版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/YuYunTan/article/details/52654811
导言
本文将持续学习搜索相关的内容
全文搜索
目前为止搜索十分简单:单名,年龄过滤。让我们尝试一个更先进、全文搜索任务,这是传统的数据库很纠结的地方。
我们将搜索所有享受攀岩的员工:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}你可以看到,我们使用之前相同的match搜索对查询内容为“rock climbing”的 about字段。我们得到两个匹配文档信息:
{
...
"hits": {
"total": 2,
"max_score": 0.16273327,
"hits": [
{
...
"_score": 0.16273327, // --- (1)
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
...
"_score": 0.016878016, // --- (2)
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
默认情况下,Elasticsearch通过相关性系数得到类型匹配结果,也就是说,通过每个文档与查询匹配的匹配度有多好进行结果的返回。排名第一和高匹配度的结果是显而易见: John Smith’s about字段中清晰的看见“rock climbing”。
但是为什么Jane Smith作为一个结果返回?原因是她被返回的文档信息中“rock”该词在about域被提到。因为仅仅被提到了“rock”,而没有提到“climbing”,所以她的_score的值比John的低。
这是一个很好的例子,是关于Elasticsearch在全文字段中搜索并返回最相关的结果。Elasticsearch的相关性概念是很重要的,对传统的关系型数据库来说是一个完全陌生的概念,记录匹配与否。
实践
在sence中,输入如下的curl请求代码
curl -XGET "http://localhost:9200/megacorp/employee/_search" -d'
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}'结果如图所示:
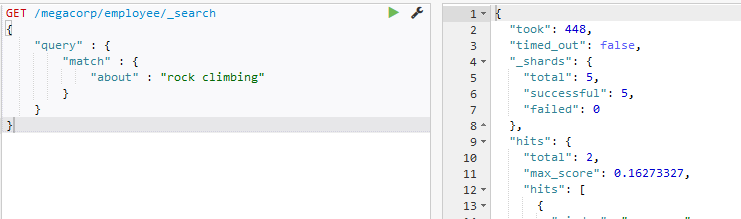
完整返回信息如下:
{
"took": 448,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.16273327,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.16273327,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.016878016,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}结语
全文搜索进行了一个大概的介绍,至于,到时候是否有具体实际的例子,还得待我有时间进行补充。