版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/mhsszm/article/details/87210961
先贴原代码,后面再一一做解释。
/* 单链表的各创建等等操作
日期:2017年11月3日 21:46
*/
#include "stdafx.h"
#include <iostream>
#include "stdlib.h"
using namespace std;
//定义链表结点
typedef struct node
{
int data;
node * next;
}node;
/*
创建单链表
思路:head结点,while循环输入结点,可以做个改进,head结点的data为链表的长度
日期:2017年11月3日 21:46
*/
node * create()
{
int i = 0;
node *head, *p, *q=NULL;
int x = 0;
head = new node();
while (true)
{
printf("input node data:");
scanf("%d", &x);
if (x==0)
{
break;
}
p = new node();
p->data = x;
if (++i == 1)
{
head->next = p;
}
else
{
q->next = p;
}
q = p;
}
q->next = NULL;
return head;
}
/*
测单链表长度
head->next 为第一个结点,循环遍历到尾结点,为空的结点为止
日期:2017年11月3日 21:53
*/
int Length(node * head)
{
if (head == NULL)
{
return 0;
}
int len = 0;
node *p;
p = head->next;
while (p != NULL)
{
len++;
p = p->next;
}
return len;
}
/*
单链表打印
日期:2017年11月3日 21:53
*/
int Print(node * head)
{
int index = 0;
node *p;
if (head->next == NULL)
{
printf("link is null\n");
return 0;
}
p = head->next;
while (p != NULL)
{
printf ("the %dth node is %d\n", ++index, p->data);
p = p->next;
}
return index;
}
/*
单链表查找(以节点数来查找,而不是以关键字来查找)
日期:2017年11月3日 21:58
*/
node * search(node*head, int pos)
{
node *p = head->next;
if (pos<0)
{
printf("incorrect position to search node!\n");
return NULL;
}
if (pos == 0)
{
return head;
}
if (p == NULL)
{
printf("link is empty!\n");
return NULL;
}
while (pos--)
{
if ((p=p->next)==NULL)
{
printf("incorrect position to search node!\n");
break;
}
}
return p;
}
/*
单链表插入节点
日期:2017年11月3日 22:10
*/
node *insert_node(node* head, int pos, int data)
{
node * item = NULL;
node *p;
item = new node();
item->data = data;
if (pos ==0)
{
head->next = item;
return head;
}
p = search(head, pos-1);
//在p 与p->next中插入节点item
//很简单
if (p!=NULL)
{
item->next = p->next;
p->next = item;
}
return head;
}
/*
单链表删除节点
日期:2017年11月3日 22:10
*/
node *delete_node(node* head, int pos)
{
node * item = NULL;
node *p = head->next;
if (p == NULL)
{
printf("link is empty!\n");
return NULL;
}
p = search(head, pos-1);
if (p!=NULL&&p->next!=NULL)
{
item = p->next;
p->next = item->next;
delete item;
}
return head;
}
/*
单链表逆转:就地逆转
日期:2017年11月3日 22:10
*/
node * reverse(node * head)
{
node *p, *q, *r;
//空值判断
if (head->next == NULL)
{
return NULL;
}
p = head->next;
q = p->next;
p->next = NULL;
while (q!=NULL)
{
r = q->next;
q->next = p;
p = q;
q = r;
}
head->next = p;
return head;
}
/*
查找单链表的中间元素
