Google的gperftool是一款非常好用的服务器程序性能分析工具,能提供非常直观和相对准确的性能数据,让开发者可以进行更有方向能的优化。关于工具的使用方法,用gperftool作关键字搜索,会有很多的结果,这里就不多讲了。本文的重点在于深入到工具源码的内部,了解一下这个工具的实现原理和数据格式,然后介绍一下我从事的一个商业项目集成使用这个工具的一点小技巧。
-
工作原理
这一部分会重点解答这么几个问题:
1、这个工具是如何收集程序的性能数据的?
2、这个工具使用的时候,不需要在产品代码中插入任何的额外代码,那么它怎么能知道哪个函数执行了多长时间呢?
3、工具的介绍上说,这个工具不工作的时候,对目标程序的执行性能几乎没有任何影响。可信吗?几乎没影响到底是多大的影响?产品能接受这样的影响吗?
如果上面三个问题你已经能非常清楚地解答了,那这篇文章你可以直接跳到最后一部分:项目应用小技巧那里了,看看这个技巧对你是不是有点用处。
废话少说,直接到工具的源码中去找答案吧。考虑到贴太多的代码在这里容易迷失在不必要的细节里,我这里就只放最核心的功能代码了,为了让逻辑看上去更清晰,下面贴出的代码都删除了一些错误检查类的容错代码。
extern “C” PERFTOOLS_DLL_DECL int ProfilerStart(const char* fname) {
return CpuProfiler::instance_.Start(fname, NULL);
}
bool CpuProfiler::Start(const char* fname, const ProfilerOptions* options) {
collector_.Start(fname, collector_options);
// Setup handler for SIGPROF interrupts
EnableHandler();
return true;
}CpuProfiler启动的时候,核心功能就是启动数据收集器(collector_),这个数据收集器的Start函数的功能就是初始化数据收集需要的数据结构,并创建数据收集文件:
bool ProfileData::Start(const char* fname, const ProfileData::Options& options) {
// Open output file and initialize various data structures
int fd =open(fname, O_CREAT | O_WRONLY | O_TRUNC, 0666);
start_time_ = time(NULL);
fname_ = strdup(fname);
// Reset counters
num_evicted_ = 0;
count_ = 0;
evictions_ = 0;
total_bytes_ = 0;
hash_ = new Bucket[kBuckets];
evict_ = new Slot[kBufferLength];
memset(hash_, 0, sizeof(hash_[0]) * kBuckets);
// Record special entries
evict_[num_evicted_++] = 0; // count for header
evict_[num_evicted_++] = 3; // depth for header
evict_[num_evicted_++] = 0; // Version number
CHECK_NE(0, options.frequency());
int period =1000000/ options.frequency();
evict_[num_evicted_++] = period; // Period (microseconds)
evict_[num_evicted_++] = 0; // Padding
out_ = fd;
return true;
}然后就是开启了CpuProfiler的一个处理函数,而这个函数做的事情就是把prof_handler这个函数注册到了某个地方。
void CpuProfiler::EnableHandler() {
prof_handler_token_ = ProfileHandlerRegisterCallback(prof_handler, this);
}注册这个函数是干什么用的呢?
ProfileHandlerToken* ProfileHandlerRegisterCallback(
ProfileHandlerCallback callback, void* callback_arg) {
return ProfileHandler::Instance()->RegisterCallback(callback, callback_arg);
}好吧,看来功能都在ProfileHandler里面了。ProfileHandler又是一个单例类,来看它的构造函数:
ProfileHandler::ProfileHandler() {
timer_type_ = (getenv(“CPUPROFILE_REALTIME”) ? ITIMER_REAL : ITIMER_PROF);
signal_number_ = (timer_type_ == ITIMER_PROF ? SIGPROF : SIGALRM);
// Get frequency of interrupts (if specified)
char junk;
constchar* fr =getenv(“CPUPROFILE_FREQUENCY”);
if (fr != NULL && (sscanf(fr, "%u%c", &frequency_, &junk) == 1) && (frequency_ > 0)) {
// Limit to kMaxFrequency
frequency_ = (frequency_ > kMaxFrequency) ? kMaxFrequency : frequency_;
} else {
frequency_ = kDefaultFrequency;
}
// Install the signal handler.
