第一章 MySQL架构
MySQL最重要的特征是他的存储引擎架构,这种架构可以将查询处理(Query Processing)和各类服务任务(Server Tasks)与数据的存储(Storage)/提取(Retrieval)相分离。在MySQL5.1,甚至支持把存储引擎作为运行时的插件(Runtime Plug-ins)动态加载。这种分离特性使用用户可以基于每张表来选择存储引擎,以满足对数据存储、性能、特征以及其他特性的需要。
本章描述了MySQL服务器架构的总体架构, 各种存储引擎间的主要区别,。
1.1 MySQL的逻辑架构
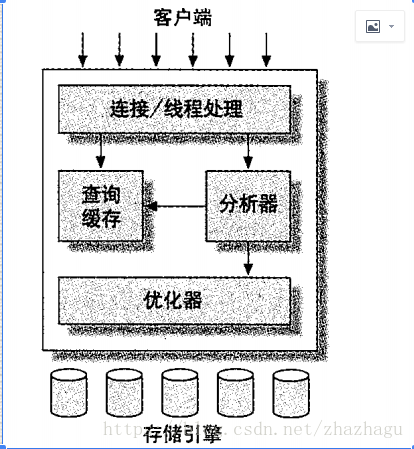
MySQL服务器架构的逻辑视图
最顶层的各种服务并非MySQL独有,是许多基于网络的客户端/服务器(Client/server)工具或服务器都需要的服务,比如链接处理,授权认证、安全等。
第二层包括了MySQL的大多数核心内容,比如查询解析、分析、优化、缓存及所有的内建函数(如时间、日期、数学和加密函数等)的代码。各种存储引擎提供的功能也集中在这层,如存储过程、触发器、视图等。
第三层包含了存储引擎,存储引擎负责存储和提取所有存放在MySQL中的数据。服务器通过存储引擎API(Storage Engine API)与引擎进行通信。该接口隐藏了存储引擎之间的区别,使他们在查询层面上是透明的。API包含几十个底层函数,用来执行相关操作,如开始一个事务,提取拥有某个主键的数据等等。存储引擎不会对SQL进行解析(Parse),也不会相互通信,他们只是简单地响应服务器请求。
1.1.1连接管理与安全性(Connection Management and Security)

每个客户端连接在服务器进程中都拥有属于自己的线程,每个连接所属的查询都会制定在某个单独线程中完成,这些线程轮流运行在某个CPU核心(Core)或者CPU上。服务器负责缓存线程,因此不需要为每个新的链接重建或撤销线程。
当客户端(应用)连接搭配MySQL服务器时,服务器要对其认证(Authenticate),认证方式基于用户名,原始主机 信息和口令。对于安全套接字层(SSL)方式的连接,还使用了X.509证书。一旦某个客户端成功链接服务器,服务器就会验证该客户端是否有权限执行某个具体查询。
1.1.2 优化与执行(Optimization and Execution)
MySQL会解析查询,并创建一个内部数据结构(解析树),然后对其进行各种优化。其中包括重写查询,决定查询的读表顺序,以及选择须使用的索引等。用户可以通过特殊的关键字给优化器(Optimizer)传递各种提示(Hint),影响它的决策过程(Descision-Makeing Process)。另外还可以请求服务器给出优化过程的各种说明,使用户可以知晓服务器是如何进行优化决策的,为用户提供一个参考基准,方便用户重写查询,架构(Schema)和修改相关配置,便于应用尽可能高效地运行。
优化器并不关心某个表使用哪种存储引擎,但存储引擎对服务器的查询优化过程有影响。优化器会请求存储引擎,为某种具体操作提供性能与开销方面的信息,以及表内数据的统计信息。例如,某些存储引擎可以支持对某类查询更为有利的索引类型。
在查询前,服务器会“询问”查询缓存,他只能保存SELECT语句和相应的结果,如果能在缓存中找到要执行的查询,服务器就不必重新解析、优化或重新执行查询,只需直接返回现有结果即可。
1.2 并发控制
只要不止一个查询同时修改数据,都会产生并发控制问题。本章的目的是讨论MySQL在两个层面上的并发控制:服务器层和存储引擎层。本章节只是给出一个概述,描述MySQL如何处理并发读取程序(Concurrent Reader) ,以及并发写入程序(Concurrent Writer).
1.2.1 读锁(Read Lock)/写锁(Write Lock)
在处理并发读和并发写时,系统会使用一套锁系统来解决问题。这种锁系统由两类锁组成。通常称为共享锁(Shared Lock)和排它锁(Exclusive Lock),或者叫读锁(Read Lock)和写锁(Write Lock)。在某一资源上读锁是共享的,或者是互不阻塞的,在同一个时间,多个用户可以读取同一资源,而互不干扰,另外一方面,写锁是排他的,一个写锁会堵塞其他写锁和读锁。
1.2.2 锁粒度
一种提高共享资源并发性的方法就是让锁定对象更有选择性,只锁定部分必须修改数据,而不是所有资源。更理想的方式是,只对修改的数据片精确加锁。任何时间,在给定的资源上,被加锁的数据量越小,就可以允许更多的并发修改,只要相互之间互不冲突即可。
那么这样加锁也会消耗系统资源。每一种锁操作,如获取锁,检查锁是否已删除以及释放锁等,都会增加系统的开销。如果系统花费大量时间来管理锁,而不是读写数据,那么系统整体性能也会因此受到影响。
所谓的锁策略,就是在锁开销和数据安全之间寻求一种平衡,这种平衡也能影响数据性能。大多数数据库服务器没有提供更多的选择,通常都是在表上施加行级锁(Row-Level Locking),并提供种种复杂的手段,在有锁的情况下改善系统的性能。
MySQL提供多种选择。每种MySQL存储引擎都可以实现独有的锁策略(Locking policy)或者锁粒度(Lock Granularitey).在存储引擎设计中锁管理(Lock Management)是一个非常重要的议题。
表锁(Table lock)
MySQL支持大多数基本的锁策略,其中开销最小的锁策略是表锁。当用户对表进行写操作(插入,更新。删除)的时候,用户可以获取一个写锁。在无人写操作的时候用户才能获得读锁,读锁之间是不会相互冲突的。
在特定环境中,表锁可能性能良好。例如READ LOCAL表锁支持某类型的并发操作。另外写锁具有比较高的优先级,即使有读操作用户排在队列中,一个被申请的写锁仍可以排在锁队列的前列(写锁会被安置到读锁之前,而读锁不能排在写锁的前面)。
行级锁(Row locks)
行级锁可以支持最大的并发处理(同时也带来最大的锁开销)。行级锁由存储引擎实现,而不是由MySQL服务器实现,服务器完全不了解存储引擎里面锁的实现方式。
1.3 事务
事务是一组原子性的SQL查询语句,也可以被看做一个工作单元,ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(lsolation)、持久性(Dirability)
1.3.1 隔离级
SQL标准定义4类隔离级,包括一些具体规则,用来限定事务内外那些改变是可见的,那些是不可见的。低级别的隔离级别一般支持更高级别的并发处理,并拥有更低级别的系统开销。(每种存储引擎的隔离级别不尽相同)
西面介绍四种隔离级别:
