mysql有大量可以修改的参数,当然这其中有很大一部分参数只需要取默认值就可以了,但是也有一部分参数需要根据我们的服务器硬件等环境来做一些调整 。
mysql会从多个位置获取参数,根据获取的先后顺序来确定配置冲突的项,后面的配置会覆盖前面的配置,有时遇到修改配置文件后该参数不生效的情况,这就有可能是上述原因造成的。
在不同的操作系统中,mysql读取配置稳健的顺序不同,我们可以通过命令来查看系统读取配置文件的顺序
mysqld --help --verbose |grep -A 1 'Default options'
mysql参数分为 全局参数和会话参数,部分可以动态调整,调整命令:
全局参数修改:对所有会话有效
set global 参数名=参数值;
set @@global.参数名:=参数值;
会话参数修改:当前会话有效
set session 参数名=参数值;
set @@session.参数名:=参数值;
[mysqld]
socket
socket = /data/mysql/mysql.sock
socket其实就是一个做通信的文件,如果启用了mysql多实例mysql时,可以通过这个文件来快速登录mysql对应不同端口下的实例,曾经遇到过一次误删除这个文件的情况,后果就是
**[root@localhost mysql]# mysql -u root -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/data/mysql/mysql.sock' (2)**
但是没有socket文件影响的只是本地登录的情况,依旧可以通过指定ip的方式登录 如:
mysql -u root -p123456 -h 192.168.222.140
并且如果mysql用户拥有在配置文件中设置的socket路径的权限,那么重启mysql之后mysql.sock会自动生成

port
port = 3306 端口号,mysql默认为3306,可以更改为其他,但是需要重新配置防火墙(3306端口也需要配置防火墙通过)
防火墙通过 vim /etc/sysconfig/iptables设置
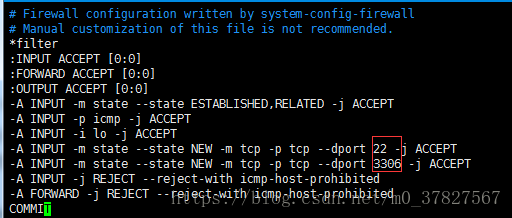
只需要新添加一行,并修改想要防火墙通过的端口号即可
server-id
server-id = 1 #表示是本机的序号为1,一般来讲就是master的意思 注意:如果配置binlog却未配置本选项,mysql服务将启动失败,并且无错误日志显示
一般在主从架构中使用,序号在架构中唯一,重复主从将会失效,在做架构的时候让主库的server_id保持最小,并且在重做架构时更换server_id是个好习惯。
skip-name-resolve
禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间,就能大大加快MySQL连接的速度。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求。
max_connections
MySQL的最大连接数,这个参数实际起作用的最大值为16384,即使超过也以16384为准,该参数设置过小的最明显特征是出现Too many connections错误。
介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。
可以通过命令设置最大连接数:
set global max_connections = 200;
命令临时设置参数大小数据库重启时失效。
max_connect_errors
对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,在数据库中执行:
mysql> flush hosts;
max_connect_errors 不能作为防止穷举密码攻击的手段,对于引发的“ERROR 1129 (00000): Host 'xxx' is blocked because of many connection errors. Unblock with 'mysqladmin flush-hosts'”错误往往由于网络异常,网络超时所导致,
通过flush hosts和调大该参数的值都可以暂时解决这个问题,但是最终也要解决网络异常这个根本原因
max_allowed_packet
接受的数据包大小,过小会引起Got a packet bigger than 'max_allowed_packet' bytes 错误
增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。
该参数限制的不是sql文件的大小,针对的是限制单个表的大小,SQL中对于同一张表进行的insert的所有数据为一个packet,这个packet超过参数值则报错。
可以通过sql语句修改,但不能使用M,G等单位,必须换算成字节数进行设置,并且设置后重新登录有效,重启失效,在配置文件中可以设置M,G单位,数据库重启有效,并且该参数最大值为1G,超过会被强制设置为1G。
binlog_cache_size
一个事务,在没有提交(uncommitted)的时候,产生的日志,会先记录到Cache中;等到事务提交(committed)需要提交的时候,则把日志持久化到磁盘。该参数是会为每一个连接分配相应内存的,所以设置时需要权衡,默认32k,略小

tmp_table_size、max_heap_table_size
