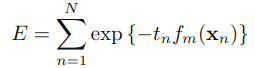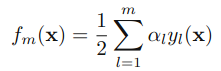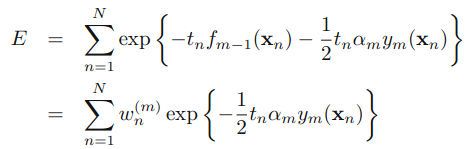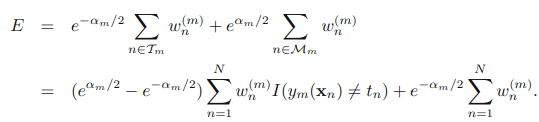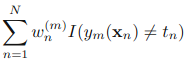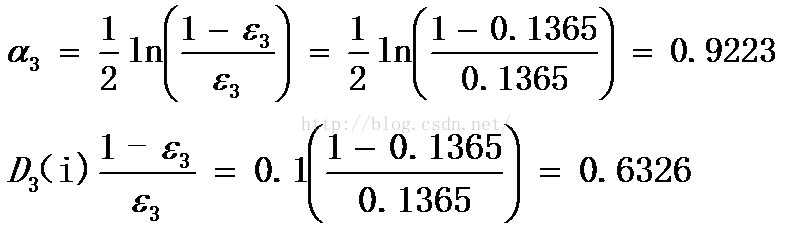Adaboost算法的目标是提高
学习算法(比如说LMS算法)的
分类准确率。
adaboost算法提供的是框架
。
可以使用各种学习方法构建子分类器。
对于Adaboost,可以说是久闻大名,据说在Deep Learning出来之前,SVM和Adaboost是效果最好的 两个算法,而Adaboost是提升树(boosting tree),所谓“提升树”就是把“弱学习算法”提升(boost)为“强学习算法”(语自《统计学习方法》),而其中最具代表性的也就是Adaboost了,貌似Adaboost的结构还和Neural Network有几分神似,我倒没有深究过,不知道是不是有什么干货
二: 算法分析
步骤:
根据训练样本设计一个分类器,根据分类的结果,改变每个样本的权重,产生一个弱分类器,一直迭代,直到最后的误差率小于给定的误差率。把这些分类器合并起来,组成一个强分类器。
一:从大小为n的原始样本集D中随机选出n1个样本点(不放回),组成一个样本集D1。
二:用样本集D1我们可以训练出第一个分类器。记为C1
三:然后构造第二个分类器。首先我们需要构造样本集D2(D2中的样本,一半能够被C1正确分类,一半不能够被C1正确分类),下面给出一种构造方法:
采用抛硬币的方式,如果硬币是正面:选取D中剩余的样本点,用C1进行分类,直到找出分错的样本,加入D2.
如果硬币是反面:从D1中选取一个被C1正确分类的样本点,加入D2.
最后D2就是C1所产生的的最富信息的集合。
四:然后,我们构造第三个分类器,选取D中剩余的样本点,用C1和C2进行分类,如果C1和C2分类的结果不一样,则把这个样本加入D2.否则,忽视这个样本点。然后用D3训练新的分类器C3.
对于boosting算法,存在两个问题:
1. 如何调整训练集,使得在训练集上训练的弱分类器得以进行:
使用加权后选取的训练数据代替随机选取的训练样本,这样将训练的焦点集中在比较难分的训练数据样本上;
2. 如何将训练得到的各个弱分类器联合起来形成强分类器:
将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。
三.过程
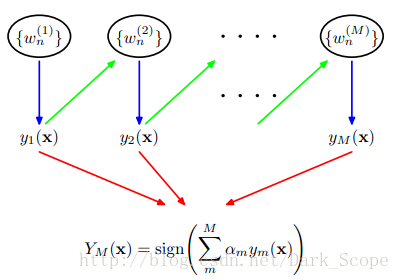 (from PRML)
(from PRML)
这就是Adaboost的结构,最后的分类器YM是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
这里阐述下算法的具体过程:
1.初始化所有训练样例的权重为1 / N,其中N是样例数
2.for m=1,……M:
a).训练弱分类器ym(),使其最小化权重误差函数(weighted error function):
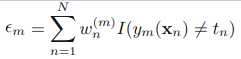
b)接下来计算该弱分类器的话语权α:
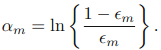
c)更新权重:
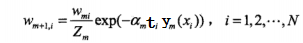
其中Zm:
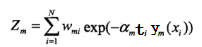
是规范化因子,使所有w的和为1。(这里公式稍微有点乱)
3.得到最后的分类器:
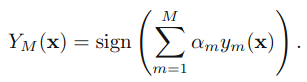
四.原理
可以看到整个过程就是和最上面那张图一样,
前一个分类器改变权重w,同时组成最后的分类器
如果一个训练样例 在前一个分类其中被误分,那么它的权重会被加重,相应地,被正确分类的样例的权重会降低
使得下一个分类器 会更在意被误分的样例,那么其中那些α和w的更新是怎么来的呢?
