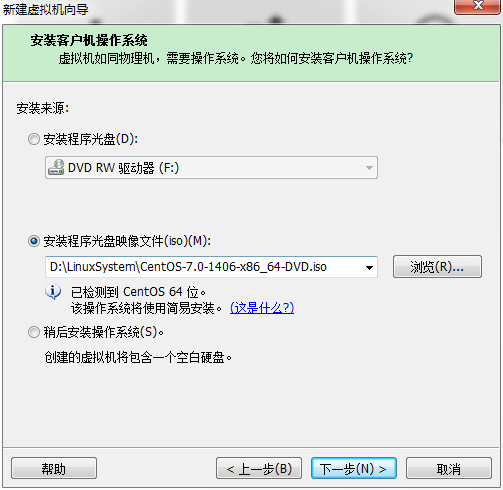
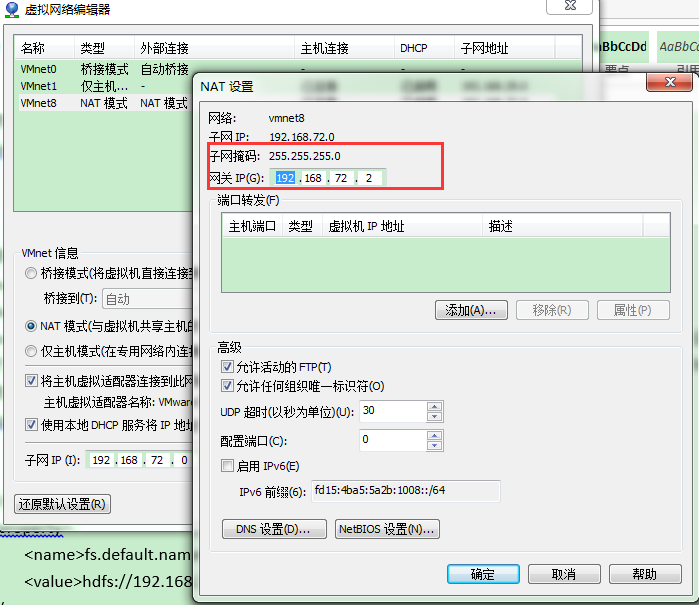
直接下一步。。。,网络类型这里注意选择NAT模式:
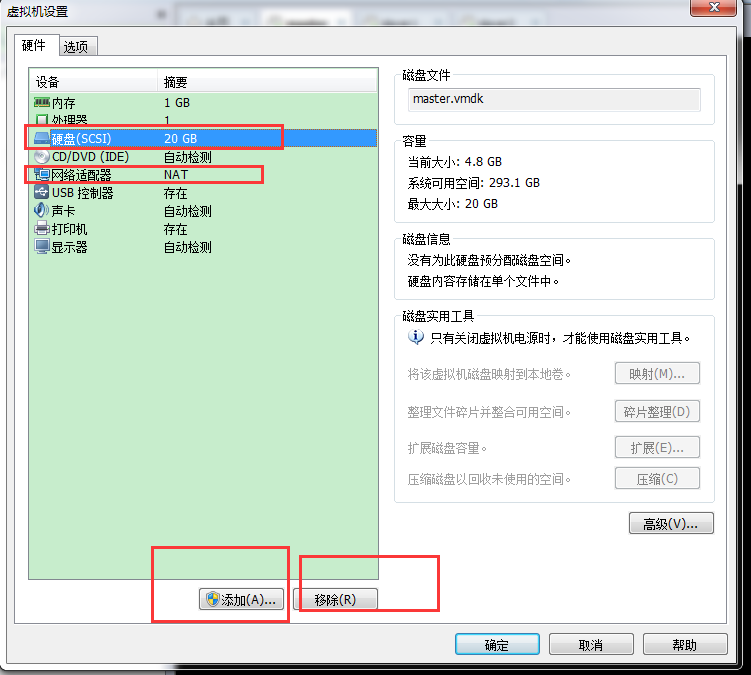
然后直接下一步。。。,磁盘类型这里选择存储为单个文件,方便后续拷贝:
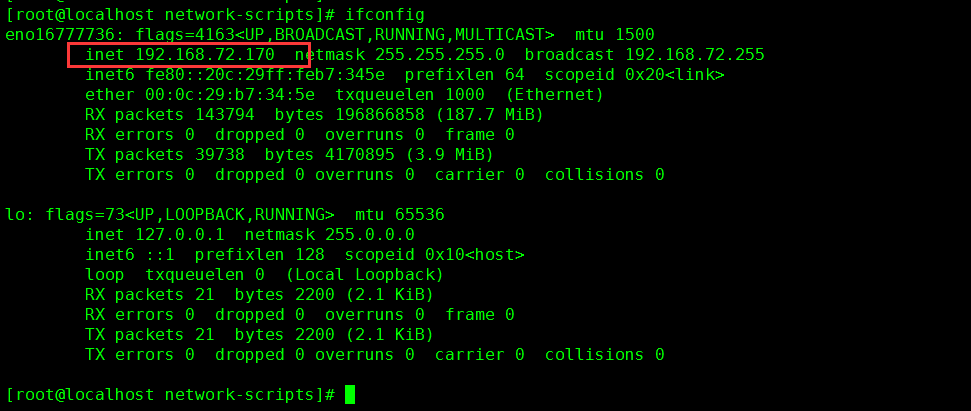
# HWADDR=00:0C:29:B7:34:5E TYPE=Ethernet BOOTPROTO=static DEFROUTE=yes IPADDR=192.168.72.170 NETMASK=255.255.255.0 GATEWAY=192.168.72.2 DNS1=8.8.8.8 PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no #IPV6INIT=yes #IPV6_AUTOCONF=yes #IPV6_DEFROUTE=yes #IPV6_PEERDNS=yes #IPV6_PEERROUTES=yes #IPV6_FAILURE_FATAL=no NAME=eno16777736 DEVICE=eno16777736 UUID=20d57e47-ca2c-4c84-9e7d-e9c59460489a ONBOOT=yes
192.168.72.170 master 192.168.72.171 slaver1 192.168.72.172 slaver2
export JAVA_HOME=/usr/src/jdk1.6.0_45 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH


slaves文件:指定slave节点的主机名,本例写入slaver1 salver2
core-site.xml:增加property节点,两个分别为hadoop.tmp.dir和fs.default.name,一个是运行目录(指定之前要先在Hadoop目录下创建tmp目录),另一个是hdfs访问地址(hdfs://IP地址:9000)。
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/src/hadoop-1.2.1/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.72.170:9000</value>
</property>
mapred-site.xml:配置job tracker访问URL,地址要以http打头。
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.183.10:9001</value>
</property>
hdfs-site.xml:配置hdfs文件保存的副本数,默认为3
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
hadoop-env.sh文件:指定java的安装目录。
export JAVA_HOME=/usr/local/src/jdk1.6.0_45
将master配置好的Hadoop文件夹,拷贝到slaver1和slaver2:

10、修改主机名和主机配置信息,修改两个文件:
/etc/hosts:配置IP地址与主机名的映射关系;
/etc/sysconfig/network:永久修改主机名;
(centos7 采用hostnamectl set-hostname 主机名命令,永久设置主机名)

hostname + 主机名的方式,修改主机名知识临时生效,要永久生效需要修改/etc/sysconfig/network文件中的HOSTNAME的值。
执行hostname 主机名命令,让修改的主机名立即生效(这样不用重启系统)。
依次修改slaver1和slaver2节点的hosts和network文件。运行hostname命令。
11、关闭防火墙
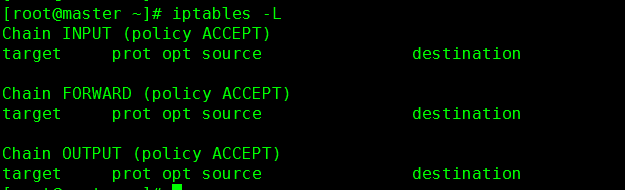
执行命令(每台机器都需要):/etc/init.d/iptables stop
检查当前防火墙信息,iptables -L
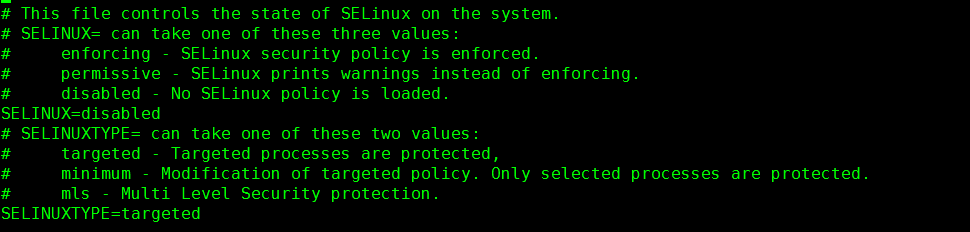
执行命令:setenforce 0 (每台机器)
检查命令:getenforce,输出Permissive
centos7命令(与上面不一致):
关闭防火墙:systemctl stop firewalld.service
12、配置ssh
执行ssh-keygen命令,从输出信息可以看到,公钥public key 保存在/root/.ssh/id_rsa.pub中。
cd ~/.ssh/ 进入目录,将公钥文件拷贝给本机私钥(执行命令 cat id_rsa.pub > authorized_keys)
查看主机的公钥文件和私钥文件,内容一致。

