单链表是数据结构中较为“简单”的一部分,但是它却是很重要的一部分。二叉树,线索二叉树,哈希函数等等的相关操作都离不开链表,因此搞懂单链表显得尤为重要。下面是我对链表简单操作的一些理解。(本文中所有链表代码均无头结点,ppFirst指的是首元结点)
首先,单链表的本质得先清楚。单链表是一种链式存储的线性表。它可以解决数组无法存储多种类型的问题。我们通过图简单的认识一下链表:
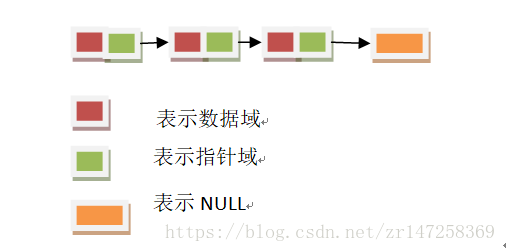
其次,单链表的相关操作需要掌握。(重中之重)
1 单链表成员的创建,即结点的创建。
链表结点的创建,首先声明结构体,结构体中包括数据域和指针域:代码如下所示:
typedef int DataType;
//创建单链表的成员,其实就是结点
typedef struct SListNode {
DataType data; // 值
struct SListNode *pNext; // 指向下一个结点
} SListNode; //SListNode为这个结构体的别名
2 初始化单链表
初始化单链表也就是将首元结点初始化为空,代码如下:
void SListInit(SListNode **ppFirst)
{
*ppFirst = NULL;
}
3 打印单链表
打印单链表,首先判断链表是否为空,为空则直接打印“空链表”,否则循环打印出每个结点的数据
//打印
void SListprint(SListNode *ppFirst)
{//判断是否为空链表
SListNode *p = ppFirst;
if(p == NULL)
{
printf("空链表\n");
}
else{
//非空链表:循环打印每个链表的data,循环结束条件为遇到空指针
for(p = ppFirst;p != NULL;p = p->pNext)
{
printf("%d ",p->data);
}
printf("NULL\n");
}
}
4 创建新结点
创建新的结点,新结点包含数据域和指针域。将其封装为函数,调用更加方便。主要代码如下:
//创建新结点,结点的数据域为data,pNext域设置为空
SListNode *_CreateNode(DataType data)
{
SListNode *NewNode; //声明新结点
NewNode = (SListNode *)malloc(sizeof(SListNode));//创建新结点
if(NewNode == NULL)
{
return;
}//创建失败
NewNode ->data = data;
NewNode ->pNext = NULL;//创建成功
}
5 单链表的查找
按值查找,找到后返回第一个的结点指针,如果没找到,返回NULL
// 按值查找,返回第一个找到的结点指针,如果没找到,返回NULL
SListNode * SListFind(SListNode *ppFirst, DataType data)
{
SListNode *cur;
//顺序查找,去遍历
for(cur = ppFirst; cur != NULL; cur = cur->pNext)
{
if( cur->data == data)
{
return cur;
}
}
return NULL;
}
6 销毁单链表
销毁单链表也就是将每个结点free掉,并且将首元结点置空。
// 销毁 (记录并删除链表中的每个结点,并将头结点置为空)
void SListDestroy(SListNode **ppFirst)
{
SListNode *pre;
SListNode *cur;
assert(*ppFirst);
pre = *ppFirst;
for(pre = *ppFirst; pre != NULL;pre = cur)
{
cur = pre ->pNext;
free(pre);
}
*ppFirst = NULL;
}
7 单链表的尾插
此处未做详细说明,链表的插入以及删除在下一篇博客中详细说明。
// 尾部插入(先找到最后一个结点,并把它记录下来,再把最后一个结点的pNext域指向新的结点)
void SListPushBack(SListNode** ppFirst, DataType data)
{
SListNode *p;//新结点p
SListNode *p1;
p = _CreateNode(data);
p1 = *ppFirst;//用来遍历链表(开始位于头结点处)
//空链表
if( (*ppFirst) == NULL ){
*ppFirst = p;
return;
} else{
for(p1 = *ppFirst;p1->pNext != NULL;p1 = p1->pNext)
{
}
p1 ->pNext = p;//此时p1为最后一个结点
}
}
上述链表操作的测试代码如下:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <windows.h>
int main()
{
SListNode *result;
SListNode *p1;
SListInit(&p1);
SListPushBack(&p1,1);
SListPushBack(&p1,2);
SListPushBack(&p1,3);
SListPushBack(&p1,2);
SListPushBack(&p1,5);
SListPushBack(&p1,2);
SListPushBack(&p1,6);
result = SListFind(p1,5);
SListprint(result);
SListDestroy(&p1);
SListprint(p1);
system("pause");
return 0;
}
上述仅仅是单链表的简单操作,重要的插入与删除将在下一篇博客中详细说明。