i走两步,j走一步……,由此来判断中间的元素
日期:2017年11月3日 22:10
*/
node * searchMidNode(node * head)
{
int i = 0;
int j = 0;
node * current = NULL;
node * middle = NULL;
current = middle = head->next;
while (current!=NULL)
{
if (i/2>j)
{
j++;
middle = middle->next;
}
i++;
current = current->next;
}
return middle;
}
int main()
{
node *head = create();
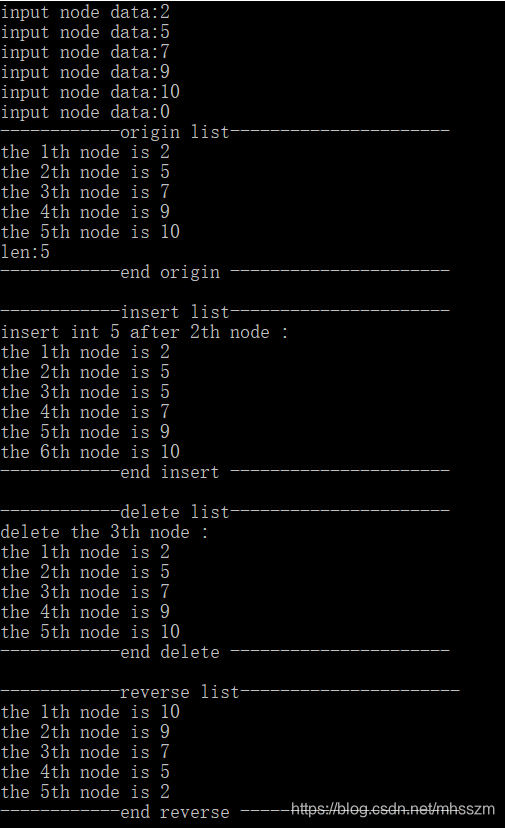
printf("------------origin list----------------------\n");
Print(head);
printf("len:%d\n", Length(head));
printf("------------end origin ----------------------\n\n");
printf("------------insert list----------------------\n");
head = insert_node(head, 2, 5);
printf("insert int 5 after 2th node :\n");
Print(head);
printf("------------end insert ----------------------\n\n");
printf("------------delete list----------------------\n");
head = delete_node(head, 2);
printf("delete the 3th node :\n");
Print(head);
printf("------------end delete ----------------------\n\n");
printf("------------reverse list----------------------\n");
head = reverse(head);
Print(head);
printf("------------end reverse ----------------------\n\n");
node *middle = new node();
middle = searchMidNode(head);
printf("middle index data:%d\n", middle->data);//t中间元素
system("pause");
return 0;
}
运行结果如下:
创建、查找、插入、删除、遍历都比较简单,看代码就能懂,重点理解下逆转。
假设连表如下:

逆转代码如下:
node * reverse(node * head)
{
node *p, *q, *r;
//空值判断
if (head->next == NULL)
{
return NULL;
}
p = head->next;
q = p->next;
p->next = NULL;
while (q!=NULL)
{
r = q->next;
q->next = p;
p = q;
q = r;
}
head->next = p;
return head;
}
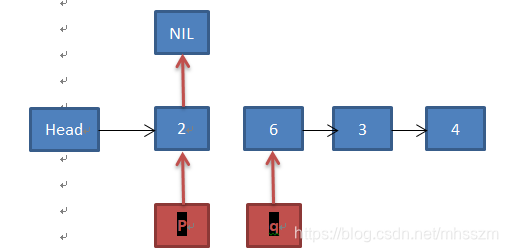
先看代码3-11行:定义三个指针p,q,r,p指向第一个结点,q指向第二个结点,并将p做为尾结点。此时的链表如下:
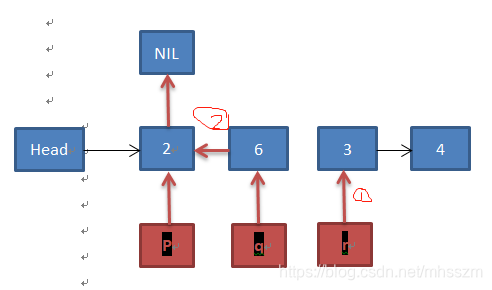
再看代码12-18行:14行,r指向q的下一个结点,见1,15行,并将p赋值给q->next,见2,16、17行进行右移操作,见3,4.
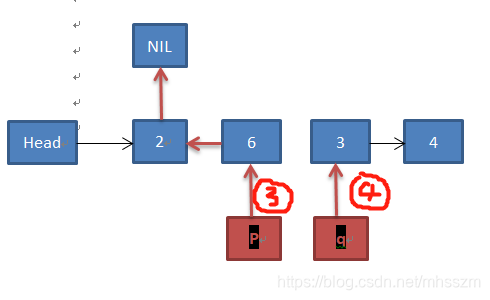
待循环结束后,再将p赋值给head,此时链表转置完成。
在创建时,head->data还一直为空,其实位置可以用来存储链表的长度,这样会给后面的操作带来方便,比如找中间位置的值,还有计算长度就没必要线性遍历了,节省了时间,在删除与增加的时候,只要更新一下此值就好。
补充一个函数:今天看到人家单链表
/*
单链表逆转:将m到n的节点逆转,其余节点不动,1 <= m <= n <= 单链表长度
日期:2017年11月3日 22:10
*/
node * reverse(node * head,int m,int n)
{
node *p, *q, *r,*a;
//空值判断
a = head;
for (int i = 1;i<m;i++)
{
a = a->next;
}
p = a->next;
q = p->next;
while (q != NULL && ++m <= n)
{
r = q->next;
q->next = p;
p = q;
q = r;
}
a->next->next = q;
a->next = p;
return head;
}
基本思路与逆转一致,只是要注意衔接、m=1情况的处理。由于本单链表自带head节点,遇到不带head节点的,可以先构造一个。 9-13行:将a指向m结点的前一个结点。 14-15行,指定p,q指针,用于逆转。16-22行,具体逆转与上一致,23-24行,用于衔接。网上还有别的做法,我觉得这种方法是比较好懂。