洛谷传送门
BZOJ传送门
题目描述
小c同学认为跑步非常有趣,于是决定制作一款叫做《天天爱跑步》的游戏。《天天爱跑步》是一个养成类游戏,需要玩家每天按时上线,完成打卡任务。
这个游戏的地图可以看作一一棵包含 个结点和 条边的树, 每条边连接两个结点,且任意两个结点存在一条路径互相可达。树上结点编号为从 到 的连续正整数。
现在有 个玩家,第 个玩家的起点为 ,终点为 。每天打卡任务开始时,所有玩家在第 秒同时从自己的起点出发, 以每秒跑一条边的速度, 不间断地沿着最短路径向着自己的终点跑去, 跑到终点后该玩家就算完成了打卡任务。 (由于地图是一棵树, 所以每个人的路径是唯一的)
小c想知道游戏的活跃度, 所以在每个结点上都放置了一个观察员。 在结点jj的观察员会选择在第
秒观察玩家, 一个玩家能被这个观察员观察到当且仅当该玩家在第
秒也理到达了结点
。 小C想知道每个观察员会观察到多少人?
注意: 我们认为一个玩家到达自己的终点后该玩家就会结束游戏, 他不能等待一 段时间后再被观察员观察到。 即对于把结点 作为终点的玩家: 若他在第 秒前到达终点,则在结点 的观察员不能观察到该玩家;若他正好在第 秒到达终点,则在结点 的观察员可以观察到这个玩家。
输入输出格式
输入格式:
第一行有两个整数 和 。其中 代表树的结点数量, 同时也是观察员的数量, 代表玩家的数量。
接下来 行每行两个整数 和 ,表示结点 到结点 有一条边。
接下来一行 个整数,其中第 个整数为 , 表示结点 出现观察员的时间。
接下来 行,每行两个整数 ,和 ,表示一个玩家的起点和终点。
对于所有的数据,保证 。
输出格式:
输出 行 个整数,第 个整数表示结点 的观察员可以观察到多少人。
输入输出样例
输入样例#1:
6 3
2 3
1 2
1 4
4 5
4 6
0 2 5 1 2 3
1 5
1 3
2 6
输出样例#1:
2 0 0 1 1 1
输入样例#2:
5 3
1 2
2 3
2 4
1 5
0 1 0 3 0
3 1
1 4
5 5
输出样例#2:
1 2 1 0 1
说明
【样例1说明】
对于 号点, ,故只有起点为 号点的玩家才会被观察到,所以玩家 和玩家 被观察到,共有 人被观察到。
对于 号点,没有玩家在第 秒时在此结点,共 人被观察到。
对于 号点,没有玩家在第 秒时在此结点,共 人被观察到。
对于 号点,玩家 被观察到,共 人被观察到。
对于 号点,玩家 被观察到,共 人被观察到。
对于 号点,玩家 被观察到,共 人被观察到。
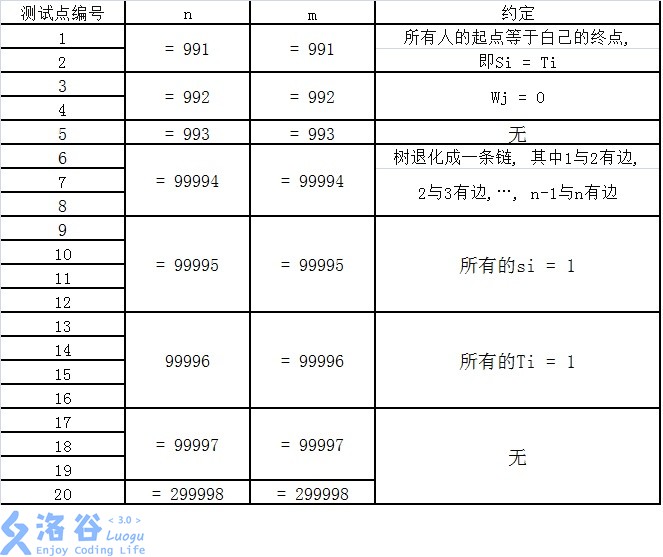
【子任务】
每个测试点的数据规模及特点如下表所示。 提示: 数据范围的个位上的数字可以帮助判断是哪一种数据类型。
解题分析
其实 为 和 为 的部分分是在给我们提示:一条 的路径上可以分成两部分: 。
前半部分情况路径上的点 可以获得 的贡献当且仅当 , 而 是一个定值, 我们 的时候记录一下子树中符合要求的点的个数就好了。
后半部分情况路径上的点 可以获得 的贡献当且仅当 , 而 是一个定值, 同样我们记录一下就好了。 注意这个值可能是负数, 所以记录的时候统一
然而还可能出现这个路径并不过 的情况, 所以我们分别在 和 打上 的标记, 在两种情况的 打上上 的标记, 到的时候记录一下上面的满足要求的个数, 最后子树 完成的时候作差即可。
有两种特殊情况:
- 或 , 这时我们只取上面的一种情况即可。
- , 这时我们相当于多算了一次这条路径的贡献, 即可。
代码如下:
#include <cstdio>
#include <cstring>
#include <cctype>
#include <algorithm>
#include <cstdlib>
#include <vector>
#define R register
#define IN inline
#define W while
#define gc getchar()
#define MX 600500
template <class T>
IN void in(T &x)
{
x = 0; R char c = gc;
for (; !isdigit(c); c = gc);
for (; isdigit(c); c = gc)
x = (x << 1) + (x << 3) + c - 48;
}
int dep[MX], fat[MX], son[MX], siz[MX], head[MX], topf[MX];
int from[MX], to[MX], lca[MX], tim[MX], ans[MX], cntup[MX], cntdown[MX];
int dot, line, cnt;
struct Edge {int to, nex;} edge[MX << 1];
struct INFO {int tar, val;};
std::vector<INFO> up[MX], down[MX];
IN void add(R int fr, R int to) {edge[++cnt] = {to, head[fr]}, head[fr] = cnt;}