READ UNCOMMITTED(读取未提交的内容)
在READ UNCOMMITTED隔离级,所有事务都可以“看到“未提交事务的处理结果。在这种级别上,可能会产生很多问题,除非用户真的知道自己在做什么,并有很好的理由这样做。这种隔离级别很少用于实际应用,因为他的性能不会比其他级别好多少,而别的级别还有更多的有点。读取未提交数据,也被称为”脏读“(Dirty Read)
READ COMMITTED(读取未提交内容)
大多数数据库系统默认的隔离级别是READ COMMITTED(读取提交内容)(但不是MySQL默认的)。一个事务在开始时,只能看见已经提交事务所做的改变,一个事务从开始到提交前,所做的任何数据的改变都是不可见的,除非已经提交,这种隔离级别也支持所谓的“不可重复读(Nonrepeatable Read)”。这意味着用户运行同一语句两次,看到结果是不同的。
REPEATABLE READ(可重读)
REPEATABLE READ 隔离级别解决了READ UNCOMMITTED隔离级别导致的问题。他确保同一事务的多实例在并发读取数据时,会“看到同样的数据行”,这会导致另外一个问题“幻读(Phantom Read)”,幻读是指当用户读取某一范围的数据行时,另一事务又在该范围内插入了新行,当用户再读取改范围的数据行时,会发现有新的幻影(Phantom)行。InnoDB和Falco存储引擎通过多版本并发控制(Multiversion Concurrency Control)机制解决了幻读问题。REPEATABLE READ是MySQL默认事务隔离级。
SERIALIZABLE(可串行化)
SERIALIZABLE是最高级别的隔离级,他通过强制事务排序,使之不可能相互冲突,从而解决幻读的问题。简言之,SERIALIZABLE是每个杜的数据行上加锁,在这个级别,可能会导致大量的超时现象和锁竞争(Lock Contention)现象。很少使用这种隔离级别。但是如果应用为例数据的稳定性,需要强制减少并发的话,可以选择这种隔离级别。
ANSI SQL隔离级
| 隔离级 |
脏读可能性 |
不可重复读可能性 |
幻读可能性 |
加锁读 |
| READ UNCOMMITTED |
是 |
是 |
是 |
否 |
| READ COMMITTED |
否 |
是 |
是 |
否 |
| REPEATABLE READ |
否 |
否 |
是 |
否 |
| SERIZLIZABLE |
否 |
否 |
否 |
是 |
1.3.2 死锁(Deadlocks)
死锁只两个或者多个事务在同一资源上相互占用,并请求加锁时,而导致恶性循环现象。当多个事务顺序试图加锁统一资源时,就会产生死锁。任何时间,多个事务同时加锁一个资源,一定会产生死锁。

如果很不幸的每个事物都在处理过程中,都执行了第一个查询,更新了数据行,也加锁了该数据行,接着每个事务都试图更新第二个数据行,却发现此行已经被对方加上锁,然后两个事务都开始等待对方完成,陷入无限等待中,除非外部因素介入,才能解除死锁。
为了解决这个问题,数据库系统实现了各种死锁检测和死锁超时机制。对于更复杂的系统。如InnoDB存储引擎,可以预知循环相关性,并立刻返回错误信息。这种解决方式很有效否则死锁导致很慢的查询。其他的解决方式,是让查询达到一个锁等待时间,然后放弃争用,但是这种方式不够好。目前InnoDB处理死锁的方法是,回滚拥有最少排他行级锁的事务(一种对最易回滚事务的大致估算)。
锁现象和锁顺序是因存储引擎而异的,某些存储引擎可能会因为某些顺序的语句导致死锁,其他的却不会。死锁现象具有双重性:有些是因为真实的数据冲突产生的,无法避免,有些则是因为存储引擎的工作方式导致的。
1.3.3 事务日志(Transaction Logging)
事务日志可以使事务处理过程更加高效,和每次数据更新一次就更新磁盘中表数据的方式不同,存储引擎可以先更新数据在内存中的拷贝(很快),然后存储引擎将修改写入事务日志,位于磁盘上,因此具有持久性(相对较快,因为追加日志导致的写操作,只涉及了磁盘上很小区域上的顺序I/O[Sequential I/O],而替代了写磁盘中表所需要的大量随机I/O[Random I/O]),最后,相关进程会在某个时间把表数据更新到磁盘上。因此大多数存储引擎选用了这种技术,也就是通常说的预写式日志(Write-Ahead Logging),利用两次磁盘写入操作把数据改变写入磁盘。
如果数据更新已写入事务,却还没有写入磁盘的表中,系统发生崩溃,存储引擎就会在重启后恢复相关数据的改变,具体恢复方式因存储引擎而异。
1.3.4 MySQL中的事务 (Trasaction in MySQL)
MySQL DB提供3个事务型存储引擎:InnoDB、NDB Cluster和Falcon。还有几个第三方引擎也支持事务处理,目前最为知名的第三方事务性引擎是solidDB和PBXT。
AUTOCOMMIT(自动提交)
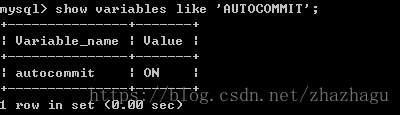
MySQL的默认操作模式是AUTOCOMMIT模式。这意味着除非显示的开始一个事务,否则它将把每个查询视为一个单独事务自动执行。在当前链接中,可以通过变量设置,启动(Enable)和禁用(Disable)AUTOCOMMIT模式。
mysql > SHOW VARIABLES LIKE 'AUTOMCOMMIT';
mysql> SET AUTOCOMMIT = 1;
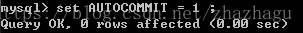
其中值1和ON是等效的,0和OFF是等效的。如果设置AUTOCOMMIT=0,用户将一直处于某个事务中,直到用户执行一条COMMIT或ROLLBACK语句,之后MySQL会立即开始一个新事务。对于一个非事务的表,如MyISAM表或内存表(Memory Table),改变AUTOCOMMIT的值没有意义,这些表本质上一直操作在AUTOCOMMIT模式。
某些命令,在一个活动事务(Open Transaction)中一但执行,会在这些事务显示提交之前,直接触发MySQL立即提交当前事务。典型的例子,如数据定义语言(DDL)命令,可以导致有效的数据改变,如ALTER TABLE命令,另外LOCK TABLES和其他语句也会有这种效果,在MySQL文档中可以获取MySQL自动提交事务的完全命令列表。
MySQL允许使用SET TRANSACTION ISOLATION LEVEL命令设置隔离级,新的隔离级将在下一事务开始后生效。用户也可以在配置文件中,设置整个服务器的隔离级别;或者使用下列命令,设置当前会话的隔离级别。
