python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
需要安装这2个库,安装的方式有多重可以直接使用pip安装(根据自己的需求安装):
如pip安装
pip3 install xlrd
pip3 install xlwt
读excel-->xlrd
自己先建一个excel表格内容如下:

有上面的Excel表格知道里面有2个sheet,其中第一个sheet1有内容,sheet2没有内容
下面是关于python对Excel读的基本操作:


import xlwt, xlrd from datetime import date, datetime # 打开excel文件,创建一个workbook对象,book对象也就是fruits.xlsx文件,表含有sheet名 workbook = xlrd.open_workbook(r'C:\Users\PC\Desktop\sss.xlsx') print(workbook.sheet_names()) # 得到一个列表里面的元素就是sheet的名字 # 上面执行的结果为['Sheet1', 'Sheet2'] print(workbook.sheets()) # 得到的是一个列表里面的元素就是每一个sheet对象 # 上面执行的结果为[<xlrd.sheet.Sheet object at 0x0000019BB9D915C0>, <xlrd.sheet.Sheet object at 0x0000019BB9D91128>] sheet_name = workbook.sheet_names()[0] # 从零开始,取第一个sheet的名字 sheet_obj = workbook.sheets()[0] # 从零开始取第一个sheet对象 print(sheet_name, sheet_obj) # 上面执行的结果为:Sheet1 <xlrd.sheet.Sheet object at 0x000001E620A7CBE0> # 根据sheet索引或者名称获取sheet内容 rsheet = workbook.sheet_by_index(0) # 取第一个工作簿根据索引 rsheet_name = workbook.sheet_by_name(sheet_name) # 根据sheet的名字取第一个工作簿 print('rsheet_index', rsheet) print('rsheet_name', rsheet_name) # 获取总行数,列数和名字根据sheet的内容也就是上面的rsheet或者rsheet_name print(rsheet.nrows, rsheet.ncols, rsheet.name) rows = rsheet.nrows # 获取总列数 cols = rsheet.ncols # sheet名称 sheet_name = rsheet.name # 获取整行和整列的值 rows2_values = rsheet.row_values(1) # 获取第二行内容,得到的是一个列表 cols3_values = rsheet.col_values(2) # 获取第三列内容,得到的是一个列表 print(rows2_values, cols3_values) # ['小杰', 23.0, 33919.0, '键盘', '朋友'] ['出生日期', 33919.0, 33920.0, 33921.0, 33922.0, 33923.0, '暂无'] # 通过cell的位置坐标取得cell值的几种方式 print('获取第二行第一列的值', rsheet.cell(1, 0).value) print('获取第二行第一列的值', rsheet.cell_value(1, 0)) print('获取第二行第一列的值', rsheet.row(1)[0].value) # 获取单元格内容的数据类型 print(rsheet.cell(1, 0).ctype)
运行结果如下
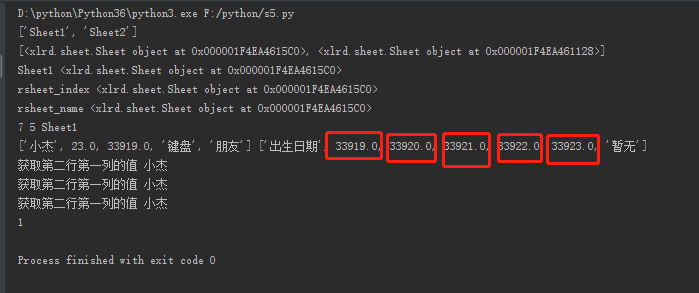
可以看到上面的日期这里列在表格中明明写的是日期在这里是浮点数。那让我们来解决这一个问题:

1、python读取excel中单元格内容为日期的方式
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
即date的ctype=3,这时需要使用xlrd的xldate_as_tuple来处理为date格式,
先判断表格的ctype=3时xldate才能开始操作。继续上面的代码:
# 关于单元格里面时间格式的转换 print(rsheet.cell(2, 0).ctype) # 结果为1(字符) print(rsheet.cell(2, 1).ctype) # 结果为2(数字) print(rsheet.cell(2, 2).ctype) # 结果为3(日期) print(rsheet.cell(2, 3).ctype) # 结果为1(字符) print(rsheet.cell(2, 4).ctype) # 结果为0(空值) 这个是因为合并单元格的原因 print(rsheet.cell(2, 2).value) # 打印的是一个浮点数 # 结果为 33920.0 print(xlrd.xldate_as_tuple(rsheet.cell(2, 2).value, workbook.datemode)) # 转化为一个我们能够看得懂的元组 # 结果为 (1992, 11, 12, 0, 0, 0) date_tuple = xlrd.xldate_as_tuple(rsheet.cell(2, 2).value, workbook.datemode) date_time = date(*date_tuple[:3]).strftime('%Y/%m/%d') # 转换为正常的日期格式 print(date_time) # 1992/11/12 # 有上面我们可以简单地判断是不是时间如果是时间就做转换 row = 2 # 这个可以改成你想要的行数 col = 2 # 这个可以改成你想要的列数 if (rsheet.cell(row, col).ctype == 3): date_value = xlrd.xldate_as_tuple(rsheet.cell_value(rows, col), workbook.datemode) date_tmp = date(*date_value[:3]).strftime('%Y/%m/%d')
那么问题又来了,上面 rsheet.cell(2,4).ctype 返回的值是0,说明这个单元格的值是空值,明明是合并的单元格内容"好朋友",这个是我觉得这个包功能不完善的地方,如果是合并的单元格那么应该合并的单元格的内容一样,但是它只是合并的第一个单元格的有值,其它的为空。
2、读取合并单元格的内容:
这个是真没技巧,只能获取合并单元格的第一个cell的行列索引,才能读到值,读错了就是空值。
即合并行单元格读取行的第一个索引,合并列单元格读取列的第一个索引,如上述,读取行合并单元格"好朋友"和读取列合并单元格"暂无"只能如下方式:
# 关于合并单元格里面里面的空值 # 如: print(rsheet.cell(2, 4).ctype) # 结果为0(空值) 这个是因为合并单元格的原因 # 明明这里是合并单元格应该显示好朋友的 # 读取合并单元格的内容 print(rsheet.col_values(4)[1]) # 结果为朋友 print(rsheet.col_values(4)[2]) # 这个是合并的行如果读取就是空值 print(rsheet.row_values(6)[2]) # 结果为暂无 print(rsheet.row_values(6)[3]) # 这个是合并的列如果读取就是空值 print(rsheet.merged_cells) # 结果为[(6, 7, 2, 5), (1, 3, 4, 5), (3, 6, 4, 5)] # 上面的的(6, 7, 2, 5)这个元组里面的元素分别为(row,row_range,col,col_range) # (row,row_range)表示为包含row但是不包含row_range。上面可以解读为 # 因为是从零开始计数的所以可以这样说第七行(数字为6)的第三列(数字为2)到第五列(数字为4)合并 # 有上面的规律我们可以使用以下方式获取合并单元格的内容 # 这样我们就可以使用以下的方式获取合并的单元格的信息, merge = [] for (rlow, rhigh, clow, chigh) in rsheet.merged_cells: merge.append([rlow, clow]) for index in merge: print(rsheet.cell_value(index[0], index[1])) # 有上面我们知道列合并我们可以看到该行的合并的第一列的内容就是合并列的内容其他的就不是这个内容。 # 为了准确的获得合并单元格的内容我们可以使用上面的方式获得
写excel-->xltw
#!/usr/bin/env python # -*-coding:utf-8-*- import xlwt, xlrd f = xlwt.Workbook() # 创建一个工作簿 sheet1 = f.add_sheet('sheet1', cell_overwrite_ok=True) # 创建sheet row0 = ["姓名", "年龄", "出生日期", "爱好"] column0 = ["张三", "李四", "王五"] # 生成第一行 for i in range(0, len(row0)): sheet1.write(0, i, row0[i]) # 第一个参数表示的是行,第二个参数表示的列,第三个表示的是数据 for i in range(0, len(column0)): sheet1.write(i + 1, 0, column0[i]) # 给第二行的人物加信息 sheet1.write(1, 1, 23) sheet1.write(1, 2, '1993/04/22') sheet1.write(1, 3, '足球') f.save('test.xls')
上面这个只是写入一个新的不能够对已有的Excel表格进行修改
OpenPyXL
由于xlrd不能对已存在的xlsx文件,进行修改!所以必须使用OpenPyXL
OpenPyXL:较好的支持对xlsx文件的修改,功能比较强大,适用于需要处理XLSX文件,需要修改XLSX文件中的值,最后生成xlsx。openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易
注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode。
官网上最推荐的是openpyxl:
综上,所以选择使用OpenPyX来做一个修改excel的小程序。
OpenPyXL的官网参考:
https://openpyxl.readthedocs.io/en/latest/usage.html
https://openpyxl.readthedocs.io/en/stable/
1、OpenPyXL模块的安装
pip3 install OpenPyXL
2、快速实现xlsx文件的单元格修改
举例:增加一列地区,并增加相应的值,并且修改某一个人的出生日期
from openpyxl import load_workbook # excel文件绝对路径 file_home = r'C:\Users\PC\Desktop\sss.xlsx' wb = load_workbook(filename=file_home) # 打开excel文件 sheet_ranges = wb['Sheet1'] print(sheet_ranges['A1'].value) # 打印A1单元格的值 ws = wb['Sheet1'] # 根据Sheet1这个sheet名字来获取该sheet # 添加一栏为地区,并且给上数据 ws["F1"] = '地区' # 修改C1的值为LJK5679842 ws['F2'] = '湖北' ws['F3'] = '云南' ws['F4'] = '湖南' ws['F5'] = '北京' ws['F6'] = '江苏' # 修改小明的出生日期 ws['c3'] = '1991/11/12' wb.save(file_home) # 保存修改后的excel
执行前的excel表格

执行后的Excel表格
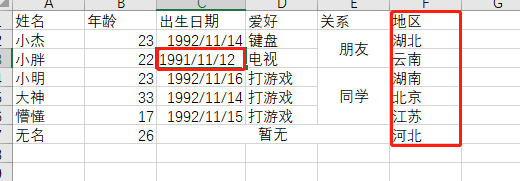
可以看到上面增加和修改的数据。