structsigaction sa;
sa.sa_sigaction = SignalHandler;
sa.sa_flags = SA_RESTART | SA_SIGINFO;
sigemptyset(&sa.sa_mask);
sigaction(signal_number_, &sa, NULL);
}这个构造函数,根据环境变量CPUPROFILE_REALTIME的配置,来决定让SIGPROF还是SIGALRM信号来触发SignalHandler信号处理函数,并根据环境变量CPUPROFILE_FREQUENCY的配置来设置自己的一个频率变量 frequency_,如果没有设置,就使用默认值,这个默认值是100,而最大值是4000.
然后ProfileHandler的RegisterCallback函数的实现如下:
ProfileHandlerToken* ProfileHandler::RegisterCallback(ProfileHandlerCallback callback, void* callback_arg) {
ProfileHandlerToken* token = new ProfileHandlerToken(callback, callback_arg);
SpinLockHolder cl(&control_lock_);
DisableHandler();
{
SpinLockHolder sl(&signal_lock_);
callbacks_.push_back(token);
}
// Start the timer if timer is shared and this is a first callback.
if ((callback_count_ == 0) && (timer_sharing_ == TIMERS_SHARED)) {
StartTimer();
}
++callback_count_;
EnableHandler();
return token;
}这个函数就如其函数名字,把指定的回调函数添加到callbacks_里面去,然后在加入第一个callback的时候调用StartTimer()函数来启动定时器,然后调用EnableHander函数来开启回调。StartTimer()的实现如下:
void ProfileHandler::StartTimer() {
struct itimerval timer;
timer.it_interval.tv_sec = 0;
timer.it_interval.tv_usec = 1000000 / frequency_;
timer.it_value = timer.it_interval;
setitimer(timer_type_, &timer, 0);
}而EnableHandler()的实现如下:
void ProfileHandler::EnableHandler() {
struct sigaction sa;
sa.sa_sigaction = SignalHandler;
sa.sa_flags = SA_RESTART | SA_SIGINFO;
sigemptyset(&sa.sa_mask);
const int signal_number = (timer_type_ == ITIMER_PROF ? SIGPROF : SIGALRM);
RAW_CHECK(sigaction(signal_number, &sa, NULL) == 0, "sigprof (enable)");
}好了,到这里,这个工具的基本工作原理已经可以猜出个大概了。它用setitimer启动一个系统定时器,这个定时器会每秒钟执行触发frequency次SIGPROF或者SIGALRM信号,从而去触发上面注册的信号处理函数。那么猜想,信号处理函数里面应该会用backtrace去检查一下目标程序执行到什么位置了。那么继续看信号处理函数里面都做了些什么事情吧。
void CpuProfiler::prof_handler(int sig, siginfo_t*, void* signal_ucontext, void* cpu_profiler) {
CpuProfiler* instance = static_cast<CpuProfiler*>(cpu_profiler);
if (instance->filter_==NULL||(*instance->filter_)(instance->filter_arg_)) {
void* stack[ProfileData::kMaxStackDepth];
stack[0] = GetPC(*reinterpret_cast<ucontext_t*>(signal_ucontext));
int depth = GetStackTraceWithContext(stack +1, arraysize(stack) -1, 3, signal_ucontext);
void**used_stack;
if (depth >0&& stack[1] == stack[0]) {
// in case of non-frame-pointer-based unwinding we will get
// duplicate of PC in stack[1], which we don’t want
used_stack = stack + 1;
} else {
used_stack = stack;
depth++; // To account for pc value in stack[0];