mysql> SET SESSION TRABNSACTION ISOLATION LEVEL READ COMMITTED;

MySQL可以识别所有的4个ANSI标准隔离级,InnoDB引擎也支持所有的隔离级。其他的存储引擎对隔离级别的支持,则因不同的隔离级别而异。
在事务中混合使用存储引擎
MySQL没有在服务器层管理事务,而是由下一层的存储引擎实现事务的处理。这意味着,在单一事务中,混合使用不同存储引擎并不可靠。MySQL AB正打算为服务器增加一个高层次的事务管理服务,使用户可以安全的在事务中混合和匹配事务性表(Transaction Table)。
在一个事务中,如果混合使用事务性表和非事务性表,如果事务处理一切顺利,那么结果也会正常。但是,如果事务须回滚,那么在非事务性表上的操作将无法取消,这将导致数据库处于数据不一致的状态,在这种状态下,很难对数据进行恢复,并且事务会变得 悬而未决,因此每个表选择正常的存储引擎是极其重要的。
如果在一个非事务性表上执行事务性操作,MySQL通常不会给出警告或异常,有时候回滚会产生一个警告信息“Some nontrasactional changed tables couldn't rolled back”(某些非事务性修改无法回滚),但大多数情况下,没有任何提示。
隐式和显示锁定
InnoDB使用二项锁协议(Two-Phase Locking Protocol)。一个事务在执行过程中的任何时候,都可以获取锁,但是只有在执行COMMIT或者ROLLBACK语句后,才可以释放这些锁。他会同时释放掉所有的锁,前文描述的锁都是隐式锁定。InnoDB会根据用户的隔离级别,自动处理锁定。
不过InnoDB也支持显示锁定,例如下面语句(不代表全部)
- SELECT 。。。 LOCK IN SHARE MODE
- SELECT 。。。 FOR UPDATE
MySQL也支持LOCK TABLES和UNLOCK TABLES命令,这些命令由mysql服务器实现,而不是存储引擎。这些命令各有用途,不能完全取代事务的作用。如果需要事务性处理,应该选择使用事务性引擎。
有时候会看到一个应用从MyISAM引擎转InnoDB引擎后,仍然使用LOCK ATBLES命令,而这个实际上没有必要。因为InnoDB已经可以实现行级加锁,并且有可能会引起服务器的性能问题。
1.4 多版本并发控制
大多数MySQL的事务性存储引擎,例如InnoDB、Falcon和PBXT,不是简单地使用行加锁的机制,而是选用一种叫做多版本并发控制(MVCC,Multiversion Concurrency Control)的技术,和行加锁机制关联使用,以应对更多的并发处理问题。MVCC不是MySQL独有的技术,Oracle,PostgreSQL及其他一些数据库系统也使用同样的技术。
可以将MVCC设想成一种行级加锁的变形,他避免的很多情况下加锁操作,大大降低了系统的开销。依赖于具体技术实现,他可以在读取期间锁定需要记录的同时,还运行非锁定读取。
MVCC是通过及时保存在某些时刻的数据快照,而得以实现。这意味着同一个事务的多个实例,在同时运行时,无论每个实例运行多久,他们看到的数据视图是一致的;而同一时间,对于同一张表,不同事务看到的数据却是不同的!
每种存储引擎实现MVCC的方式是不同的。例如乐观并发控制(Optimistic ConCurrency Control)、悲观并发控制(Pessimistic Concurrency Control)。下面通过描述InnoDB简化版的行为方式,举例说明MVCC工作原理。
InnoDB通过为每个数据行增加两个隐含值的方式实现MVCC。这两个隐含值记录了行的创建时间,以及他的过期时间(删除时间)。每一行都存储了事件发生时的系统版本号(System Version Number),用来替代事件发生时的实际时间。每一次,开始一个新事务,版本号都会自动递增。每个事务都会保存他开始的“当前系统版本”的记录,而每个查询都会根据事务的版本号,检查每行数据的版本号。下面看一下当事务隔离级别设置为REPEATTABLE READ 时,MVCC在实际操作中的应用方式:
SELECT
InnoDB检查每行的数据,确保他符合两个标准
- InnoDB只查版本早于当前事务版本的数据行(也就是数据行的版本必须小于或者等于事务的版本),这确保了当前事务读取的行都是在事务开始前已经存在的,或者由当前事务创造或者修改的。
- 数据行的删除版本必须是未定义的,或是大于事务版本的,这保证了事务读取的行,在事务开始的时候是未被删除的。
只有通过上述两项测试的数据行,才会被当做查询结果返回。
INSERT
InnoDB为每个新增行记录当前系统版本号。
DELETE
InnoDB为每个删除行记录当前系统版本号,作为删除标识。
UPDATE
InnoDB会为每个需要更新的行,建立一个新的行拷贝,并且为新的行拷贝记录当前系统版本号,同时也为更行前的旧行,记录系统版本号,作为旧行的删除版本标识。
保存这些额外记录的好处,是使大多数读操作不必申请加锁,这使得读操作尽可能变得快,因为读操作只需要选取符合标准的行数据即可。这种方式的缺点是,存储引擎必须为每行数据,存储更多的额外数据,做更多的行检查工作,以及处理一些额外的整理操作(Housekeeping Operations)。
MVCC只工作在REPEATABLE READ和READ COMMITTED两个隔离级。READ UNCOMMITTED隔离级不兼容MVCC。因为在任何情况下,该隔离级下的查询,不读取符合当前事务版本的数据行,而是读取最新版本的数据行。SERIALIZABLE隔离级也不兼容MVCC,因为该级下的操作回对每个返回行都进行加锁。
MySQL中各种加锁模型和并发级别
| 加锁策略 |
并发 |
系统开销 |
引擎 |
| 表级加锁 |
最低 |
最低 |
MyISAM、Merge、Memory |
| 行级加锁 |
高 |
高 |
NDB Cluster |
| 支持MVCC的行级加锁 |
最高 |
最高 |
InnoDB、Falcon、PBXT、solidDB |
1.5 MySQL的存储引擎
在文件系统中,MySQL会把每个数据库(也叫做schema)保存为数据目录下的一个子目录 。当创建一个表时,MySQL会在和表名同名的、以.frm为文件后缀的文件中存储表的定义。因为MySQL使用文件系统存储数据库名和表定义,大小写没干将依赖于具体平台。在Windows平台上,MySQL的实例(Instance)名、表名、数据库名都是大小写不敏感的。在Unix类似平台上,则是大小写敏感的。每种存储引擎对表数据和索引的存储方式有所不同,但表定义是由MySQL服务器独立处理的。