下面我们从前项分步算法模型的角度来看看Adaboost:
直接将前项分步加法模型具体到adaboost上:
其中 fm是前m个分类器的结合
此时我们要最小化E,同时要考虑α和yl,
但现在我们假设前m-1个α和y都已经fixed了:那么
其中
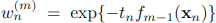
,可以被看做一个常量,因为它里面没有αm和ym:
接下来:
其中Tm表示正分类的集合,Mm表示误分类的集合,这一步其实就是把上面那个式子拆开,没什么复杂的东西
然后就是找ym了,就是最小化下式的过程,其实就是我们训练弱分类器
有了ym,α也就可以找了,然后继续就可以找到更新w的公式了(注意这里得到的w公式是没有加规范化因子Z的公式,为了计算方便我们加了个Z进去)
因为这里算出来直接就是上面过程里的公式,就不再赘述了,有兴趣你可以自己算一算
五:训练过程
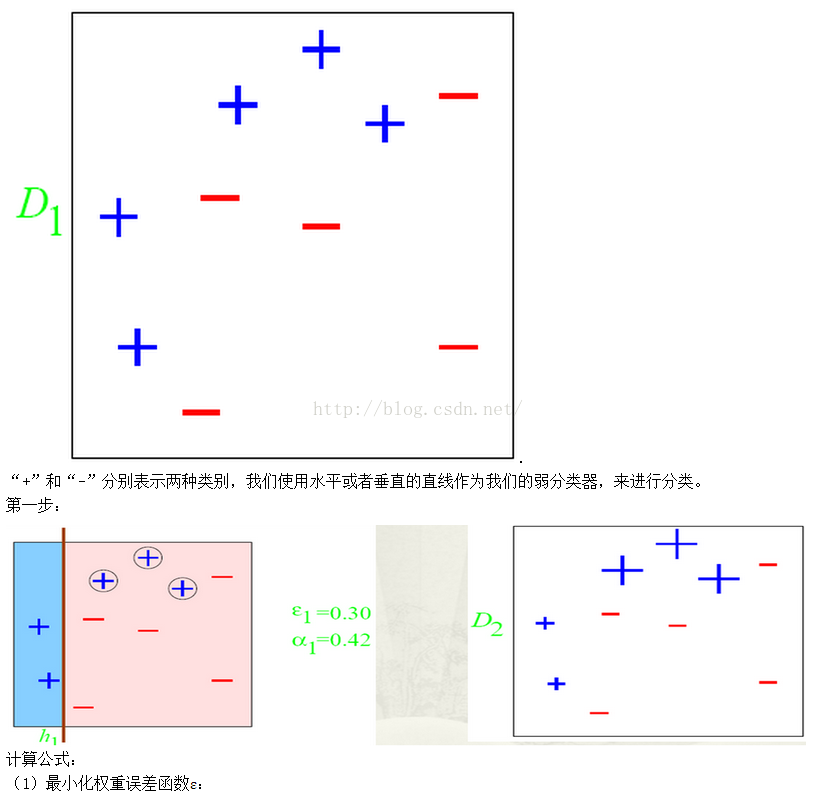
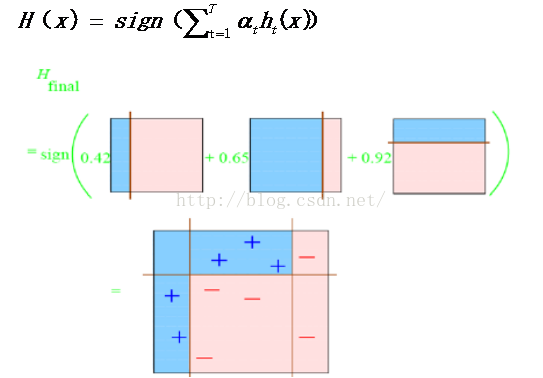
百度的大牛举得一个例子:
第二步:
根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
弱分类器h2 中有三个“-”符号分类错误
分类错误的权值为:we2=0.1*3=0.3;
上图中十个点的总权值为:wt2=0.1*7+0.233*3=1.3990;
