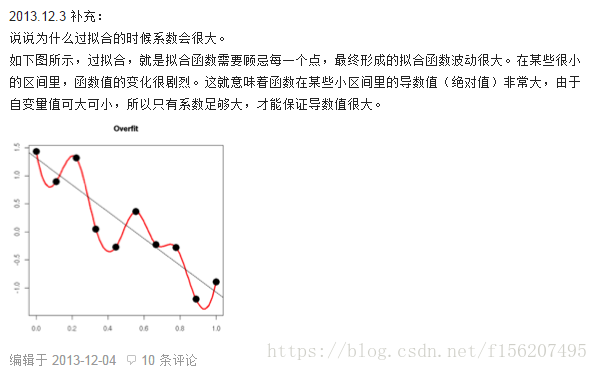
背景
在机器学习中,无论是分类还是回归,都可能存在由于特征过多而导致的过拟合问题。当然解决的办法有
(1)减少特征,留取最重要的特征。
(2)惩罚不重要的特征的权重,即降低不重要特征的权重。
但是通常情况下,我们不知道应该惩罚哪些特征的权重取值。通过正则化方法可以防止过拟合,提高泛化能力。
介绍
先来看看L2正则化方法。对于之前梯度下降讲到的损失函数来说,在代价函数后面加上一个正则化项,得到
注意是从1开始的。对其求偏导后得到
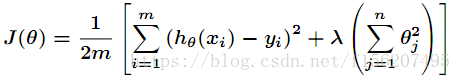
然后得到梯度下降的表达式如下
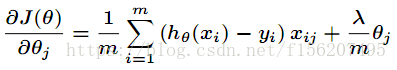
也就是说权值进行了衰减。那么为什么权值衰减就能防止overfitting呢 ?
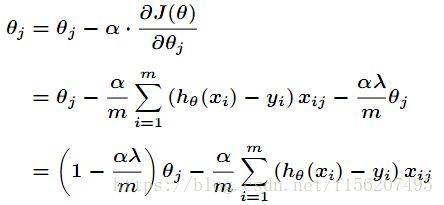
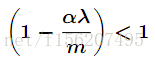
首先,我们要知道一个法则-奥卡姆剃刀,用更少的东西做更多事。从某种意义上说,更小的权值就意味着模型的复杂度更低,对数据的拟合更好。接下来,引用知乎上的解释。
(1)当权值系数更大时,会过拟合。
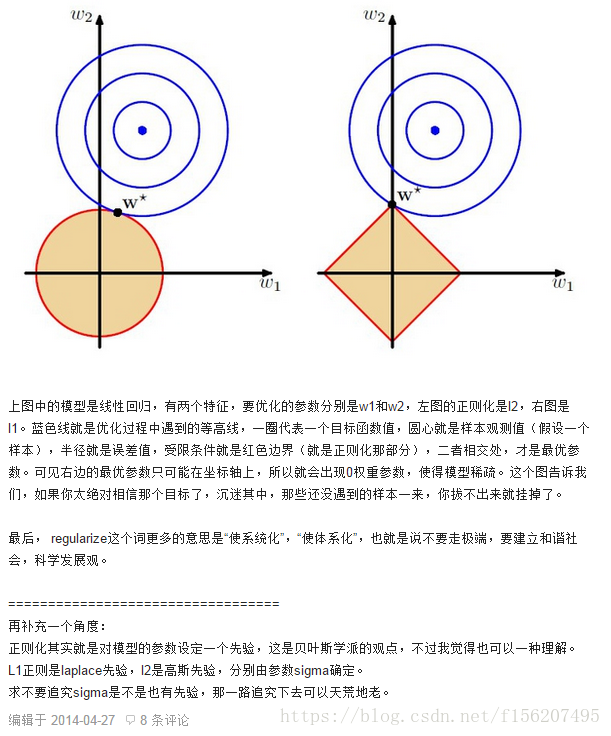
(2)在PRML中,正则化就是通过对模型的参数设定一个先验来防止过拟合。
试想一下,在上图中,如果不加正则化项,那么最优参数对应的等高线离中心点的距离可能会更近,加入正 则化项后使得训练出的参数对应的等高线离中心点的距离不会太近,也不会太远。从而避免了过拟合。