如果想知道具体每张表使用哪种存储引擎,可以使用SHOW TABLE STATUS命令。例如,如果要检查MySQL数据库中的user表,可以执行以下命令
mysql> SHOW TABLE STATUS LIKE 'user' \G

命令显示,这是一个MyISAM类型的表。下面介绍具体含义:
Name:表名
Engine:表的存储引擎。在旧版本中,也可能是Type不是Engine
Row_format:行格式。对于MyISAM表,这可能是Dynamic、Fixed、Commpressed。动态行的长度可变,因为他们包含可变长度的字段,例如varchar或者BLOB字段。固定行指的是行长度相同,由不可变长度的字段组成,例如CHAR和INTEGER字段。压缩行只存在压缩表中。
Rows:表中的行数。对于非事务性表,这个值是精确的,对于事务性的表,这通常是个估算的值。
Avg_row_length:平均每行包含的字节数。
Data_length:整个表中的数据量(以字节为单位)
Max_data_length:表可以容纳的最大数据量。
Index_length:索引数据占用的磁盘空间的大小。
Data_free:对于MyISAM表,表示已分配,但现在未被使用的空间。这部分空间包含了以前被删除的行,这些空间可以用于以后的insert。
Auto_increment:下一个AUTO_INCREMENT值。
Create_time:表最初创建时的时间。
Update_time:表数据最近被更新的时间。
Check_time:使用CHECK TABLE命令或者myisamchk工具检查表是的最近时间。
Collation:指本表中默认字符集和字符排列的规则
Checksum:如果启用,则对整个表的内容计算实时的校验和(Checksum)。
Create_options:指表创建时的其他所有选项。
Comment:包含的其他额外信息,对于MyISAM还包含了注释,如果有注释就是表在创建的时候设定的,如果表使用InnoDB存储引擎,将显示InnoDB表空间的剩余空间,如果是一个视图,就会显示“VIEW”。
1.5.1 InnoDB存储引擎
innoDB是MySQL的默认事务型引擎,也是最重要,使用最广泛的存储引擎,他被设计用来处理大量的短期(short-lived)事务,短期事务的大部分情况是可以正常提交的,很少被回滚。InnoDB的性能和自动崩溃恢复特性,使得在非事务存储的需求中也很流行。除非有特别的原因需要使用其他存储引擎,否则一般情况下优先考虑MySQL存储引擎。
InnoDB概览
InnoDB的数据存储在表空间(tablespace)中,表空间是由InnoDB管理的一个黑盒子,由一系列数据文件组成。在MySQL4.1版本以后,InnoDB将每个表的数据和索引存放在 单独的文件中。
InnoDB采用MVCC来支持高并发,并且实现了四个标准的隔离级别。其默认的是REPEATABLE READ(可重复读),并通过间隙锁(next-key locking)策略防止幻读的出现。间隙锁使得InnoDB不仅仅 锁定查询涉及行,还会对索引中的间隙进行锁定,以防止幻影行的插入。
InnoDB表是基于聚簇索引建立的。InnoDB的索引结构和MySQL其他存储引擎有很大不同,聚簇索引对于主键查询具有很高的性能,不过他的二级索引(secondary Index非主键索引)中必须包含主键列,所以如果主键列很大的话,其他索引都会很大,因此如果表上索引较多的情况下主键尽肯能小。InnoDB的存储格式是平台独立的,也就是说可以将数据和索引文件从Intel平台复制到sun Space平台等。
InnoDB内部做了很多优化,包括从磁盘读取数据时采用的可预测性预读,能够自动在内存中创建hash索引以加速读操作的自适应哈希索引(adaptive hash index),以及能够加速插入操作的插入缓冲区(insert buffer)等。
强烈推荐官方手册中的“innoDB事务模型和锁”。如果应用程序基于InnoDB构建则事先了解一下InnoDB的MVCC架构带来的一些微妙和细节是很有必要的。存储赢取要为所用用户甚至包括修改数据的用户维持一致性视图,是非常复杂的工作。
作为事务性存储引擎,InnoDB通过一些机制和工具支持真正的热备份,Oracle提供的MySQL Enterprise Backup、Percona提供的开源XtraBackup都可以做到这一点,MySQL其他存储引擎不支持热备份,要获取一致性视图需要停止所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
1.5.2 MyISAM存储引擎
MySQL5.1以前默认存储引擎,MyISAM提供了大量的特性,包括全文检索(Full-Text Indexing)、压缩、空间函数(GIS)。MyISAM不支持事务和行级锁,并有一个缺陷是崩溃后无法完全恢复 。对于只读的数据,或者表比较小、可以忍受修复(repair)操作则依然可以使用MyISAM(但是请不要默认使用MyISAM,应当默认使用InnoDB)。
存储
一般来说,MyISAM将每个表存储成两个文件:数据文件和索引文件,扩展名分别是.MYD和.MYI。MyISAM的格式是平台通用的,这意味着用户可以在不同架构的服务器相互拷贝数据文件和索引文件。
MyISMA表可以包含动态行(Dynamic Row)和静态行(static Row固定长度行),MySQL会根据表定义决定选用何种格式。MyISAM可容纳的行总数,一般只受限于数据库服务器可用磁盘空间的大小,以及操作系统运行创建最大文件的大下。
在MySQL5.0中,默认配置的含有可变长行定义的MyISAM表可以支持到 256T的数据处理。并使用六个字节点指针记录数据。更早本本的MySQL默认使用4个字节指针,最大可处理4GB数据。所有的MySQL版本都支持最大8字节的指针。如果想修改MyISAM表指针的大小(调高或者调低),必须在表创建选项MAX_ROWS和AVG_ROW_LENGTH中,指定相关的值,这些选项代表了用户预计使用的表的大小。
MyISAM特性
加锁与并发
MyISAM对整张表加锁,而不是针对行,读取时会对需要读到所有表加共享锁,写入时加排它锁,但是在表有读取查询的同时,也可以向表中插入新的记录(并发插入,CONCURRENT INSERT)
修复
对于MyISAM表,MySQL可以手工或者自动执行检查和修复操作,但是这个和事务恢复以及崩溃恢复是完全不同的概念。执行表的恢复可能导致一些数据的丢失,并且修复也是一个很慢的操作。可以通过CHECK TABLE mytable来检查表的错误。如果有错误可以执行REPAIR TABLE mytable进行修复,如果MySQL服务器已经关闭,也可以通过myisamchk工具来进行检查和修复操作。
