本文主要是分享一些如何使用mongodb的api来检索文档,如还不了解mongodb,请快速上手《入门手册》。
目录
1. Find/pretty
db.persons.find().pretty() ---结构化的方式来显示
db.persons.find ({条件},{键指定})
db.persons.find({}, {
name : 1,
age : 1,
country : 1,
_id : 0
})
条件操作符
| 操作 |
范例 |
RDBMS中的类似语句 |
| 等于 |
db.persons.find({"name":"lixiaoli"}) |
where by = 'lixiaoli' |
| 小于 |
db.persons.find({"age":{$lt:25}}) |
where age< 25 |
| 小于或等于 |
db.persons.find({"age":{$lte:25}}) |
where age<= 25 |
| 大于 |
db.persons.find({"age":{$gt:25}}) |
where age> 25 |
| 大于或等于 |
db.persons.find({"age":{$gte:25}}) |
where age>= 25 |
| 不等于 |
db.persons.find({"age":{$ne:25}}) |
where age!= 25 |
AND
传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件
db.persons.find({
name : "lixiaoli",
country : "Korea"
}).pretty()
OR
条件语句使用了关键字 $or
db.persons.find({
$or : [{
"name" : "lixiaoli"
}, {
"age" : 25
}
]
}).pretty()
And & Or
db.persons.find({
"country" : "USA",
$or : [{
"name" : "lixiaoli"
}, {
"age" : 25
}
]
}).pretty()
in/nin
db.persons.find({
country : {
$in : ["USA", "China"]
}
})
db.persons.find({
country : {
$nin : ["USA", "China"]
}
})
正则查询
db.persons.find({
name : /li/i
}, {
_id : 0,
name : 1
})
Not
取反操作, 查询出名字中不存在”li”的学生
db.persons.find({
name : {
$not : /li/i
}
}, {
_id : 0,
name : 1
})
$not和$nin的区别是$not可以用在任何地方儿$nin是用到集合上的
数组:all size slice .
$all对数组内元素的顺序没有要求
db.persons.find({
"books" : {
$all : ["JS","JAVA"]
}
})
. 数组索引从0开始(查询第二本书是JAVA的学习信息)
db.persons.find({
"books.1" : "JAVA"
}, {
books : 1
})
$size条件操作符,查询数组长度
db.persons.find({
"books" : {
$size : 4
}
}, {
books : 1
})
$slice数组截取,用复数即可,如-1表明截取最后一个;如[2,3],即跳过前两个,截取3个,如果剩余不足3个,就全部返回!
db.persons.find({}, {
books : {
$slice : [1, 3]
}
})
小技巧:喜欢的书籍数量大于3本的学生?
1.增加字段size
db.persons.update({},{$set:{size:4}},false, true)
2.改变书籍的更新方式,每次增加书籍的时候size增加1
db.persons.update({查询器},{$push:{books:”ORACLE”},$inc:{size:1}})
3.利用$gt查询
db.persons.find({size:{$gt:3}})
内部文档
查询出在K上过学的学生(问题:顺序?全部匹配?)
db.persons.find({
"address" : {
"city" : "上海",
"area" : "普陀区XX路"
}
})
为了解决上面顺序的问题用对象”.”的方式定位
db.persons.find({
"address.city" : "香港",
"address.area" : "中环XX路"
})
可能是版本问题,如果上面有问题请使用$elemMatch吧
where
复杂的查询我们就可以用$where因为它是万能,但是我们要尽量避免少使用它因为他会有性能的代价
小结
shell是个彻彻底底的JS引擎,但是一些特殊的操作要靠他的各个驱动包来完成(JAVA,NODE.JS)
2. Limit/skip/sort
db.persons.find({}).limit(2)
查询2~7条的数据
db.persons.find({}).limit(5).skip(2)
排序的数据[1,-1]
db.persons.find({}, {
name : 1,
age : 1
}).sort({
age : 1
})
注意:
- mongodb的key可以存不同类型的数据排序就也有优先级
最小值>null>数字>字符串>对象/文档>数组>二进制>对象ID>布尔>日期>时间戳 >正则>最大值
- skip有性能问题,
没有特殊情况下我们也可以换个思路,每次查询操作的时候前后台传值全要把上次的最后一个文档的日期保存下来,db.persons.find({date:{$gt:日期数值}}).limit(3)
3. Count
请查询persons中美国学生的人数.
db.persons.find({country:"USA"}).count()
4. Distinct
请查询出persons中一共有多少个国家分别是什么.
db.runCommand({
distinct : "persons",
key : "country"
}).values
5. Group
请查出persons中每个国家学生数学成绩最好的学生信息(必须在90以上)
db.runCommand({group:{
ns:"persons",
key:{"country":true},
initial:{m:0},
$reduce:function(doc,prev){
if(doc.m > prev.m){
prev.m = doc.m;
prev.name = doc.name;
prev.country = doc.country;
}
},
condition:{m:{$gt:90}}
}})
把个人的信息链接起来写一个描述赋值到m上
finalize:function(prev){
prev.m = prev.name+" Math scores "+prev.m
}
如果集合中出现键Counrty和counTry同时存在那分组有点麻烦这要如何解决呢?
