1.前言
照例先来一段废话,不要跟我说什么物质决定意识,也不要告诉我意识超越物质。在我眼中,这个世界本就是一个战场。软弱的意志自然无法战胜物质,但是足够强大的意识也是能够做到的。在战争没有进行完之前,谁也不知道结果是什么样的。包括我们的世界,我不相信它是一种刻意的设计,倒更像是一种不得已而为之。因为历史总是在不断的重复重复,肯定不是某个外在生命在循环播放电视剧。所以世界的主角就是我们,看我们的生命在这里得到了什么。
2.流程

上图就是facenet网络进行人脸识别的整体流程,我们看到总流程分为4步,第一步加载数据集、第二步使用主干网络提取特征信息,第三步neck网络进行L2正则化嵌入,第四部计算loss。不断的正向反向传播,我们最终的模型就出来了。有了一个整体的印象,下面我们详细的讲解一些每一个流程;
1.batch数据预处理
我这块只说一下facenet源码中涉及到的预处理,实际应用中需要怎么处理可自行选择。源码中的预处理包括,随机剪切、随机水平翻转、标准归一化、最后对照片进行统一尺寸(默认为160*160)
2.backbone
主干网络使用的是 inception_resnet_v1,这块就是经典的网络结构设计,在此处不展开详细讨论,后续我会专门针对常用的网络结构进行解释,敬请期待。
3.neck
颈部可以说是facenet最关键的部分,也是其发挥作用的关键。此处的原理是使用L2正则项将所有的特征值映射到一个球面上,球面上两个点的距离大小就可以用来表示相似度。如果两张照片是同一个人,则距离小,不同的人则距离大。如下

L2正则项是如何把不同的特征映射到一个球面的,假设其中一张照片的特征为。L2正则化以后就会变成
,
,
。假设球心为(0,0),那么它到球心的距离就是
,化简可得
。如果有多个特征值也是一样,这样所有的点到圆心的距离都为1,即将特征映射到了球面上。这样就将一个复杂的求照片相似度的问题,转换为了一个简单的求坐标距离的问题。至于为什么可以这么转换,我觉得应该是特征的的数值决定了其在球面上的位置,同一个人的脸数值比较接近,其位置也就比较靠近。而且这是经过伟大的作者实验出来的结果,遇事不决、量子力学,如果你无法接受我的解释,那它就暂时是玄学,如果研究明白欢迎及时联系我。
4.Triplet Loss
为什么要别出心裁的弄一个三元损失呢?我觉得真的都是被逼的。因为我们的模型需要具备一种能力,是识别两张照片是否为同一个人,因为世界上有60多亿人,如果用传统的分类损失那么类别的数量将会超级大,这样的模型是没有办法训练的。所以只能自己设计一种。
那么设计的思路是什么呢?简洁、实用。还记得逻辑回归中我们将回归的损失转换为二分类的损失,这一块需要设计一种将分类的损失转换为回归损失的办法,因为最终我们输出的是相似度。Triplet Loss的思想是,每次选择三个样本计算loss,一个是目标样本记做anchor,一个是和目标为同一个人的正样本记做positive,另一个是其它人的负样本记做negative。如图我们选择那些A到P的距离大于A到N的(这代表是分错的样本),通过模型的不断训练,将他们调节为A到P的距离小于A到N的(将它们分对),简单解释一下就是开始模型不能够分辨是否为同一人,后来可以了。
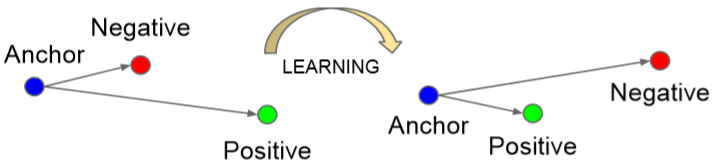

5.Triplet Selection
计算所有的点中距离最大和最小是一件不可能的事情,而且计算量庞大。所以我们设计了两种选择样本的方式,第一种offline 离线选择,方法是计算几个批次中argmin和argmax;另外一种是online,只计算一个一个小的mini-batch中的argmin和argmax。关于online和offineline我理解就是,对于单批次计算来说,假如线上新出现一个数据,我们就可以直接加入到当前的批次中进行训练,而不需要再去找前面的数据来进行计算。我们选择使用online的选择方法,但是有几点需要注意,第一是大批次,也就是说一个min_batch中的数据量要足够多;第二需要确保每个批次中有足够多的A和P,因为我们是根据AP和N时间的差异进行调节的,只有AP足够多才具有调节的意义(论文给出的实验结果是40对),然后再随机的选择负例加入批次中。
如果每次选择离的那些负样本的距离小于正样本距离,会导致模型在训练的时候过早的进入局部最优。甚至会导致模型无法收敛,比如说他找不到这样的分错的点。所以我们决定放宽一点限制,我们选择那些分对的,并且离的比较近的负样本,我们将它叫做semi-hard。如何定义里的比较近,我们引入了阈值α(默认为0.2)。所以最终我们的Triplet Loss表达式就如下:
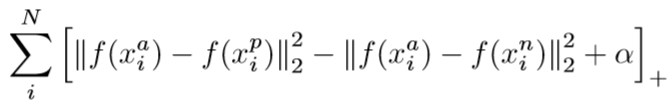
3.工程技巧
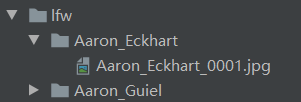
1.在样本选择方面,我们会将成对的图像信息写入到pairs.txt文件中。如下,如果有三个值表示同一个人的两幅不同的照片;如果有四个值表示两个不同人的照片。每一个人的照片存储在同一个文件夹中,用姓名加四位的整数代表不同的照片

2.使用模型进行推理的时候,我们一般先使用mtcnn网络检测出摄像头中的人脸信息,将该人脸信息和数据库中已有的信息进行比较,选择最相似的作为输出。如果是每次识别都是暴力穷举所有的数据 进行比对的话,有可能会遇到瓶颈,facebook有一个专门用来向量查找的库faiss,类似于检索的方式对 最近的向量 进行查找,可以在一定程度上提高 速度。
3.人脸入库的时候,一般需要将检测出来的人脸信息张量转换成向量的形式,然后将向量中的元素转换成字符串拼接到一起存储到数据库中。出库的时候需要对拼接的字符串进行重新解码,使其恢复成张量形式。每个编码在数据库中会对应自己的人物姓名。
4.总结
我们介绍了facenet人脸识别系统,其核心的原理就是将人脸的相似度,映射到欧式空间。然后使用特征在空间中的距离表示相似度。还有一个亮点就是引入了Triplet Loss,每次使用Anchor、Positive、Negative三个样本之间的距离差加上一个超参数α来计算损失。最后其采用Large batch的online选择样本,因为批次足够大所以选择的样本argmin和argmax也具有代表性,为了保证AP距离有意义,每个批次中必须保证足够数量的AP对(论文建议为40)。
今天白天玩的太多了,导致晚上写到这么晚。不过这种感觉也很爽,没有玩的激情哪有学的动力。一首今夜无人入眠为大家献上。
【灵魂的高歌】帕瓦罗蒂-今夜无人入睡