索引特性
对于MyISAM表即使是BLOB和TEXT等长字段,也可以基于前500个字符创建索引。MyISAM也支持全文索引,这是一种基于分词创建的索引可以支持复杂查询。
延迟更新索引键(Delayed Key Write)
使用表创建选项DELAY_KEY_WRITE创建的MyISAM表,在查询结束后,不会将索引的改变数据写入磁盘,而是在内存的键缓冲区(In-memory Key Buffer)中缓存索引改变的数据。他只会在清理缓存区,或者关闭表的时候,才将索引块转储到磁盘。对于数据经常改变,并且使用频繁的表,这种模式大大提高了表的处理性能。不过,如果服务器或者系统崩溃,索引将肯定损坏,并需要修复。用户可以使用脚本,如运行myisamchk工具,在重启服务器前进行修复,也可以自动恢复(Automatic Recover)选项进行修复(即使没有选用DELAY_KEY_WRITER选项,这些修复上的安全措施也是很有价值的)。延迟更新索引特性可以被全局配置,也可以为个别表单独配置。
MyISAM压缩表
某些表,例如基于CD-ROM或DVD-ROM的应用,或者某些嵌入式环境下的应用,一旦被创建和填写数据后,数据将永不改变。这种类型的表非常适合选用压缩的MyISAM表(Compressed MyISAM Table)。
使用myisampack工具,可以对表进行压缩(打包)。压缩表一般是不能改变的(除非用户需要,可以解压,修改之后,再重新压缩)。压缩占用的磁盘空间很小,使之可以提供更快的表处理性能。因为对于查找记录,压缩后的表将减少磁盘寻道时间。压缩的MyISAM表也可以拥有索引,但是索引只能是只读的。
对基于新一代硬件的大多数应用,读取压缩表时,因解压缩数据导致的系统开销不是那么引人注入,所以这种模式的真正好处是减低了磁盘I/O。而且,压缩表内的每一行是被单独压缩的,如果只是提取一行数据,MySQL并不需要因此解压整个表(甚至不需要解压一个页面);
MyISAM性能
MyISAM引擎设计简单,数据以紧密格式存储,所以在有些场景下性能很好。MyISAM有一些服务器级别的性能扩展限制,比如对索引建缓冲区(key cache)的Mutex锁,MariaDB基于段(Segment)的索引键缓冲区机制来避免该问题。但是最为重要的是MyISAM的表锁,如果发现一张表长期处于Locked状态,那么表锁就是罪魁祸首。
1.5.3 MySQL内建的其他存储引擎
Archive引擎
Archive存储引擎只支持INSERT和SELECT操作,在MySQL5.1版本之前不支持索引操作。Archive引擎会缓存所有的写并利用zlib对插入的行进行压缩,所以比MyISAM表的磁盘I/O更少。但是每次SELECT查询都需要全表扫描。所以Archive表适合日志和数据采集类的应用,这类应用锁数据分析时往往需要全表扫描,或者在一些需要快速INSERT操作的场合下也可以使用。
Archive引擎支持行级锁和专用的缓冲区,所以可以实现高并发的插入。在一个查询的开始直到返回表中存在所有行数之前,Archive引擎会阻止其他SELECT的执行,以实现一致性读。另外,也实现了批量插入在完成之前对读操作是不可见的。这种机制模仿了MVCC的一些特性。但Archive不是一个事务型引擎,而是一个针对高速插入和压缩做了优化的简单引擎。
Blackhole引擎
Blackhole引擎没有实现任何的存储机制,他会舍弃所有插入的数据,不做任何保存。但是服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者只是简单的记录到日志。这种特殊的存储引擎可以在一些特殊的复制框架和日志审核时发挥作用。但是也会存在很多问题(不推荐)。
CSV引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但是这种表不支持索引。CSV引擎可以在数据库运行时拷入或者拷出文件。可以将Excel等电子表格软件中的数据存储为CSV文件,然后复制到MySQL数据目录下,就能在MySQL中打开使用。同样,如果将数据写入到一个CSV引擎表,其他外部程序也能立即从表的数据文件中读取CSV格式的数据。因此CSV引擎可以作为一个数据交换的机制非常有用。
Federated引擎
Federated引擎是访问其他MySQL服务器的一个代理,他会创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,然后提取或者发送需要的数据。尽管该引擎看起来提供了一个很好的跨服务器灵活性,但是经常会带来问题,因此默认是禁用的,后续改良版本FederatedX.
Memory引擎
如果需要快速访问数据,并且这些数据不会被修改,重启后丢失也没关系,那么可以使用Memory表(以前也叫HEAP表)是非常有用的,Memory比MyISAM至少要快一个数量级,因为所有数据都保存在内存中,不需要进行磁盘I/O。Memory表在重启后结构会保留,但是数据会丢失。
Memory表可以在很多场景发挥好的作用
- 用于查找(lookup)或者映射(mapping)表,如将邮编和州名映射的表
- 用于缓存周期性聚合数据(periodically aggregated data)的数据
- 用于保存数据分析中产生的中间数据
Memory表支持Hash索引,因此查找操作非常快。虽然Memory速度非常快,但是还是无法替代基于磁盘的表。Memory是表级锁,因此并发写入的性能较低。他不支持BLOB以及TEXT类型的列,并且每行长度是固定的,所以即使指定了VARCHAR列,实际存储的时候也会转换成CHAR,这可能导致部分内存的浪费(一些限制基本在Percona版本基本解决)。
如果MySQL在执行查询的过程中需要使用临时表来保存中间结果,内部使用的临时表就是Memory表。如果中间结果太大超出了Memory限制,或者含有BLOB或TEXT字段,则临时表会转换成MyISAM表。
人们经常混淆Memory表或者临时表,临时表是指CREATE TEMPOARY TABLE语句创建的表,他可以使用任何存储引擎,因此和Memory表不是一回事。临时表只在单个连接可见,当连接断开时,临时表也将不复存在。
Merge引擎
Merge引擎是MyISAM引擎的一个变种。Merge表是由多个MyISAM表合成的虚拟表。如果将MySQL用于日志或者数据仓库类应用,该引擎可以发挥作用。但是引入分区后,该引擎被放弃。
NDB集群引擎
MySQL服务器、NDB集群存储引擎,以及分布式的、share-nothing的、容灾的、高可用的NDB数据库的组合,被称为MySQL集群(MySQL-Cluster)。
1.5.4第三方存储引擎
