HTTP作为这个网络协议,有很多关键的值得我们去细细思考的地方,包括如何跨墙,如何通过缓存机制等减少服务器压力和提高访问速度等。
5.1 代理的作用
一、提高访问速度。因为客户要求的数据存于代理服务器的硬盘中,因此下次这个客户或其它客户再要求相同目的站点的数据时,就会直接从代理服务器的硬盘中读取,代理服务器起到了缓存的作用,对热门站点有很多客户访问时,代理服务器的优势更为明显。
二、Proxy可以起到防火墙的作用。因为所有使用代理服务器的用户都必须通过代理服务器访问远程站点,因此在代理服务器上就可以设置相应的限制,以过滤或屏蔽掉某些信息。这是局域网网管对局域网用户访问范围限制最常用的办法,也是局域网用户为什么不能浏览某些网站的原因。拨号用户如果使用代理服务器,同样必须服从代理服务器的访问限制,除非你不使用这个代理服务器。
三、通过代理服务器访问一些不能直接访问的网站。互联网上有许多开放的代理服务器,客户在访问权限受到限制时,而这些代理服务器的访问权限是不受限制的,刚好代理服务器在客户的访问范围之内,那么客户通过代理服务器访问目标网站就成为可能。国内的高校多使用教育网,不能出国,但通过代理服务器,就能实现访问因特网,这就是高校内代理服务器热的原因所在。
四、安全性得到提高。无论是上聊天室还是浏览网站,目的网站只能知道你来自于代理服务器,而你的真实IP就无法测知,这就使得使用者的安全性得以提高。
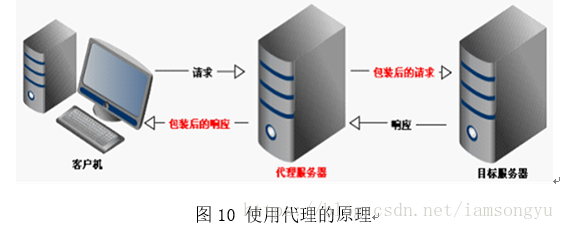
实际上代理是通过其他的服务器帮助浏览器访问一些网站,所以就可以绕过一些问题,大概的方式如下图所示:
代理服务器工作流程大致如下
1.当客户端A对web服务器请求时,此端提出请求时,此请求会首先发送到代理服务器.
2.代理服务器接收到客户端请求后,会检查缓存中是否存有客户端所需要的数据.
3.如果代理服务器没有客户端A所请求的数据,它将会向WEB器提交请求.
4.WEB服务器响应请求的数据.
5.代理服务器向客户端A转发Web服务器的数据.
6.客户端B访问web服务器,向代理服务器发出请求.
7.代理服务器查找缓存记录,确认已经存在WEB服务器的相关数据.
8.代理服务器直接回应查询的信息,而不需要再去服务器进行查询,从而达到节约网络流量和提高访问的速度目的。
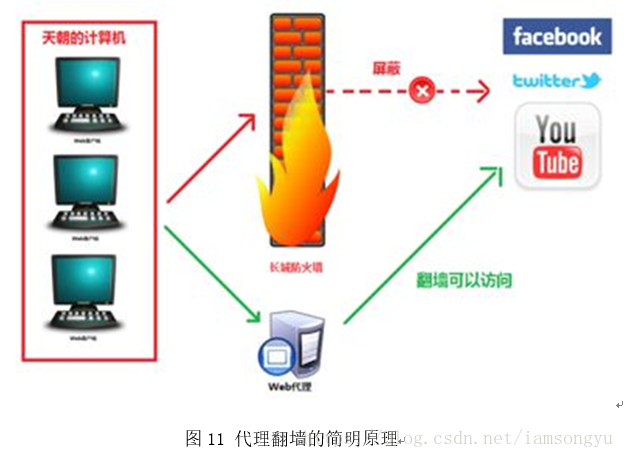
我们需要注意的是,代理可以使国内的服务器代理,用来加快速度,也可以是国外的服务器代理,用来翻墙。而且代理的手段不代表一定是将服务器直接与往外项相连,也可以是更改请求的头信息,伪装自己。
5.2 缓存机制
这是一个复杂的过程,目的是加快响应和减少服务器的负担。通常在本地的客户浏览器和代理服务器都会有缓存设置,这里简单的以浏览器和服务器模型做简单介绍。
在浏览器第一次进行请求时,会将按返回的数据进行本地缓存。如果服务器设置了Cache-Control或者max-age,Expires字段的过期时间,那么浏览器在这个过期时间内会使用缓存,不会产生新的请求,当超过这个过期时间,浏览器就会向服务器发送请求。但是这只是大概的说法,而且max-age和Expires具体的执行逻辑稍有不同。
