文章首发于微信公众号《与有三学AI》
【模型解读】从LeNet到VGG,看卷积+池化串联的网络结构
从本篇开始,我们将带领大家解读深度学习中的网络的发展
01 这是深度学习模型解读第一篇,本篇我们将介绍LeNet,AlexNet,VGGNet,它们都是卷积+池化串联的基本网络结构。
01 LeNet5
LeNet5【1】有3个卷积层,2个池化层,2个全连接层。卷积层的卷积核都为5*5,stride=1,池化层都为Max pooling,激活函数为Sigmoid,具体网络结构如下图:
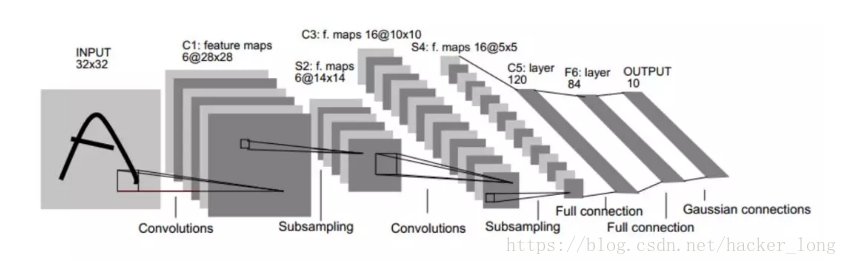
下面我们详细解读一下网络结构,先约定一些称呼。
我们先约定一些叫法,比如featuremap为28*28*6,卷积参数大小为(5*5*1)*6。其中28*28是featuremap的高度,宽度,6是featuremap的通道数。(5*5*1)*6卷积核表示5*5的高度,宽度,通道数为1的卷积核有6个。你可以把(5*5*1)想象成一个厚度为1,长度,宽度各为5的卷积块,以下依此类推。
1.Input
输入图像统一归一化为32*32。
2.C1卷积层
经过(5*5*1)*6卷积核,stride=1, 生成featuremap为28*28*6。
3.S2池化层
经过(2*2)采样核,stride=2,生成featuremap为14*14*6。
4.C3卷积层
经过(5*5*6)*16卷积核,stride=1,生成featuremap为10*10*16。
5.S4池化层
经过(2*2)采样核,stride=2,生成featuremap为5*5*16。
6.C5卷积层
经过(5*5*16)*120卷积核,stride=1, 生成featuremap为1*1*120。
7.F6全连接层
输入为1*1*120,输出为1*1*84,总参数量为120*84。
8.Output全连接层 。
输入为1*1*84,输出为1*1*10,总参数量为84*10。10就是分类的类别数。
02 AlexNet
2012年,Imagenet比赛冠军—Alexnet (以第一作者Alex命名)【2】直接刷新了ImageNet的识别率,奠定了深度学习在图像识别领域的优势地位。网络结构如下图:

1.Input
输入图像为227*227*3。
2.Conv1
经过(11*11*3)*96卷积核,stride=4, (227-11)/4+1=55,生成featuremap为55*55*96。
3.Pool1
经过3*3的池化核,stride=2,(55-3)/2+1=27,生成featuremap为27*27*96。
4.Norm1
local_size=5,生成featuremap为27*27*96。
5.Conv2
经过(5*5*96)*256的卷积核,pad=2,group=2,(27+2*2-5)/1+1=27,生成featuremap为27*27*256。
6.Pool2
经过3*3的池化核,stride=2,(27-3)/2+1=13,生成featuremap为13*13*256。
7.Norm2
local_size=5, 生成featuremap为13*13*256。
8.Conv3
经过(3*3*256)*384卷积核,pad=1, (13+1*2-3)/1+1=13,生成featuremap为13*13*384。
9.Conv4
经过(3*3*384)*384卷积核,pad=1,(13+1*2-3)/1+1=13,生成featuremap为13*13*384。
10.Conv5
经过(3*3*384)*256卷积核,pad=1,(13+1*2-3)/1+1=13,生成featuremap为13*13*256。
11.Pool5
经过(3*3)的池化核,stride=2,(13-3)/2+1=6,生成featuremap为6*6*256。
12.Fc6
输入为(6*6*256)*4096全连接,生成featuremap为1*1*4096。
13.Dropout6
在训练的时候以1/2概率使得隐藏层的某些神经元的输出为0,这样就丢掉了一半节点的输出,BP的时候也不更新这些节点,以下Droupout同理。
14.Fc7
输入为1*1*4096,输出为1*1*4096,总参数量为4096*4096。
15.Dropout7
生成featuremap为1*1*4096。
16.Fc8
输入为1*1*4096,输出为1000,总参数量为4096*1000。
总结:
1.网络比LeNet更深,包括5个卷积层和3个全连接层。
2.使用relu激活函数,收敛很快,解决了Sigmoid在网络较深时出现的梯度弥散问题。
3.加入了dropout层,防止过拟合。
4.使用了LRN归一化层,对局部神经元的活动创建竞争机制,抑制反馈较小的神经元放大反应大的神经元,增强了模型的泛化能力。
