1. 基本概念
路径长度:树中一个结点到另一个结点路径上的分支数目。
树的路径长度:从树根到每一结点的路径长度之和。
带权路径长度:结点到树根之间的路径长度与结点上权的乘积。
树的带权路径长度(WPL):树中所有叶子结点的带权路径长度之和。
郝夫曼树(最优二叉树):对于一棵有n个叶子结点的二叉树,带权路径长度最小的二叉树。
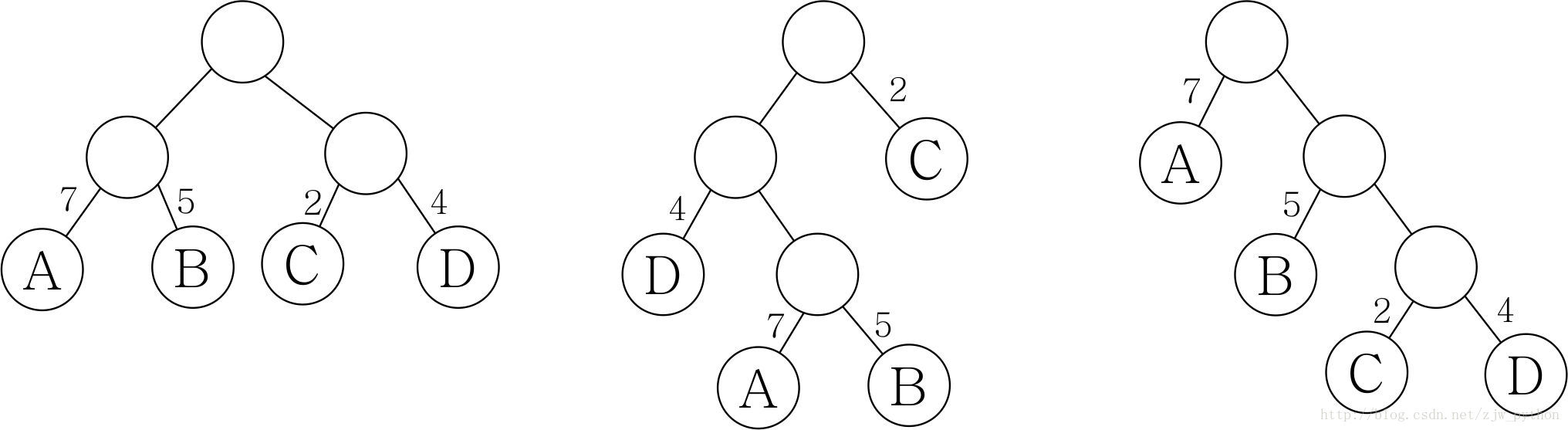
第一棵树 WPL=7*2+5*2+2*2+4*2=36
第二棵树 WPL=7*3+5*3+2*1+4*2=46
第三棵树 WPL=7*1+5*2+2*3+4*3=35
上述二叉树中,第三棵树带权路径长度最小,可以验证,第三棵树恰为郝夫曼树。
2.郝夫曼树的构造方法
假如现有4个权值,分别为a=7, b=5, c=2, d=4
1. 先把有权值的叶子结点按照权值从小到大排列成一个有序序列。即c, d, b, a。
2. 取头两个最小的权值的结点作为一个新节点N1的两个子节点,其中权值较小的为左孩子,权值较大的为右孩子,新节点的权值为两孩子结点的权值之和,即N1=c+d=2+4=6。
3. 用N1替换c和d,插入有序序列中,保持从小到大排列。
4. 重复步骤2,直到序列中只存在一个结点,该结点即为根结点。
3.郝夫曼编码
例如有一段文字内容“BADCADFEED”,用相应的二进制数据表示:
A:000, B:001,C:010,D:001,E:100,F:101
编码后的数据为“001000011010000011101100100011”,很长的一段码
但是在实际中,有的字母用的频率很高,例如“a”,而有些字母则不常用,例如“x”
假设六个字母的平均使用频率为 A 27%,B 8%,C 15%,D 15%,E 30%,F 5%,可以将其作为权值,构造一颗郝夫曼树,并将左分支改为0,右分支改为1
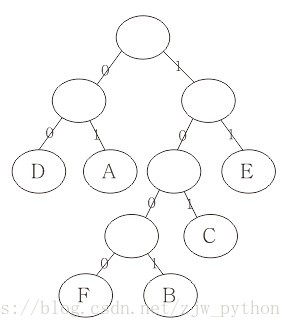
根据每个字母所经过的路径重新编码后,六个字母为 A:01,B:1001,C:101,D:00,E:11,F:1000。我们可以看到,重新编码后,使用频率较高的字母编码长度变小了,而使用频率较低的字母,编码则加长了
原来的文字内容 “BADCADFEED”重新编码为“1001010010101001000111100”,比原来少了5个字符,节约了约17%的传输成本。