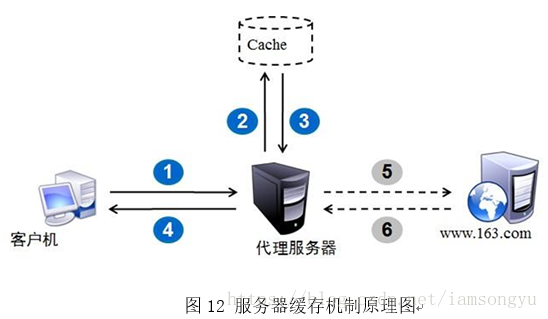
max-age是一个相对的时间,计算的时间是从请求产生文档的时间开始计算,其值为一个时间长度。Expires大多数时间使用的是绝对时间,在该时间之前是不需要进行获取新的网页内容。但是,为了防止在缓存有效期内网站发生了变化,浏览器还是会发送一个包含If-Modified-Since头部的请求。而请求发送到服务器之后,服务器会根据请求头的If-Modified-Since内容来判断这个内容是否在对应时间点之后有更新,如果没有更新那么就返回304以及Last-Modified请求头部,浏览器收到这个头部会更新If-Modified-Since的值,下次发生请求的时候会带上这个新的值;如果发生了更新,那么就会返回200以及更新之后的资源。
5.3 断点续传功能
在HTTP协议中,也支持文件的访问和下载。所谓断点续传,也就是要从文件已经下载的地方开始继续下载。在以前版本的 HTTP 协议是不支持断点的,HTTP/1.1 开始就支持了。一般断点下载时才用到 Range 和 Content-Range 实体头。Accept-Ranges: bytes字段用来指明接受的单位是字节。
Range :用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式:Range:[起始偏移]-[最后偏移位置]
Content-Range:用于响应头,指定整个实体中的一部分的插入位置,他也指示了整个实体的长度。在服务器向客户返回一个部分响应,它必须描述响应覆盖的范围和整个实体长度。一般格式:
Content-Range: bytes (起始位置) - [终点位置]/[整体长度]
请求下载整个文件:
- GET /test.rar HTTP/1.1
- Connection: close
- Host: 116.1.219.219
- Range: bytes=0-801 //一般请求下载整个文件是bytes=0- 或不用这个头
一般正常回应 - HTTP/1.1 200 OK
- Content-Length: 801
- Content-Type: application/octet-stream
- Content-Range: bytes 0-800/801 //801:文件总大小
5.4 保持会话功能
这是HTTP协议所没有的功能,也是现在应用范围广影响特别大的功能,所以本文会重点讲解该部分。在http1.1中request和reponse header中都有可能出现一个connection的头,此header的含义是当client和server通信时对于长链接如何进行处理。
在http1.1中,client和server都是默认对方支持长链接的, 如果client使用http1.1协议,但又不希望使用长链接,则需要在header中指明connection的值为close;如果server方也不想支持长链接,则在response中也需要明确说明connection的值为close.