OLTP类引擎
Percona的XtraDB存储引擎是基于InnoDB引擎的一个改进版本,已经包含在Percona Server版本中和MariaDB中,主要改进点在于性能,可测量性和操作灵活性方面。XtraDB可以作为InnoDB的一个完全替代品,甚至可以兼容地读写InnoDB的数据文件,并支持InnoDB的所有查询。
另外还有一些与InnoDB非常类似的OLTP类存储引擎,比如都支持ACID事务和MVCC。其中一个就是PBXT,支持引擎基本的复制、外键约束,并且以一种比较复杂的架构对固态存储(SSD)提供了适当的支持,还对较大值类型如BLOB也做了优化。PBXT是一款社区 支持的存储引擎。
TokuDB引擎使用了一种新的分形树(Fractal Tree)的索引存储引擎数据结构。该结构是缓存无关的,因此即使其大小超过内存性能也不会降低,也就没有内存生命周期和碎片的问题。TokuDB是一种大数据(Big Data)存储引擎,因为其拥有很高的压缩比,可以在很大的数据量上创建大量索引。
RethinkDB最初是为固态存储(SSD)而设计的,然而随着时间的推移,目前看起来和最初的目标有一定的差距。该引擎比较特别的地方在于采用了一种只能追加的写时复制B树(append-only copyon-write B-Tree)作为索引的数据结构 。
面向列的存储引擎
MySQL默认是面向行的,每一行的数据是一起存储的,服务器的查询也是以行为单位处理的。而在大数据量处理时,面向列方式可能效率更高,如果不需要整行的数据,面向列的方式可以传输更少的数据。如果每一列都单独存储,那么压缩的效率也会更高。
Infobright是最有名的面向列的存储引擎。在非常打的数据量(数+TB)时,该引擎工作良好。Infobright是为数据分析和数据仓库应用设计的。数据高度压缩,按照块进行排序,每个块都对应有一组元数据。在处理查询时,访问元数据可决定跳过该块,甚至肯能只需要元数据就能满足查询的需求。但该引擎不支持索引,不过在这么大的数据量级,即使有索引也很难发挥作用,而块结构也是一种准索引(quasi-index)。Indobright需要对MySQL服务器做定制,因为一些地方修改以适应面向列存储的需要,如果查询无法再存储层使用面向列的模式执行,则需要在服务器层转换成按列处理,这个过程会很慢,Infobright有社区版和商业版两个版本。
另外一个面向列存储引擎是Calpont公司的InfiniDB,也有社区版和商业版,InfiniDB可以在一组机器集群间做分布式查询,但目前还没有 生产环境应用。
社区存储引擎
Aria
之前的名字是Maria,是MySQL的创建者计划替代MyISAM的一款引擎。MariaDB包含了该引擎,之前计划开发很多特性,有些因为在MariaDB服务器层实现所以引擎层就取消了。
Groonga
这是一款全文索引引擎,号称可以提供准确而高效的全文索引。
OQGraph
该引擎又Open Query研发,支持图操作(比如查找两点之间最短路径),用SQL很难实现该类操作。
Q4M
该引擎在MySQL内部实现了队列操作,而用SQL很难在一个语句中实现队列的操作。
SphinxSE
该引擎为Sphinx全文索引搜索服务器提供了SQL接口,并在附录F 进一步详细讨论。
Spider
该引擎可以将数据切分不同的分区,比较高效透明的实现了分片(shard),并且可以针对分片执行并行查询(分片可以分布在不同的服务器上)。
VPForMySQL
该引擎支持垂直分区,通过一系列的代理存储引擎实现。垂直分区指的是可以将表分成不同列的组合并单独存储。对于查询来说,还是一张表。该引擎和Spider的作者是一个人。
1.5.5 选择合适的引擎
大部分情况下InnoDB都是正确的选择,所以Oracle在MySQL5.5版本时,将InnoDB作为默认的存储引擎。除非使用到了某些InnoDB不具有的特性,并且没有其他办法可以替代,否则都应该优先考虑InnoDB引擎。例如需要使用全文索引,建议优先考虑InnoDB+Sphinx,而不是使用支持全文索引的MyISAM。当然如果不需要使用InnoDB的特性,同时其他特性能够更好地满足需求,可以考虑使用其他存储引擎。
除非万不得已,否则建议不要混合使用多种存储引擎,否则可能会带来一系列复杂的问题,以及一些潜在的bug和边界问题。存储引擎层和服务层的交互已经比较复杂,更不用说混合多个存储引擎了。至少,混合存储对一致性备份和服务器参数配置都带来了困难。
如果需要应用不同的存储引擎,请优先考虑以下几个因素
事务
如果需要事务支持,那么InnoDB(或者XtraDB)是目前最稳定,并且通过验证的选择。如果不需要使用事务,并且主要是使用SELECT和INSERT操作,那么MyISMA是一个不错的选择。一般日志型的应用比较符合这一特性。
备份
备份的需求也会影响存储引擎的选择。如果可以定期的关闭服务器进行备份,那么备份的因素可以忽略。反之,如果需要在线热备份,那么选择InnoDB就是基本要求。
崩溃恢复
数据量比较大的时候,系统崩溃后如何快速恢复是一个需要考虑的问题。相对而言,MyISAM崩溃后发送损坏的概率比InnoDB要高很多,而且恢复速度也要慢。因此,即使不需要事务支持,很多人也选择InnoDB引擎,这是一个非常重要的因素。
特有的特性
最后有些应用可能依赖一些存储引擎所独有的特性或者优化,比如很多应用依赖聚簇索引的优化。另外,MySQL中也只有MyISAM支持地理空间搜索。如果一个存储引擎拥有一些关键的特性,同时又缺乏一些必要的特性,那么有时候就不得不做折中的考虑,或者在架构设计上做一些取舍。某些存储引擎无法直接支持的特性,有时候可以通过变通也可以满足需要。
日志型应用
假设你需要实时地记录一台中心电话交换机的每一通电话的日志到MySQL中。或者通过Apache的mod_log_sql模块将网站的所有访问信息自己记录到表中。这一类的应用插入速度有很高的要求,数据库不应该成为瓶颈。MyISMAM或者Archive存储引擎对这类应用比较合适,因为开小弟,并且插入速度非常快。
如果需要对记录的日志做分析报表,那就比较好玩了,生成报表的SQL很有可能导致插入效率明显降低,改怎么做呢?
一种解决方法,是利用MySQL内置的复制方案将数据复制一份到备库,然后备份库上执行比较消耗时间和CPU的查询。这样主库只用于高效的插入工作,而备库的查询无须担心影响到日志的插入性能。当然也可以在系统负载较低的时候执行报表查询操作。但应用在不断变化,如果依赖这个策略可能以后会导致问题。
另一种方法,在日志记录表的名字中包含年和月的信息,比如web_log_2018_07或者web_log_2018_jan.这样可以在已经没有插入操作的历史表上做频繁的查询操作,而不会干扰到最新的当前表上的插入操作。
