(1)采用数据库作为读库
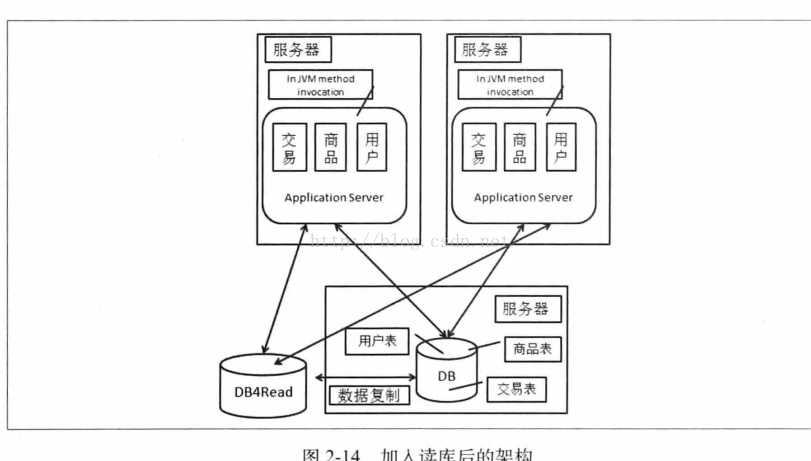
问题:数据复制问题。应用对于数据源的选择问题。
数据库系统一般都提供了数据复制的功能,我们可以直接使用数据库系统的自身机制,对于数据复制,我们还要考虑时延问题,以及复制中数据源和目标之间的映射关系和过滤条件的支持问题。数据复制延迟带来是短期数据不一致,例如修改了用户信息,但还没有复制到读库(因为时延),那么读出来的就不是最新的。
不同的数据库有不同的支持,MySQL支持Master(主库)+Slave(备库)的结构,提供了数据复制的机制,MySQl5.5之前支持的是异步的数据复制,主库执行完一些事务后,是不会管备库的进度的,若备库落后,主库有出现crash,这事备库的数据就是不完整的,我们无法使用备库来继续提供数据一致的服务了。会有延迟,并且提供的是完全镜像方式的复制,保证主库和备库数据一致性(不考虑时延),MySQL5.5加入了对semi-sync的支持,从数据安全性上,它比异步复制要好,不过从读写分离的角度,还是存在复制延迟的可能。semisync则在一定程度上保证提交的事务已经传给了至少一个备库。如果主备网络故障或者备库挂了,主库在事务提交后等待10s,超时后,关闭semi-sync特性,降低为普通的异步复制。Oracle中data Guard,分为物理备库和逻辑备库。
(2)加速数据读取---缓存
缓存系统一般是用来保存和查询键值对的(key-value)。一般在缓存中放的是“热”数据而不是全部数据,那么填充的方式是通过应用来完成的,即应用访问缓存,如果数据不存在,那么从数据库中读出数据后就放入缓存,当缓存容量不够时,需要清除数据,最近不被访问的数据就被清除了。还有一种做法是在数据库的数据发生变化后,主动把数据放入缓存系统中,相对于前种方式是,在数据变化时能够及时更新缓存中的数据,不会造成读取失效,这种方式一般用于全数据缓存情况。
(3)页面缓存