参考了代码分析Python requests库中文编码问题一文,自己整理了一部分
1.运行以下代码,结果为乱码
2.运行:print(req.encoding)结果显示ISO-8859-1
之所以会有ISO-8859-1这种编码是因为:
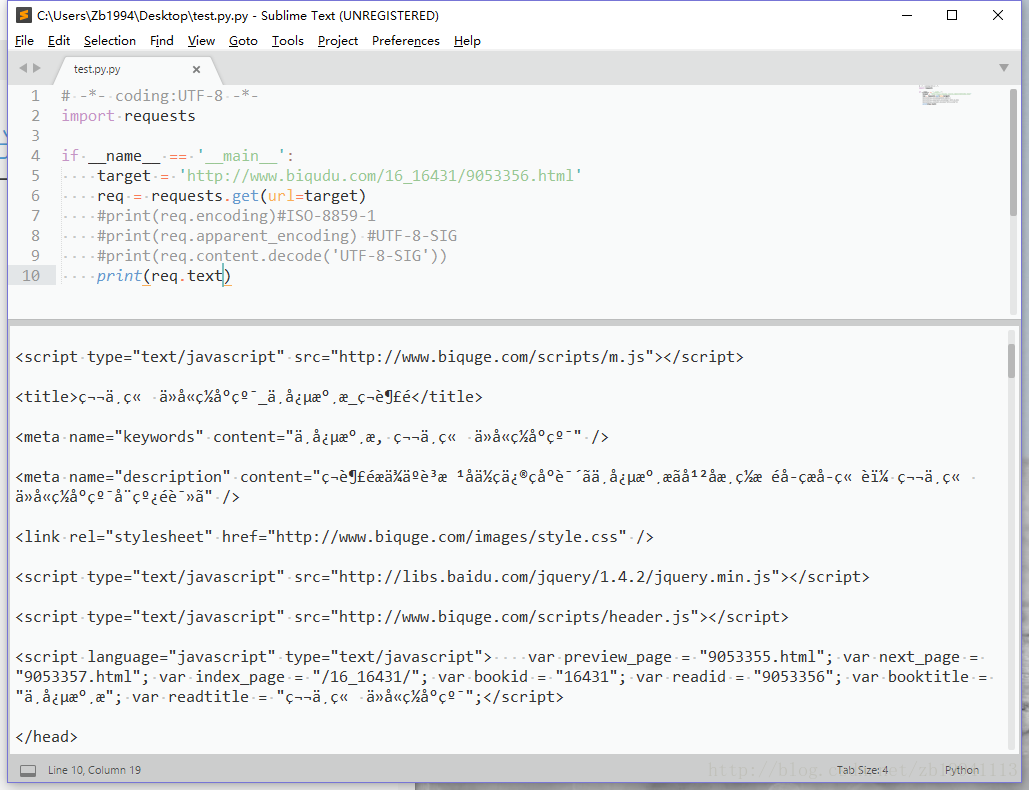
requests会从服务器返回的响应头的 Content-Type 去获取字符集编码,如果content-type有charset字段那么requests才能正确识别编码,否则就使用默认的 ISO-8859-1. 一般那些不规范的页面往往有这样的问题.
3.解决办法:
requests的返回结果对象里有个apparent_encoding函数, apparent_encoding通过调用chardet.detect()来识别文本编码
通过 print(req.apparent_encoding)结果显示UTF-8-SIG
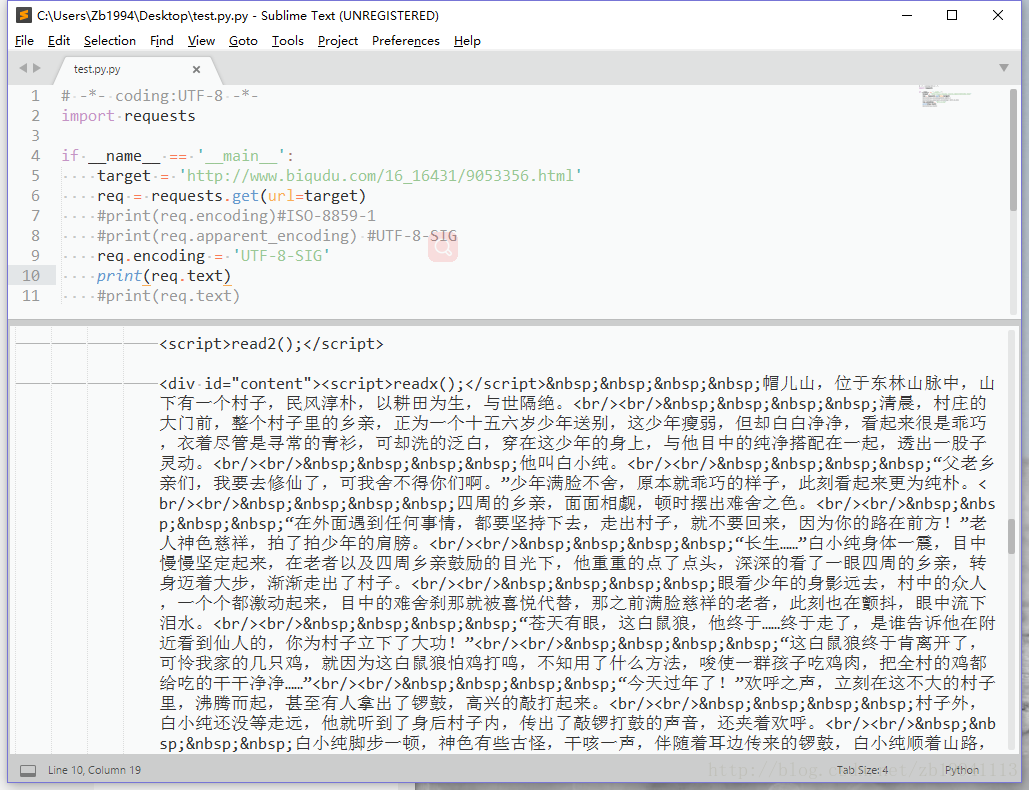
说明本页面使用UTF-8-SIG编码,在明确了网页的字符集编码后可以使用r.encoding = 'UTF-8-SIG' 获取正确结果,如下图所示:
4.关于requests后面跟的text() 与content() 的区别:
r.text返回的是处理过的Unicode型的数据,而使用r.content返回的是bytes型的原始数据。也就是说,r.content相对于r.text来说节省了计算资源,r.content是把内容bytes返回. 而r.text是decode成Unicode. 如果headers没有charset字符集的化,text()会调用chardet来计算字符集。
--------------------- 本文来自 LpJy 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/zb19941113/article/details/78461546?utm_source=copy