只读或者大部门情况下只读的表
有些表的数据用于编制类目或者分列清单(如工作岗位、竞拍、不动产等),这种应用的场景是典型的读多写少的业务。如果不介意MyISAM的崩溃问题,选用MyISAM引擎是合适的。不过不要低估崩溃恢复问题的重要性。有些存储引擎不会保证数据完全写入到磁盘中,而许多用户实际上并不清楚这样有多大风险(MyISAM只将数据写到内存中,然后等待操作系统定期将数据刷出到磁盘上)。
一个值得推荐的方式,是在性能测试环境模拟真实的环境,运行应用,然后拔下电源模拟崩溃测试。对于崩溃恢复的第一手测试经验是无价之宝,可以避免碰到真正的崩溃手足无措。
不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多已知的场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是使用到了聚簇索引,或者需要访问的数据都可以放入到内存的应用。在后续章节中可以了解到更多影响存储引擎性能的因素(如数据大小、I/O请求量,主键还是二级索引等)以及这些因素对应用的影响。
当设计上述类型的应用时,建议采用InnoDB,MyISAM引擎一开始可能没有任何问题,但是随着应用压力的上升,则可能迅速恶化。各种锁的争用、崩溃后数据丢失的问题也都会随之而来。
订单处理
如果涉及订单处理,那么支持事务就是必要选项。另外一个重要考虑点就是存储引擎对外键的支持情况。InnoDB是订单处理类应用最佳选择。
电子公告牌和主题讨论论坛
对于MySQL用户,主题讨论群是一个很有意思的话题。当前有成百上千的基于PHP或者Perl的免费系统可以支持主题讨论。其中大部分的数据库效率并不高,因为他们多大倾向于在一次请求中执行尽可能多的查询语句。另外还有部分系统设计为不采用数据库,当然也就无法利用到数据库提供的一些方便的特性。主题讨论区一般都有更新计数器,并且为各个主题计算访问统计信息。多数应用只设计了几张表保存所有的数据,所以核心表的读写压力可能非常大。为保证这些核心表的数据一致性,锁成为资源竞争的主要因素。
尽管有这些设计缺陷,淡大多数应用在中低负载时可以工作的很好。如果web站点的规模迅速扩张,流量随之猛增,则数据库访问可能变得非常慢。此时一个典型的解决方案是更改为更高读写的存储引擎,但有时用户会发现这么做反而导致系统变慢了。
用户可能没有意识到这是由于某些查询的缘故,典型的如:
mysql> SELECT COUNT(*) FROM table;
问题就在于,不是所有的存储引擎运行上述查询都非常快:对于MyISAM确实会很快,其他的可能不行。每种存储引擎都能找出类似对自己有利的例子,下一章将帮助用户分析这些状况,演示如何发现和解决存在的这类问题。
CD-ROM应用
如果要发布一个基于CD-ROM或者DVD-ROM并且使用MySQL数据文件的应用,可以考虑使用MyISAM表或者MyISAM压缩表,这样的表之间可以隔离并且可以在不同介质上相互拷贝。MyISAM压缩表比未压缩的表要节约很多空间,但压缩表是只读的。在某些应用中可能是一个大问题。但是如果数据放到只读介质的场景下,压缩表的只读特性就不是问题,就没有理由不采用压缩表的。
大数据量
什么样的数据量算大?我们创建或者管理的很多InnoDB数据库的数据量在3-5TB之间或者更大,这是单台机器上的量,不是一个分片(shard)的量。这些系统运行还不错,要做到这一点需要合理的选择硬件,做好物理设计,并为服务器的I/O瓶颈做好规划。在这样的数据量下,如果采用MyISAM,崩溃后的恢复就是一个噩梦。
如果数据量继续增长到10TB以上的级别,可能就需要建立数据仓库。Infobright是MySQL数据仓库最成功的解决方案。也有一些大数据库不适合Infobright,却可能适合TokuDB。
1.5.6 转换表的引擎
有很多种方法可以将表的存储引擎转换成另外一种引擎。每种方法都有其优点和缺点。下面介绍其中的三种方法:
ALTER TABLE
将表从一个引擎修改为另一个引擎最简单的版本是使用ALTER TABLE语句。下面的语句将mytable的引擎修改为InnoDB:
mysql> ALTER TABLE mytable ENGINE = InnoDB;
实验步骤如下:
mysql> create table mytable(name varchar(64)) ENGINE = MyISAM;
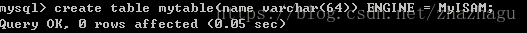
mysql> SHOW table status FROM test where name = 'mytable' \G
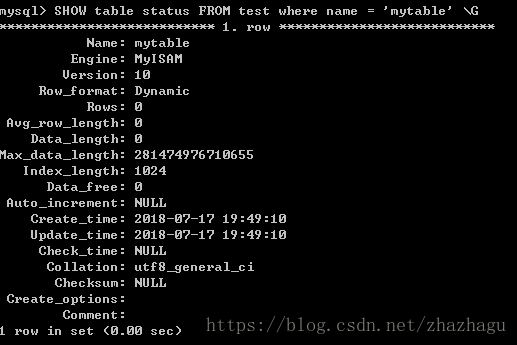
修改存储引擎:
mysql> ALTER TABLE mytable ENGINE=InnoDB;

查看效果
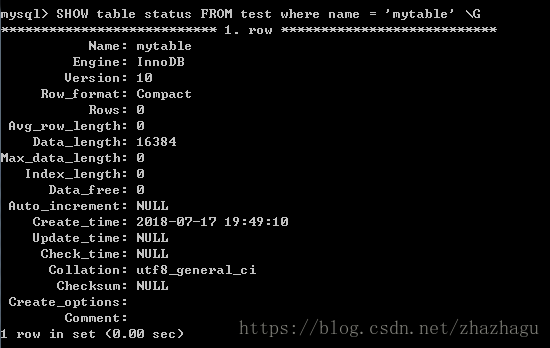
上述语法可以适用于任何存储引擎。但是有一个问题:需要执行很长的时间。MySQL会按行将数据从原表复制到一张新的表中,在复制期间可能会消耗系统所有的I/O能力,同时原表上会加上读锁。所以,在繁忙的表上执行此操作需要特别小心。一个替代方案是采用接下来将要讨论的导出导入的方法,手工进行表的复制。
如果转换表的存引擎,将会失去原引擎相关的所有特性。例如,将InnoDB表转为MyISAM表,再转换为InnoDB,员InnoDB表上所有的外键将丢失。
导出与导入
为了更好控制转换的过程,可以使用mysqldump工具将数据导出到文件,然后修改文件中的CREATE TABLE语句的存储引擎选项,注意同时修改表名,因为同一个数据库中不能存在相同的表名,即使他们使用的是不同的存储引擎。同时还要注意mysqldump会默认在CREATE TABLE前加上DROP TABLE语句,不注意这一点可能会导致数据丢失。
实验过程如下:(将InnoDB引擎修改为MyISAM引擎)
C:\Users\gugu>mysqldump -uroot -p --databases test --tables mytable > D://mytabl
e.dump

文件打开,核心内容如下
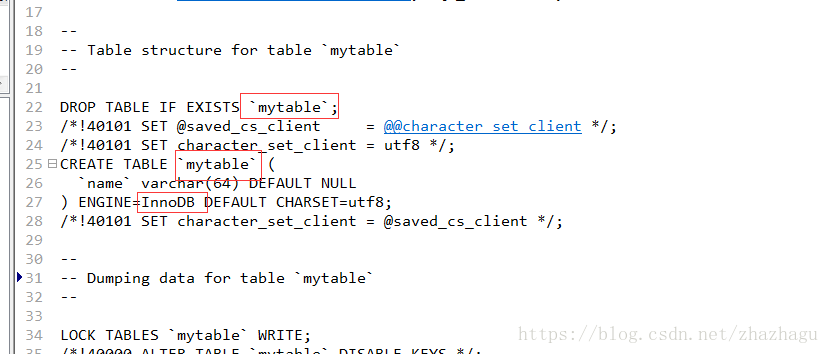
修改内容后:

导入数据库
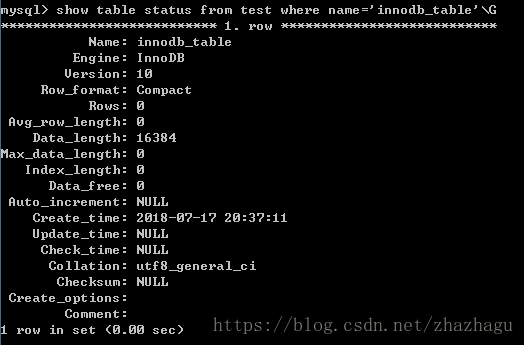
C:\Users\gugu>mysql -uroot -p test < D:\\mytable.dump
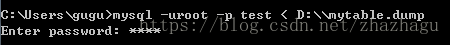
