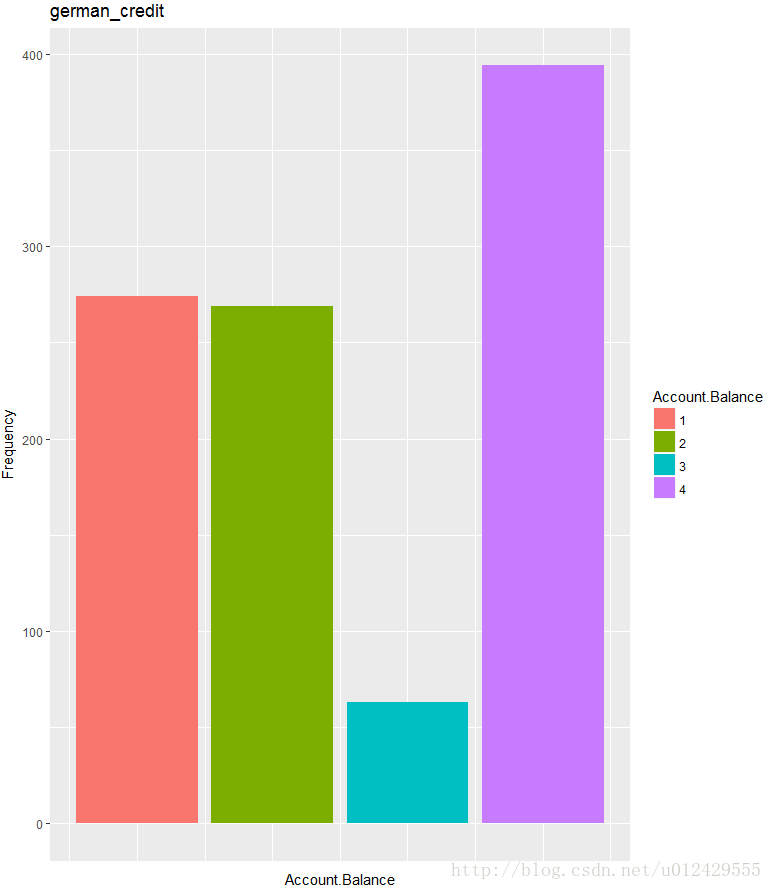
为了了解数据 ,我们对数据集中的各变量绘制条形图,这里仅以客户的存款余额为例,如果想了解更多其他变量的分布信息,可以稍作修改下方的代码。
#整体用户的存款余额条形图
ggplot(german_credit,aes(german_credit[,2]))+
#条形图
geom_bar(aes(fill = as.factor(german_credit[,2])))+
#填充色
scale_fill_discrete(name=a[2])+
#主题设置
theme(axis.text.x = element_blank(),axis.ticks.x = element_blank())+
#添加轴标签和标题
labs(x = a[2],y="Frequency",title="german_credit")
#好客户条形图
ggplot(good,aes(good[,2]))+geom_bar(aes(fill=as.factor(good[,2])))+scale_fill_discrete(name=a[2])+
theme(axis.title.x = element_blank(),axis.ticks.x = element_blank())+
labs(x=a[2],y="Frequent",title="good")

#坏客户的条形图
ggplot(bad,aes(bad[,2]))+geom_bar(aes(fill=as.factor(bad[,2])))+
scale_fill_discrete(name=a[2])+
theme(axis.title.x = element_blank(),axis.ticks.x = element_blank())+
labs(x=a[2],y="Frequent",title="bad")

Logistic模型
在建模之前,需要多数据集进行拆分,一部分用作建模,另一部分用作模型的测试。
#这是抽样的种子
set.seed(1234)
#抽样(训练集和测试集的比例为7:3)
index<-sample(1:2,size = nrow(german_credit),replace = TRUE,prob = c(0.7,0.3))train_data<-german_credit[index==1,]
test_data<-german_credit[index==2,]#建模
model<-glm(formula = train_data$Creditability~.,data = train_data,family = 'binomial')#模型信息概览
summary(model)
从上图的模型结果来看,Logistic模型中 很多自变量都没有通过显著性检验 ,接下来,我们 利用逐步回归 的方法,重新对模型进行建模。
“****”的prob很少。
#重新建模
model2<-step(object = model,trace=0)
# 模型信息概览
summary(model2)