错误率为:ε2=we2/wt2=0.3/1.399= 0.2144;

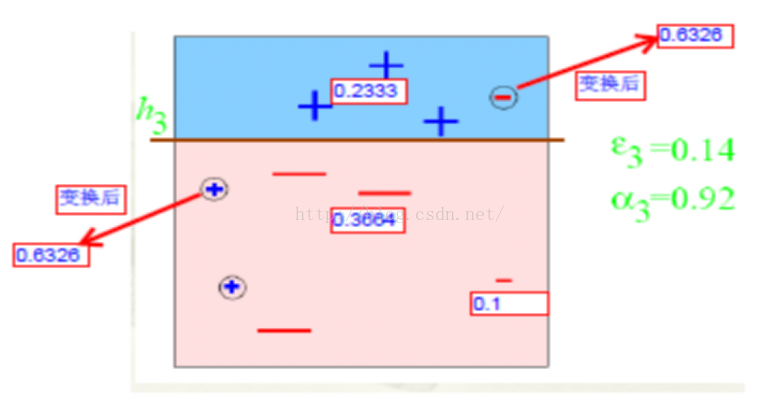
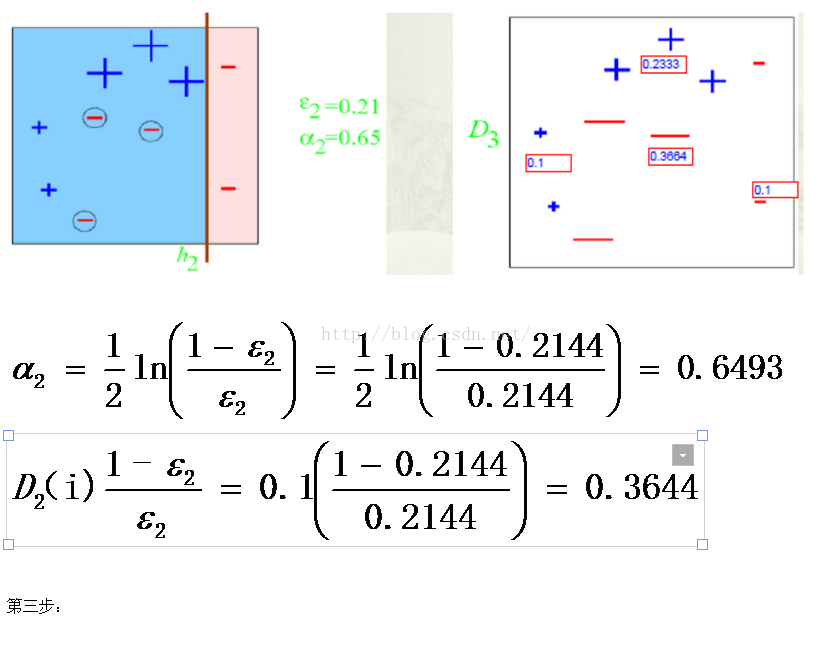
弱分类器h3 中有两个“+”符号和一个“-”符号分类错误
分类错误的权值为we3=0.1*2+0.1*1=0.3;
上图中十个点的总权值为:wt3=0.1*4+0.233*3+0.3664*3=2.1982;
错误率为: εt=we3/wt3=0.3/2.1982= 0.1365;
分类错误的三个点误差增加为0.6326如此迭代
第四步:
有公式:
每个区域是属于哪个属性,由这个区域所在分类器的权值综合决定。比如左下角的区域,属于蓝色分类区的权重为h1 中的0.42和h2 中的0.65,其和为1.07;属于淡红色分类区域的权重为h3 中的0.92;属于淡红色分类区的权重小于属于蓝色分类区的权值,因此左下角属于蓝色分类区。
因此可以得到整合的结果如上图所示,从结果图中看,即使是简单的分类器,组合起来也能获得很好的分类效果。
总结:
Adaboost 权值为什么这样调节:
提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致αt变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。