mysql> show table status from test where name='mytable1' \G

创建与查询(CREATE和SELECT)
第三种转换的技术综合了第一种方法的高效和第二种方法的安全。不需要导出整个表的数据 ,而是先创建一个新的存储引擎表,然后利用INSERT 。。。SELECT语法老导整个数据:
mysql> CREATE TABLE innodb_table LIKE mytable1;
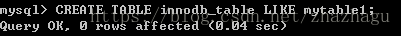
mysql> ALTER TABLE innodb_table ENGINE=InnoDB;

mysql> INSERT INTO innodb_table SELECT * FROM mytable1;

如果数据量不大的话,这样工作很好。如果数据量很大,则可以考虑分批处理针对每一段数据执行事务提交操作,以避免大事务产生过多的undo。假设主键字段id,重复执行以下语句(最小值x和最大值y的进行相应替换)将数据导入到新表:
mysql> START TRANSACTION;
mysql>INSERT INTO innodb_table SELECT * FROM myisam_table
->WHERE id BETWEEN x AND y;
mysql>COMMIT;
这样操作完成后,新表是原表的一个全量复制,原表还在,如果需要可以删除原表。如果有必要可以在执行过程中对原表加锁,以确保新表和原表的一致性。
Percona Toolkit提供了一个pt-online-schema-change的工具(基于Facebook的在线schema变更技术),可以比较简单、方便地执行上述过程,避免手工操作导致的失误和繁琐。
1.6 MySQL时间线(Timeline)
版本3.23(2001)
一般认为这个版本的发布是MySQL真正“诞生”的时刻,其开始获得广泛使用。在这个版本,MySQL依然只是一个在平面文件(Flat File)上实现了SQL的查询系统。但是一个重要的改进是引进MyISAM代替了老旧的ISAM引擎。InnoDB引擎也可以使用,但没有包含在默认的二进制发行版中,因为它太新了,所以如果使用InnoDB,必须手工编译。版本3.23还引入了全文索引和复制。复制是MySQL成为互联网应用的数据库系统的关键特性(killer feature)。
版本4.0(2003)
支持新的语法,比如UNION和多表的DELETE语法。重写了复制,在备库使用了两个线程来实现复制,避免了之前一个线程做所有的复制工作的模式下任务切换导致的问题。InnoDB已成为标准配备,包括了全部的特性:行级锁、外键等。版本4.0中还引入了查询缓存(自那以后这部分改动不大),同时还支持通过SSL进行连接。
版本4.1(2005)
引入了更多新的语法,比如INSERT ON DUPLICATE KEY UPDATE。开始支持UTF-8字符集。支持新的二进制协议和prepared语句。
版本5.0(2006)
这个版本中出现了一些“企业级”特性:视图、触发器、存储过程和存储函数。老的ISAM引擎代码被彻底移除,同时引入新的Federated等引擎。
版本5.1(2008)
这是Sun收购MySQL AB以后发布的首个版本,研发时间长达五年。版本5.1引入了分区,基于行的复制,以及plugin API(包括可插拔存储引擎的API)。移除了BerKeyDB引擎,这是MySQL最早的事务存储引擎。其他如Federated引擎也将被放弃。同时Oracle收购的InnoDB Oy发布了InnoDB plugin。
版本5.5(2010)
这是Oracle收购Sun以后发布的首个版本。版本5.5的主要改善集中在性能、扩展性、复制、分区、对微软Windows系统的支持,以及一些其他方面。InnoDB成为默认存储引擎。更多的一些遗留特性和不建议使用的特性被移除。增加了PERFORMANCE_SCHEMA库,包含了一些可测量的性能指标的增强。增加了复制、认证和审计的API。半同步复制(semisynchronous replication)插件进入实用阶段。Oracle还在20011年发布了商用的认证插件和线程池(thread pooling)。InnoDB在架构方面也做了较大的改进,比如多个子缓冲池(buffer pool)。
版本5.6(还未发布)[写书的时候]
版本5.6将包含一些重大跟新。比如多年来首次对查询优化器进行大规模的改进,更多的API插件(比如全文索引),复制的改进,以及PERFORMANCE_SCHEMA库增加了更多的性能指标,InnoDB团队也做了大量的改进工作,这些改进在已经发布的里程碑版本和实验室版本找那个已经包括。MySQL5.5主要着重在基础部分的改进和加强,引入了部分新特性。而MySQL5.6则在MySQL5.5的基础上提升服务器的开发和性能。
简单总结一下MySQL的发展史:早期的MySQL是一种破坏性创新,有诸多限制,并且很多功能只能说的二流的。但是他的特性支持和较低的使用成本,使得其成为快速增长的互联网时代的杀手级应用。在5.x版本早期,MySQL引入视图和存储过程等特性,期望成为“企业级”数据库,但并不算成功,从事后分析来看MySQL5.0充满了bug,直到版本5.0.50版本才算稳定。
下表1-2显示了在服务器层面不同并发下每秒事务数的测试结果。
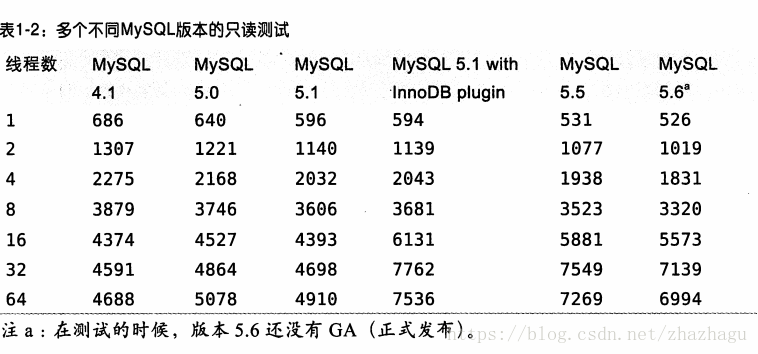

从结果来看有两个很明显的趋势。第一个,采用了InnoDB plugin的版本,在高并发的时候性能明显更好,可以说InnoDB plugin扩展性更好。第二个趋势,新版本在单线程的时候性能比旧版本更差。这是因为测试使用的是很简单的只读测试。新版本的SQL语法更复杂,针对复杂查询增加了很多特性和改进,这对于简单查询可能带来了更多的系统开销。旧版本代码简单,对于简单查询反而更有利。
1.7 MySQL的开发模式
略
1.8总结
MySQL拥有分层的架构。上层是服务器的服务和查询执行引擎,下层则是存储引擎 。虽然有不同作用的插件API,但存储引擎API还是最重要的。如果能理解MySQL在存储引擎和服务层之间处理查询时如何用过API来回交互,就能抓住 MySQL的核心基础架构的精髓。
MySQL最初基于ISAM构建(后来被MyISAM替代),其后添加了更多的存储引擎和事务支持。MySQL有一些怪异的行为是由于历史遗留导致。例如在执行ALTER TABLE时,MySQL提交事务的方式是由于存储引擎的架构直接导致的,并且数据字典也存储在.frm文件中(这并不是说InnoDB会导致ALTER变成非事务的。对于InnoDB所有操作都是事务)。