依次用密令生成slaver1和slaver2节点的公钥,将它们的公钥内容拷贝到master节点的私钥文件中(authorized_keys),相当于master节点的私钥文件中包含了master、slaver1、slaver2三个节点的公钥。
然后将master节点配置的私钥文件拷贝给slaver1和slaver2,分别覆盖它们的私钥文件,这样三个节点的私钥文件都包含的各自和自己的公钥。

验证:在各节点直接用ssh 主机名的方式,登录其他主机,不用输入密码,直接登录。
13、进入master节点的Hadoop 目录bin目录下:
第一次启动需要对Hadoop namenode 进行格式化,输入命令 ./hadoop namenode -format
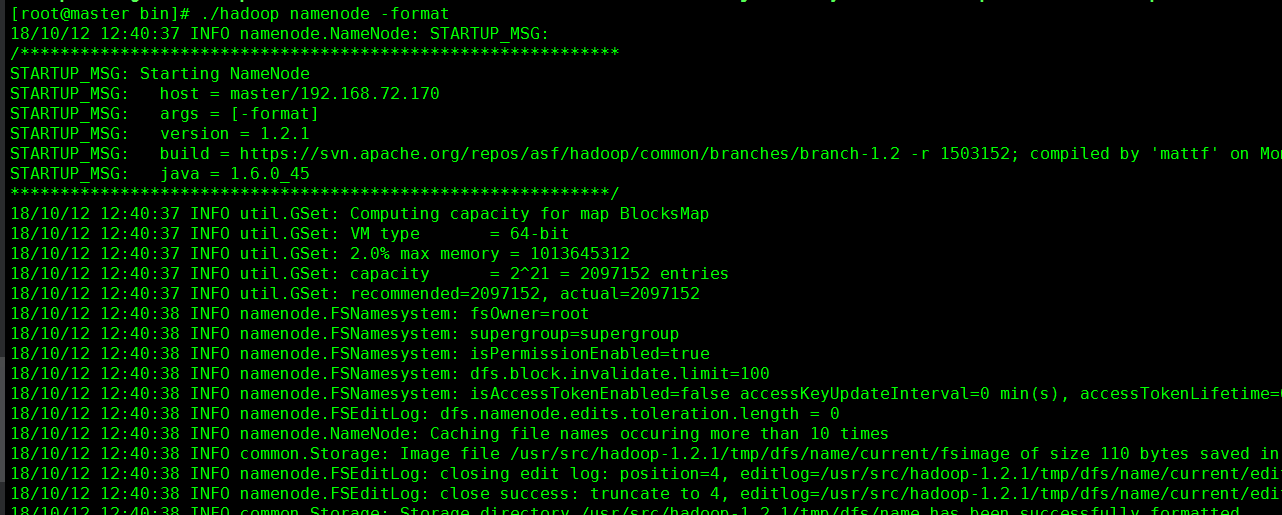
格式化之后 执行./start-all.sh 将整个集群启动。
14、输出jps命令:
matser节点:
NameNode
SecondaryNameNode
JobTracker

slaver节点:
TaskTracker
DataNode

./hadoop fs -ls / 查看当前集群hdfs是否可用
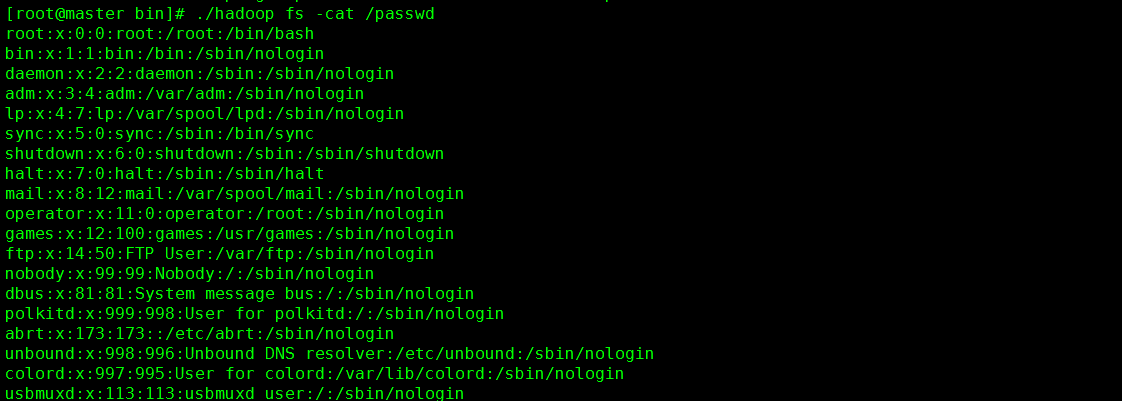
../hadoop fs -put /etc/passwd /
./hadoop fs -ls /
./hadoop fs -act /passwd
Hadoop集群安装完毕。