不论request还是response的header中包含了值为close的connection,都表明当前正在使用的tcp链接在当天请求处理完毕后会被断掉。以后client再进行新的请求时就必须创建新的tcp链接了。达不到我们想要的功能,比如百度网盘登陆一次之后很长一部分时间不需要再次登录,而qq邮箱每次登录都需要重新输入,这其中的功劳来自于Session功能,即会话保持功能。
session的工作原理
1)当一个用户向服务器发送第一个请求时,服务器为其建立一个session,并为此session创建一个标识号;
2 ) 这个用户随后的所有请求都应包括这个标识号。服务器会校对这个标识号以判断请求属于哪个session。
这种机制不使用IP作为标识,是因为很多机器是通过代理服务器方式上网,没法区分每一台机器。一般用来实现Session的方法有两种:
1)URL重写。
Web Server在返回Response的时候,检查页面中所有的URL,包括所有的连接,和HTML Form的Action属性,在这些URL后面加“id=XXX”。下一次,用户访问这个页面中的URL。id就会传回到Web Server。
2)Cookie。
如果客户端支持Cookie,Web Server在返回Response的时候,在Response的Header部分,加入一个“set-cookie: jsessionid=XXXX”header属性,把jsessionid放在Cookie里传到客户端。
客户端会把Cookie存放在本地文件里,下一次访问Web Server的时候,再把Cookie的信息放到HTTP Request的“Cookie”header属性里面,这样jsessionid就随着HTTP Request返回给Web Server。
关于cookie
Cookie 技术诞生以来,它就成了广大网络用户和 Web 开发人员争论的一个焦点。有一些网络用户,甚至包括一些资深的 Web 专家也对它的产生和推广感到不满,这并不是因为 Cookie 技术的功能太弱或其他技术性能上的原因,而是因为 Cookie 的使用对网络用户的隐私构成了危害。因为 Cookie 是由 Web 服务器保存在用户浏览器上的小文本文件,它包含有关用户的信息。
Cookie 技术产生源于 HTTP 协议在互联网上的急速发展。随着互联网的深层次发展,带宽等限制不存在了,人们需要更复杂的互联网交互活动,就必须同服务器保持活动状态。于是,在浏览器发展初期,为了适应用户的需求,技术上推出了各种保持 Web 浏览状态的手段,其中就包括了 Cookie 技术。1993 年,网景公司雇员 Lou Montulli 为了让用户在访问某网站时,进一步提高访问速度,同时也为了进一步实现个人化网络,发明了今天广泛使用的 Cookie 。
Cookie 可以翻译为“小甜品,小饼干” ,Cookie 在网络系统中几乎无处不在,当我们浏览以前访问过的网站时,网页中可能会出现 :你好 XXX,这会让我们感觉很亲切,就好像吃了一个小甜品一样。这其实是通过访问主机中的一个文件来实现的,这个文件就是 Cookie。在 Internet 中,Cookie 实际上是指小量信息,是由 Web 服务器创建的,将信息存储在用户计算机上的文件。一般网络用户习惯用其复数形式 Cookies,指某些网站为了辨别用户身份、进行 Session 跟踪而存储在用户本地终端上的数据,而这些数据通常会经过加密处理。
Cookie 在计算机中是个存储在浏览器目录中的文本文件,当浏览器运行时,存储在 RAM 中发挥作用 (此种 Cookies 称作 Session Cookies),一旦用户从该网站或服务器退出,Cookie 可存储在用户本地的硬盘上 (此种 Cookies 称作 Persistent Cookies)
通常情况下,当用户结束浏览器会话时,系统将终止所有的 Cookie。当 Web 服务器创建了Cookies 后,只要在其有效期内,当用户访问同一个 Web 服务器时,浏览器首先要检查本地的Cookies,并将其原样发送给 Web 服务器。这种状态信息称作“Persistent Client State HTTP Cookie” ,简称为 Cookies 。
5.5 GET和POST请求的区别
Http协议定义了很多与服务器交互的方法, GET一般用于获取/查询资源信息,而POST一般用于更新资源信息,这两者有部分相同的作用,也有很大的区别我们看看GET和POST的多方面的比较。
GET请求:
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
注意最后一行是空行
POST请求:
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
1、 附加信息方式:
GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:
login.actionname=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。
如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
2、传输数据的大小:
首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。因此对于GET提交时,传输数据就会受到URL长度的 限制。
POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
2、 安全性
POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
二者也有很多的区别,将其列在下:
1.GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2.GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3.GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4.GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.