内存临时表大小,当查询中出现order by 、group by 等子句,需要用到临时表存储结果集时,如果结果集的大小大于该参数值,就会在磁盘创建临时表,很费时,mysql会取值两者最小的为有效值,所以设置为一样大即可,200M左右。
sort_buffer_size
这个参数定义了mysql每个线程使用的排序缓存区的大小,mysql并不是在连接初始化的时候就会给每个链接分配内存,而是在有查询需要做排序操作时才会为每个缓冲区分配内存,重要的是,一旦查询需要排序,mysql会立即分配这个参数指定大小的全部内存,而不管这个排序是否需要这么大内存。
join_buffer_size
这个参数定义了mysql每个线程使用的连接缓冲区的大小,如果一个查询中关联了多张表,那么就会为每个关联分配一个连接缓冲,所以每个查询可能会有多个连接缓冲,所以不适合设置过大。
read_buffer_size
这个参数指定了当对一个myisam表进行全表扫描时所分配的读缓冲池的大小,mysql只会在有查询需要的时候,才会分配内存,分配该参数的全部内存,此参数大小需为4K的倍数。
read_rnd_buffer_size
MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。这个参数用在sort查询之后 ,以保证获取以顺序的方式获取到查询的数据。如果你有很多order by 查询语句,增长这值能够提升性能,只在有查询需要时才会对该缓冲区分配内存,并且只会分配需要的内存大小,而不是参数指定的大小。
以上四个参数 read_buffer_size,read_rnd_buffer_size,sort_buffer_size,join_buffer_size 都是为每个线程分配的,如果有100个连接那么可能会分配100倍以上四个参数内存大小的和,所以参数设置过大会造成内存浪费,甚至内存溢出而使mysql服务器崩溃。
thread_cache_size
这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。
根据物理内存设置规则如下:
1G —> 8,2G —> 16,3G —> 32,大于3G —> 64
query_cache_size、query_cache_type、query_cache_limit
查询缓冲相关:
query_cache_size:MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。
query_cache_type :0则不使用查询缓存。1表示始终使用查询缓存。2表示按需使用查询缓存。
如果query_cache_type为1而又不想利用查询缓存可以通过:
SELECT SQL_NO_CACHE * FROM 表名 ;来查找
如果query_cache_type为2,要使用缓存的话可以通过:
SELECT SQL_CACHE * FROM 表名 ;来查找
query_cache_limit 参数可以指定单个查询能够使用的缓冲区大小,默认1M
会影响性能,一般不建议开启。
慢查询相关
slow_query_log = 1 #开启慢查询日志
long_query_time = 1 #慢查询时间 超过1秒则为慢查询
slow_query_log_file = /data/mysql/mysql-slow.log #慢查询日志目录
慢查询日志可以通过设置long_query_time=0 来抓取一段时间内MySQL服务器所接受的所有查询请求。
查看慢日志状态
mysql> show variables like '%slow%';
临时打开慢查询日志:
mysql>set global slow_query_log='on';
Query OK, 0 rows affected (0.00 sec)
临时设置慢查询超时时间:
mysql> set global long_query_time=1; 打开新会话生效,当前无效
Query OK, 0 rows affected (0.00 sec)
mysql> set global log_queries_not_using_indexes=1; 把没有用到索引的查询记录到日志中
Query OK, 0 rows affected (0.00 sec)
得到访问次数最多的10个SQL
shell# mysqldumpslow -s c -t 10 /data/mysql/data/52cx100-slow.log
mysqldumpslow参数:-s, 是表示按照何种方式排序 c: 访问计数 l: 锁定时间 r: 返回记录 t: 查询时间 al:平均锁定时间 ar:平均返回记录数 at:平均查询时间 -t, 是top n的意思,即为返回前面多少条的数据;-g, 后边可以写一个正则匹配模式,大小写不敏感的;
transaction_isolation
隔离级别:MySQL支持4种事务隔离级别,他们分别是:READ-UNCOMMITTED读未提交, READ-COMMITTED不可重复读, REPEATABLE-READ可重复读, SERIALIZABLE串行化.
MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTED
读未提交状态下A事务在没有提交的情况下,在B事务中就可以看到A中的修改
不可重复读状态下A在事务中只能查询到B事物中提交的数据 但一个事务中A可能读取到B事物中不同的数据值
可重复读状态下 A在事务中只能查询到B事物中提交的数据 并且只会查询到相同的B事务修改的数据值
串行化状态下,不能同时操作一张表。
未完待续