转载至:https://blog.csdn.net/MebiuW/article/details/52832847
1 前言
这个深度学习,其实是来自每周Paper笔记的整理版,即文章的主要内容其实是我对一篇文章的整理,受限于个人水平,可能很多地方会出现理解偏差、或者理解不到位的地方,所以如果发现什么不对的地方欢迎交流。之前我一直不想发这个博文,因为觉得我水平实在有限,不过现在看来还是不论好坏,拖出来见见光好了。
所以这个系列的博文的主要内容是我每周Paper阅读的笔记整理,偶尔穿插着一些实验内容。文章的具体信息我会放置于末尾,有需要的同学请根据文章题目去寻找原始论文
2 Seq2Seq是什么
网上有很多关于Seq2Seq的解释,但是从我的角度来说,我愿意把Seq2Seq看做是:
从一个Sequence做某些工作映射到(to)另外一个Sequence的任务
具体结合实际应用来说,如下的连个任务都可以看做是Seq2Seq的任务“
1、SMT翻译任务(源语言的语句 -> 目标语言的语句)
2、对话任务(上下文语句->应答语句)
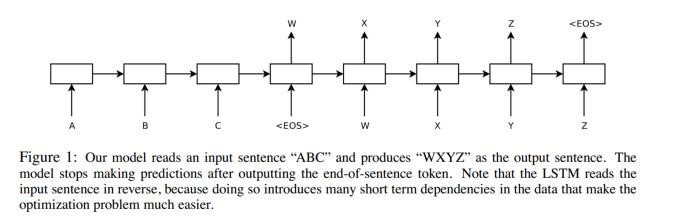
诸如上图,其实也就是一个示例(从ABC 这个Sequence 映射到 WXYZ)
3 RNN Encoder-Decoder 框架
通常来说,在深度学习中,应对这个类型的问题,有一个经典的框架被称为Encoder-Decoder:
所谓的Encoder,是将输入的Sequence编码成为一个固定长度的向量
所谓的Decoder,是根据背景Vector(即Encoder最后输出的向量)生成一个Token序列,作为输出的Sequence
这两部分Sequence的长度可以不一致。
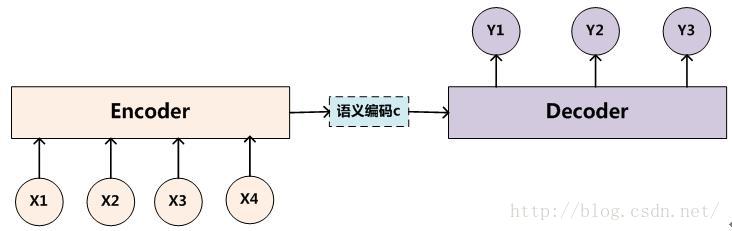
最经典的Encoder-Decoder框架,用的就是RNN,即Encoder是一个RNN,而Decoder也是一个RNN。
这里面才有极大似然去估计,让输入的Seq经过Encoder得到中间向量v,再映射到Decoder的概率最大。
这个Encoder-Decoder的框架很经典,里面用的RNN(LSTM)也是很经典的,本来想详细讲讲的,但是我水平不够,所以大概也只能讲到这里了。
关于Encoder-Decoder的详细解释可以阅读这里:http://blog.csdn.net/malefactor/article/details/51124732
而本篇文章的Sequence2Sequence的模型就是这个RNN Encoder-Decoder了,关于他的公式,其实都是基本的RNN公式,文章里讲的也不多,有需要的可以直接去阅读原文。
实验
实验部分,其采用了WMT14提供的评测任务,任务要求是英语到法语的翻译任务
1. 训练的数据集有12M的句子,包含348M法语词,和304英语词
2. 作者选择了最常用的160000个英文词和80000个法语词构造词典,初次以外的词语,都表示为UNK
3. 训练目标如下,S是原语言序列,T是目标语言序列,使得如下式子的概率最大化。并且训练后的翻译过程也是如第二个式子所示
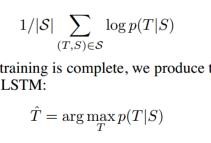
评测的标准是一个叫做BLEU的成绩,因为我不太关心翻译任务,所以我就知道越高越好的道理就好了。
而结论就是,这个模型能够十分接近WMT14的最高分(36.5 37)
讨论
这篇文章提出的Sequence2Sequnce模型很简单,但是借助于深度学习的魔力,其效果却十分的出众。
然而这个模型也正是因为太过简单,最开始使用的RNN在长句任务上表现不佳,主要表现在RNN在输入多次后使得最开始的信息出现了损失,而作为改进使用LSTM,则能够很好的解决这个问题。
同时,也有使用Attention机制的,去改善长句下的表现,关于这个机制,我会在随后的笔记中介绍的。
其实,还有一个比较好玩的是,他们发现这个Seq2Seq模型,如果我们把输入的Seq按照相反的顺序输入,其性能表现还更好(当然作者也不知道为什么)
总之,这是一个简单却很有魔力的模型,之后的工作也主要是基于这个框架,所以也作为笔记的第一篇出来。
完
--------------------- 本文来自 MebiuW 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/MebiuW/article/details/52832847?utm_source=copy