}
instance->collector_.Add(depth, used_stack);
}
}果然是获取backtrace,然后记录到colloector_里面去。另外这里为了让代码逻辑看起来更清晰,没有贴出来源代码中的大段注释,那些注释详细解释了对stack数组下标的那几个加减值,感兴趣的话可以自行前往源代码去进一步阅读。
到此为止,本文开头的三个问题都可以有答案了。
1、这个工具是用系统定时器定时产生信号的方式,在信号处理函数里面获取当前的调用堆栈来确定当前落在哪个函数里面的。获取频率默认是每10ms采样一次,参数是可调的,但是最大频率是4000,也就是支持的最小采样间隔是250微秒;
2、这个工具获取到的性能数据是基于统计数据的,也就是他并不真正跟踪函数的每一次调用过程,而是均匀地采样并记录采样点所落在的函数调用位置,用这些统计数据来计算每个函数的执行时间占比。这个数据并不是准确的数据,但是只要运行时间相对比较长,统计数据还是能比较准确地说明问题的。而这也是为什么说这个工具是比较好的服务器程序性能分析工具,而对一些客户端程序,比如游戏客户端并不是非常合适。因为游戏客户端上,相比长时间的统计数据,它们通常更加关心的是某些帧内的具体负载情况。
3、这个工具不工作的时候,就会把系统定时器取消掉,不会定时产生中断信号,不会触发中断处理程序,所以对运行程序的影响真的是很小,运行效率上可以说完全没有影响。而对产品的影响只是多占用一些链接profiler库的内存而已。
-
收集器中的数据格式
先来看ProfileData类中相关的结构定义:
static const int kAssociativity =4; // For hashtable
static const int kBuckets =1<<10; // For hashtable
static const int kBufferLength =1<<18; // For eviction buffer
// Type of slots: each slot can be either a count, or a PC value
typedef uintptr_t Slot;
// Hash-table/eviction-buffer entry (a.k.a. a sample)
struct Entry {
Slot count; // Number of hits
Slot depth; // Stack depth
Slot stack[kMaxStackDepth]; // Stack contents
};
// Hash table bucket
struct Bucket {
Entry entry[kAssociativity];
};使用这些结构的成员如下:
Bucket* hash_; // hash table
Slot* evict_; // evicted entries
int num_evicted_; // how many evicted entries?创建代码:
hash_ = new Bucket[kBuckets]; //长度1024的hash表
evict_ = new Slot[kBufferLength]; //256K的移除buffer
memset(hash_, 0, sizeof(hash_[0]) * kBuckets);
// Record special entries
evict_[num_evicted_++] = 0; // count for header
evict_[num_evicted_++] = 3; // depth for header
evict_[num_evicted_++] = 0; // Version number
CHECK_NE(0, options.frequency());
int period =1000000/ options.frequency();
evict_[num_evicted_++] = period; // Period (microseconds)
evict_[num_evicted_++] = 0; // Padding收集数据的逻辑:
//1. Make hash-value
Slot h = 0;
for (int i =0; i < depth; i++) {
Slot slot = reinterpret_cast<Slot>(stack[i]);
h = (h << 8) | (h >> (8*(sizeof(h)-1)));
h += (slot * 31) + (slot * 7) + (slot * 3);
}
count_++;
//2. See if table already has an entry for this trace
bool done =false;
Bucket* bucket = &hash_[h % kBuckets];
for (int a =0; a < kAssociativity; a++) {
Entry* e = &bucket->entry[a];
if (e->depth== depth) {
bool match =true;
for (int i =0; i < depth; i++) {
if (e->stack[i] !=reinterpret_cast<Slot>(stack[i])) {
match = false;
break;
}
}
if (match) {
e->count++;
done = true;
break;
}
}
}
// 3.