db.runCommand({group:{
ns:"persons",
$keyf:function(doc){
if(doc.counTry){
return {country:doc.counTry}
}else{
return {country:doc.country}
}
},
initial:{m:0},
$reduce:function(doc,prev){
if(doc.m > prev.m){
prev.m = doc.m;
prev.name = doc.name;
if(doc.country){
prev.country = doc.country;
}else{
prev.country = doc.counTry;
}
}
},
finalize:function(prev){
prev.m = prev.name+" Math scores "+prev.m
},
condition:{m:{$gt:90}}
}})
6. 聚合
主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果
db.persons.aggregate([{
$group : {
_id : "$country",
total_num : {
$sum : 1
}
}
}
])
| 表达式 |
描述 |
实例 |
| $sum |
计算总和。 |
db. persons.aggregate([{$group : {_id : "$country",total_num : {$sum : "$age"}}}]) |
| $avg |
计算平均值 |
db. persons.aggregate([{$group : {_id : "$country",total_num : {$avg : "$age"}}}]) |
| $min |
获取集合中所有文档对应值得最小值。 |
db. persons.aggregate([{$group : {_id : "$country", total_num : {$min : "$age"}}}]) |
| $max |
获取集合中所有文档对应值得最大值。 |
db. persons.aggregate([{$group : {_id : "$country", total_num : {$max : "$age"}}}]) |
| $push |
在结果文档中插入值到一个数组中。 |
db. persons.aggregate([{$group : {_id : "$country", names : {$push: "$name"}}}]) |
| $addToSet |
在结果文档中插入值到一个数组中,但不创建副本。 |
db. persons.aggregate([{$group : {_id : "$country", names: {$addToSet : "$name"}}}]) |
| $first |
根据资源文档的排序获取第一个文档数据。 |
db. persons.aggregate([{$group : {_id : "$country", first_name : {$first : "$name"}}}]) |
| $last |
根据资源文档的排序获取最后一个文档数据 |
db. persons.aggregate([{$group : {_id : "$country", last_name : {$last : "$name"}}}]) |
管道操作(参考管道5.8)
db.persons.aggregate(
{ $project : {
name : 1 ,
country : 1 ,
}}
)
获取年龄大于20小于或等于50记录,然后将结果集再送到$group管道操作符进行处理
db.persons.aggregate([{
$match : {
age : {
$gt : 20,
$lte : 50
}
}
}, {
$group : {
_id : "country",
count : {
$sum : 1
}
}
}
])
7. 游标
var persons = db.persons.find();
while (persons.hasNext()) {
obj = persons.next();
print(obj.name)
}
游标销毁条件
- 客户端发来信息叫他销毁
- 游标迭代完毕
- 默认游标超过10分钟没用也会别清除
8. 快照
为什么要用查询快照?
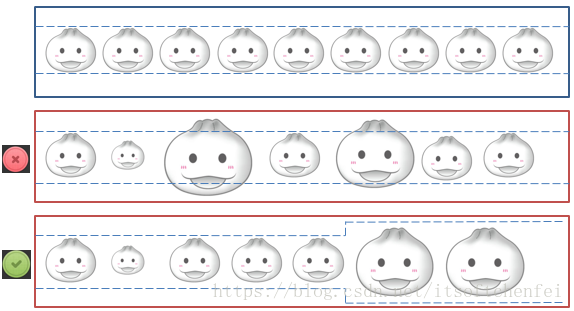
快照后就会针对不变的集合进行游标运动了,看看使用方法.
db.persons.find({
$query : {
name : "lixiaoli"
},
$snapshot : true
})
高级查询选项
$query
$orderby
$maxsan:integer 最多扫描的文档数
$min:doc 查询开始
$max:doc 查询结束
$hint:doc 使用哪个索引
$explain:boolean 统计
$snapshot:boolean 一致快照
9. $type
$type操作符是基于BSON类型来检索集合中匹配的数据类型
| 类型 |
数字 |
备注 |
| Double |
1 |
|
| String |
2 |
|
| Object |
3 |
|
| Array |
4 |
|
| Binary data |
5 |
|
| Undefined |
6 |
已废弃。 |
| Object id |
7 |
|
| Boolean |
8 |
|
| Date |
9 |
|
| Null |
10 |
|
| Regular Expression |
11 |
|
| JavaScript |
13 |
|
| Symbol |
14 |
|
| JavaScript (with scope) |
15 |
|
| 32-bit integer |
16 |
|
| Timestamp |
17 |
|
| 64-bit integer |
18 |
|
| Min key |
255 |
Query with -1. |
| Max key |
127 |
|
db.persons.find({
"name" : {
$type : 2
}
})