void DFS(R int now)
{
siz[now] = 1;
for (R int i = head[now]; i; i = edge[i].nex)
{
if(edge[i].to == fat[now]) continue;
fat[edge[i].to] = now;
dep[edge[i].to] = dep[now] + 1;
DFS(edge[i].to);
siz[now] += siz[edge[i].to];
if(siz[edge[i].to] > siz[son[now]]) son[now] = edge[i].to;
}
}
void DFS(R int now, R int grand)
{
topf[now] = grand;
if(!son[now]) return;
DFS(son[now], grand);
for (R int i = head[now]; i; i = edge[i].nex)
{
if(edge[i].to == fat[now] || edge[i].to == son[now]) continue;
DFS(edge[i].to, edge[i].to);
}
}
IN int get(R int x, R int y)
{
W (topf[x] != topf[y])
{
if(dep[topf[x]] < dep[topf[y]]) std::swap(x, y);
x = fat[topf[x]];
}
return dep[x] < dep[y] ? x : y;
}
void calc(R int now, R int u, R int d)
{
for (R int i = up[now].size() - 1; ~i; --i)
cntup[up[now][i].tar + 300000] += up[now][i].val;
for (R int i = down[now].size() - 1; ~i; --i)
cntdown[down[now][i].tar + 300000] += down[now][i].val;
for (R int i = head[now]; i; i = edge[i].nex)
{
if(edge[i].to == fat[now]) continue;
calc(edge[i].to, cntup[dep[edge[i].to] + tim[edge[i].to] + 300000], cntdown[tim[edge[i].to] - dep[edge[i].to] + 300000]);
}
ans[now] += cntup[dep[now] + tim[now] + 300000] + cntdown[tim[now] - dep[now] + 300000] - u - d;
}
int main(void)
{
int a, b, c;
in(dot), in(line);
for (R int i = 1; i < dot; ++i) in(a), in(b), add(a, b), add(b, a);
for (R int i = 1; i <= dot; ++i) in(tim[i]);
DFS(1), DFS(1, 1);
for (R int i = 1; i <= line; ++i)
{
in(from[i]), in(to[i]); lca[i] = get(from[i], to[i]);
if(lca[i] == to[i])
{
up[fat[lca[i]]].push_back({dep[from[i]], -1});
up[from[i]].push_back({dep[from[i]], 1});
}
else if(lca[i] == from[i])
{
down[fat[lca[i]]].push_back({dep[from[i]] - (dep[lca[i]] << 1), -1});
down[to[i]].push_back({dep[from[i]] - (dep[lca[i]] << 1), 1});
}
else
{
if(tim[lca[i]] + dep[lca[i]] == dep[from[i]]) --ans[lca[i]];
up[from[i]].push_back({dep[from[i]], 1});
up[fat[lca[i]]].push_back({dep[from[i]], -1});
down[fat[lca[i]]].push_back({dep[from[i]] - (dep[lca[i]] << 1), -1});
down[to[i]].push_back({dep[from[i]] - (dep[lca[i]] << 1), 1});
}
}
calc(1, 0, 0);
for (R int i = 1; i <= dot; ++i) printf("%d ", ans[i]);
}