if (!done) {
// Evict entry with smallest count
Entry* e = &bucket->entry[0];
for (int a =1; a < kAssociativity; a++) {
if (bucket->entry[a].count< e->count) {
e = &bucket->entry[a];
}
}
if (e->count>0) {
evictions_++;
Evict(*e);
}
// Use the newly evicted entry
e->depth = depth;
e->count = 1;
for (int i =0; i < depth; i++) {
e->stack[i] = reinterpret_cast<Slot>(stack[i]);
}
}可以看到,它使用了长度为1024的Bucket数组来存放性能收集的记录,每个Bucke能最多存放四条hash冲突的记录。
拿到性能记录之后,第一步先对记录中的backtrace计算hash值,hash值模余1024确定存储该条记录使用的Bucket,然后在Bucket的四个位置中查看能不能找到一个完全一样的backtrace,如果能找到,就直接在这个位置上累加计数;如果找不到,说明遇到了一个全新的backtrace,那么就在四个位置中找一个当前计数最少的位置来存储当前的记录。如果目标位置原来没有计数,那就直接当做一条新的记录添加进去,而如果目标位置处已经有计数了,说明当前的Bucket已经满了,那么就把当前位置处的记录驱逐到evict_数组中,而把新的记录保存到当前的位置上。
驱逐逻辑的代码是这样的:
void ProfileData::Evict(const Entry& entry) {
const int d = entry.depth;
const int nslots = d +2; // Number of slots needed in eviction buffer
if (num_evicted_ + nslots > kBufferLength) {
FlushEvicted();
assert(num_evicted_ ==0);
assert(nslots <= kBufferLength);
}
evict_[num_evicted_++] = entry.count;
evict_[num_evicted_++] = d;
memcpy(&evict_[num_evicted_], entry.stack, d *sizeof(Slot));
num_evicted_ += d;
}如果当前evict_数组已经放不下当前的记录了,那就先用FlushEvicted方法把当前的内容都写入到文件中去,然后清空当前的evict_数组,从头开始放这些被驱逐出来的记录。结合初始化的时候注释为“Record special entries”的代码块,可以看到,写入到文件中的结构是开头的固定的五个slot的文件头,slot的大小取决于目标程序是32位的还是64位的,然后后面会跟着多块采样数据,每块数据都是固定的两个slot分别存放采样点命中的次数和backtrace的深度,然后后面跟着可变长度的N个PC值,N由backtrace的深度值来决定,每个Bucket中的Entry的结构与此也是一样的,而Bucket中的Entry,是在性能数据收集完成之后,统一Flush到文件中。在所有采样点数据dump完成之后,会用三个slot来作为数据结束的标记,分别设置为0,1,0,最后还会把当前进程的maps信息输出到最终的文件中。输出maps信息的作用,是帮助后期定位到某个PC值来源于哪个动态链接库,并可以根据偏移量来取得它对应的函数名。
void ProfileData::Stop() {
if (!enabled()) {
return;
}
// Move data from hash table to eviction buffer