经过逐步回归之后,模型效果得到了一定的提升(留下来了 很多显著的自变量 ,同时 AIC信息也下降了 很多)。我们知道,通过 Logistc模型 可以得到每个样本的 概率值prob ,该概率值是可以根据实际的业务进行调整的,如果风控要求的比较严格,那么就需要将prob值调节的更大。
下面,我们对模型的效果作一个评估,这里就使用混淆矩阵作为评估标准:
prob<-predict(object = model2,newdata = test_data,type='response')
#根据阈值,将概率分为两类
pred<-ifelse(prob>=0.8,'yes','no')
#将pred变量设置为因子
pred<-factor(pred,levels = c('no','yes'),ordered = TRUE)
#混淆矩阵
f<-table(test_data$Creditability,pred)
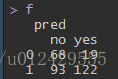
结果显示,模型的 准确率为62.9% 【(68+122)/(68+122+19+93)】,其中 19指的是 实际为坏客户,预测为好客户的数量; 93指的是 实际为好客户,预测为坏客户的数量。上面是将prob的阈值设置为0.8时的结论,下面再将阈值设置为0.5时,看看是什么结果。
pred<-ifelse(prob>=0.5,'yes','no')
#将pred变量设置为因子
pred<-factor(pred,levels = c('no','yes'),ordered = TRUE)
#混淆矩阵
f<-table(test_data$Creditability,pred)
f
通过改变概率的阈值,模型的准确率有所提升,达到73.8%【(183+40)/(183+40+32+47)】,其中47指的是实际为坏客户,预测为好客户的数量;32指的是实际为好客户。
当然,我们还可以更换模型,根据实际的业务进行变量的筛选,这个过程会比较繁琐,我们就以下面这个模型为例:
model3<- glm(formula=Creditability~Account.Balance+Duration.of.Credit..month.+Payment.Status.of.Previous.Credit+Purpose+Value.Savings.Stocks+Sex...Marital.Status,data=train_data,family = 'binomial')
# 模型概览信息
summary(model3)
# 测试集上的预测
prob <- predict(object = model3, newdata= test_data, type = 'response')
pred <- ifelse(prob >= 0.8, 'yes','no')
pred <- factor(pred, levels =c('no','yes'), order = TRUE)
f <- table(test_data$Creditability, pred)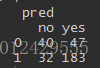
上图显示,相比于model2模型对应的0.8的阈值,这次 新建的模型要比逐步回归的准确率提高了一丁点 (0.3%),我相信模型的变更应该还会使准确率提升。上面的这些模型结果全都是基于Logistic得到的,下面我们再用贝叶斯模型做一次效果的对比。
贝叶斯模型
model4<- NaiveBayes(formula=Creditability~Account.Balance+Payment.Status.of.Previous.Credit+Duration.of.Credit..month.+Purpose+Value.Savings.Stocks+Sex...Marital.Status,data=train_data)
# 预测
pre <- predict(model4, newdata = test_data)
# posterior存储每个样本为坏客户和好客户的概率值
head(pre)
pre$posterior[,2]
pred <- ifelse(pre$posterior[,2] >= 0.8, 'yes','no')
f <- table(test_data$Creditability, pred)
f

Well Done,同为0.8的阈值,相比于model2和model3,贝叶斯模型得到的测试效果最佳,准确率达到了64%【(69+124)/(69+124+18+91)】。由于在风控领域,人们对待错误的判断会有不同的感受,例如原本一个好客户被判为了坏客户和原本一个坏客户被判为了好客户,也许你会对后者的错判带来的坏账损失而后悔,对前者的错判只会感到遗憾。不妨我们根据这种感受来规定一个错判的损失表达式:
lost=5*(坏预测为好的数量)+(好客户预测为坏客户的数量)
-
Model2在prob>0.8的 lost=19*5+93=188
-
Model2在prob>0.5的 lost2=47*5+32=267
-
Model3在prob>0.8的 lost3=19*5+92=187
-
Model4在prob>0.8的 lost5=18*5+91=181
虽然在建模过程中发现model2在0.5的阈值情况下准确率最高,但它带来的的损失值也是最高的,损失值最低的模型则是贝叶斯模型。
下一文章:R语言做评分卡模型<二> 评分卡