5.使用裁剪翻转等操作做数据增强,增强了模型的泛化能力。预测时使用提取图片四个角加中间五个位置并进行左右翻转一共十幅图片的方法求取平均值,这也是后面刷比赛的基本使用技巧。
6.分块训练,当年的GPU没有这么强大,Alexnet创新地将图像分为上下两块分别训练,然后在全连接层合并在一起。
7.总体的数据参数大概为240M。
03 VGG
VGGNet【3】主要的贡献是利用带有很小卷积核(3*3)的网络结构对逐渐加深的网络进行评估,结果表明通过加深网络深度至16-19层可以极大地改进前人的网络结构。这些发现也是参加2014年ImageNet比赛的基础,并且在这次比赛中,分别在定位和分类跟踪任务中取得第一名和第二名。
VGGNet的网络结构如下图:
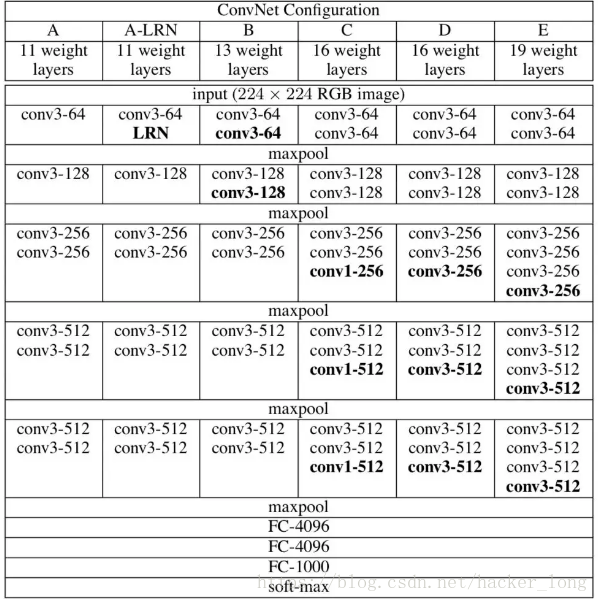
类型从A到E。此处重点讲解VGG16。也就是图中的类型D。如图中所示,共有13个卷积层,3个全连接层。其全部采用3*3卷积核,步长为1,和2*2最大池化核,步长为2。
1.Input层
输入图片为224*224*3。
2.CONV3-64
经过(3*3*3)*64卷积核,生成featuremap为224*224*64。
3.CONV3-64
经过(3*3*64)*64卷积核,生成featuremap为224*224*64。
4.Max pool
经过(2*2)max pool核,生成featuremap为112*112*64。
5.CONV3-128。
经过(3*3*64)*128卷积核,生成featuremap为112*112*128。
6. CONV3-128
经过(3*3*128)*128卷积,生成featuremap为112*112*128。
7.Max pool
经过(2*2)maxpool,生成featuremap为56*56*128。
8.CONV3-256
经过(3*3*128)*256卷积核,生成featuremap为56*56*256。
9.CONV3-256
经过(3*3*256)*256卷积核,生成featuremap为56*56*256。
10.CONV3-256
经过(3*3*256)*256卷积核,生成featuremap为56*56*256。
11.Max pool
经过(2*2)maxpool,生成featuremap为28*28*256
12.CONV3-512
经过(3*3*256)*512卷积核,生成featuremap为28*28*512
13.CONV3-512
经过(3*3*512)*512卷积核,生成featuremap为28*28*512。
14.CONV3-512
经过(3*3*512)*512卷积核,生成featuremap为28*28*512。
15.Max pool
经过(2*2)maxpool,生成featuremap为14*14*512。
16.CONV3-512
经过(3*3*512)*512卷积核,生成featuremap为14*14*512。
17.CONV3-512
经过(3*3*512)*512卷积核,生成featuremap为14*14*512。
18.CONV3-512
经过(3*3*512)*512卷积核,生成featuremap为14*14*512。
19.Max pool
经过2*2卷积,生成featuremap为7*7*512。
20.FC-4096
输入为7*7*512,输出为1*1*4096,总参数量为7*7*512*4096。
21.FC-4096
输入为1*1*4096,输出为1*1*4096,总参数量为4096*4096。
22.FC-1000
输入为1*1*4096,输出为1000,总参数量为4096*1000。
总结:
1. 共包含参数约为550M。
2. 全部使用3*3的卷积核和2*2的最大池化核。
3. 简化了卷积神经网络的结构。
04 总结
LeNet5是早期用于工程应用的网络结构,发展到AlexNet,激活函数从sigmoid变为relu,加入了Dropout层等操作,引起了新一轮的深度学习热潮。VGG基本是AlexNet的加强版,深度上是其2倍,参数量大小也是两倍多。
这三个网络结构本质上都是(卷积+池化)堆叠的网络结构,是深度学习复兴以来的第一个有重大工程意义的网络设计系列。
参考文献
【1】Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
【2】Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
【3】Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
打一个小广告,我在gitchat开设了一些课程和chat,欢迎交流。