for (int b =0; b < kBuckets; b++) {
Bucket* bucket = &hash_[b];
for (int a =0; a < kAssociativity; a++) {
if (bucket->entry[a].count>0) {
Evict(bucket->entry[a]);
}
}
}
if (num_evicted_ +3> kBufferLength) {
// Ensure there is enough room for end of data marker
FlushEvicted();
}
// Write end of data marker
evict_[num_evicted_++] = 0; // count
evict_[num_evicted_++] = 1; // depth
evict_[num_evicted_++] = 0; // end of data marker
FlushEvicted();
// Dump “/proc/self/maps” so we get list of mapped shared libraries
DumpProcSelfMaps(out_);
Reset();
fprintf(stderr, “PROFILE: interrupts/evictions/bytes = %d/%d/%” PRIuS “\n”,
count_, evictions_, total_bytes_);
}下面一张图是dump了一个真实的性能数据,可以来对比验证一下:
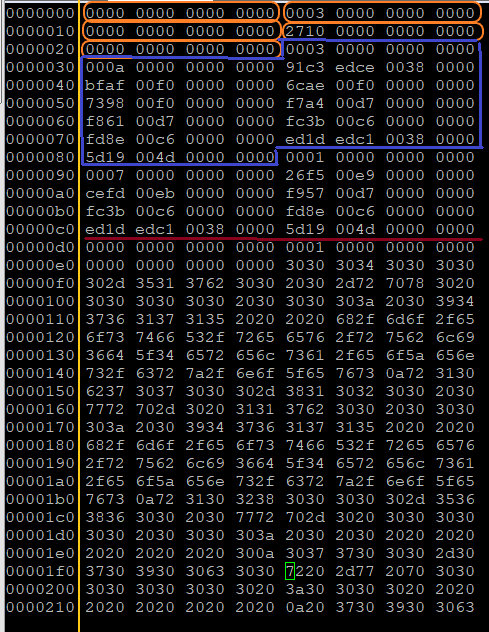
这是一个在64位机器上运行的Linux程序,所以每个slot是8个字节,开始时5个Slot的文件头,其中第四个Slot指示采样的间隔是10000(0x2710)微秒,也就是默认的每秒采样100次。然后后面可以找到两块采样点数据,第一个块命中了三次,backtrace深度是10;第二块命中了一次,backtrace深度是7。然后是值分别为0,1,0的采样数据结束标志。在后面就是ascii字符形式保存的maps文本。结合pprof的文本方式的分析结果,也可以验证我们上面的观察:
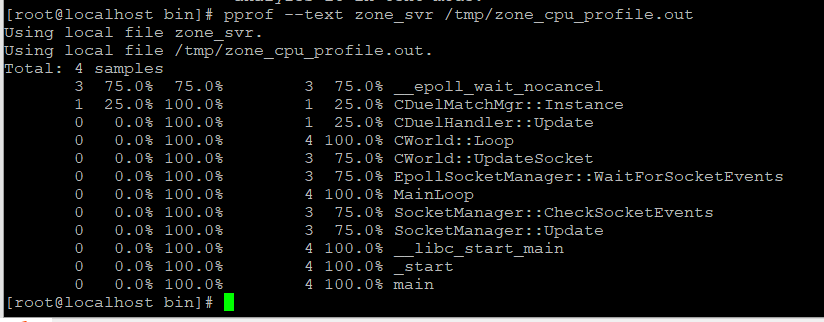
这下文件结构应该很清楚了,甚至pprof分析工具应该如何处理的逻辑也能想出个大概来了。
-
项目应用的小技巧
使用gperftools收集运行数据的时候,需要在需要开始收集的位置调用ProfilerStart(),并在结束收集的时候调用profilerStop(),收集到的数据才会被写入到文件里面去。但是有时我们希望能动态地控制性能数据收集的开始和结束时间,而不想频繁地修改代码中ProfilerStart() 和 ProfilerStop()的插入位置。
有两种方法:
1、在产品中添加自定义信号处理函数,比如可以分别在SIGUSR1和 SIGUSR2信号的处理函数中执行ProfilerStart()和ProfilerStop(),使用的时候用kill程序发送指定的信号来开启和结束数据收集就可以了;
2、产品中启动一个专门监听外部命令的线程,接收到指定命令时开启和结束性能收集。比如监听一个本地Socket,在这个socket上接收到命令时就执行,并把输出也都反馈到这个本地socket中去。这样只要再写另外一个简单的读写这个socket的小程序,就可以很方便地实现动态控制服务器进程的效果。
易用性上的考虑,推荐使用第二种方法。这样可以根据自己的需要灵活扩展这个监听线程的功能,控制客户端工具也能做到非常人性化的交互接口。监听线程还可以扩展很多其他的调试或监控功能能,而这个线程在没有命令需求的时候,只是阻塞在一个Socket监听事件上,对产品的运行没有任何其他影响。
对CPUProfiler的分析就到这里了,后面还会整理一个队TCMalloc的源码级分析,看看google是如何加速多线程应用的内存分配性能的,敬请期待。
任何问题,欢迎在评论区留言讨论。