文章里学习需要的资料都已经打包好,下载地址:hadoop资料汇总;
下文里出现的maltose01、maltose02、maltose03…是作者的主机名,大家换为自己的linux主机名即可;
为了方便大家离线学习,整理了一份pdf版:hadoop安装配置及案例实现
本教材长期更新,砥砺前行;
hadoop安装前环境准备
一、配置jdk
将解压后的jdk复制到/usr/local目录下,修改名字为jdk18(由于本人下载的1.8版本,所以大家根据自己的实际情况修改文件夹名字),然后配置jdk环境变量:
vi /etc/profile
添加如下内容即可:
export JAVA_HOME=/usr/local/jdk18
export CLASSPATH=.:\${JAVA_HOME}/jre/lib/rt.jar:\${JAVA_HOME}/lib/dt.jar:\${JAVA_HOME}/lib/tools.jar
export PATH=\$PATH:\${JAVA_HOME}/bin
二、配置maven、ant、findbugs、
1、上传文件压缩包并解压
分别将解压后的maven、ant、findbugs复制到/usr/local目录下,分别修改名字为maven、ant、findbugs(大家根据自己的习惯来修改文件夹名字即可)
2、配置环境变量
vi /etc/profile,修改环境变量如下
export JAVA_HOME=/usr/local/jdk1.7.0_71
MAVEN_HOME=/usr/maven
export MAVEN_HOME
export ANT_HOME=/usr/ant
export FINDBUGS_HOME=/usr/findbugs
export PATH=$PATH:$JAVA_HOME/bin:/usr/maven/bin:/usr/ant/bin:/usr/findbugs/bin
source /etc/profile
执行如下命令使配置立即生效:
source /etc/profile
查看配置是否生效:
mvn -version #出现版本信息即成功
ant -version #出现版本信息即成功
findbugs -version #出现版本信息即成功
安装protobuf编译器
该编译器是用来编译hadoop的
1、先安装c语言环境:
yum -y install gcc-c++
2、上传并解压protobuf文件,复制到/usr/local/protobuf目录下
3、编译安装
进入解压后的目录,依次执行下边命令:
./configure;#初始化
make; #开始编译,时间较长
make install; #开始安装
protoc --version #出现版本信息即成功
安装其他必要的环境
yum install cmake;#一个跨平台的安装(编译)工具
yum install openssl-devel;#开发软件的包,用于编译的时候连接的库之类的文件
yum install ncurses-devel;
配置已经编译好的hadoop
如果我们对hadoop源码进行编译会非常耗时,所以直接使用官方提供已经编译好的文件即可
1、上传文件
上传hadoop压缩包,解压后放在/usr/local下,修改文件名为hadoop
2、配置hadoop(下边的文件都是在/usr/local/hadoop/etc/hadoop目录下)
core-site.xml:
<property>
<!--指定hadoop的文件系统用的是hdfs-->
<name>fs.defaultFS</name>
<!--指定namenode所在的机器,大家将maltose01换为自己的主机名即可(hostname命令可以查看主机名)-->
<value>hdfs://maltose01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!--产生的临时文件存放的目录,大家根据自己的实际情况可以进行自定义-->
<value>/home/hadoop/hdpdata</value>
</property>
hdfs-site.xml:
<property>
<!--保留文件副本的数量,这里是保留2份,每台机器有一份,默认值是3-->
<name>dfs.replication </name>
<value>2</value>
</property>
mapred-site.xml.template:
<property>
<!--指定程序要跑的平台,mapreduce程序交给yarn去跑,默认是local-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
将上边的名字进行修改(hadoop3.0以后这里不用改了,默认就是yarn-site.xml):
mv mapred-site.xml.template mapred-site.xml
yarn-site.xml:
<property>
<!--配置指定yarn集群里的老大是哪台机器,大家将maltose01改为自己的主机名即可-->
<name>yarn.resourcemanager.hostname</name>
<value>maltose01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
编辑slaves文件(hadoop3.0以后就是workers文件,没有slaves文件),该文件是为了启动自动化脚本使用的,内容是hadoop集群里所有datanode所在机器的主机名
vi slaves #开始编辑文件,文件内容是hadoop集群其他机器的主机名(即各个datanode所在机器的主机名),切记,这里不要写namenode所在机器的主机名
maltose02
maltose03
3、配置集群机器之间能互相识别
其中maltose01是namenode所在机器主机名,maltose02、maltose03是datanode所在机器主机名(切记:集群里所有机器都要配这个)
vi /etc/hosts
192.168.111.131 maltose01
192.168.111.129 maltose02
192.168.111.130 maltose03
4、在namenode所在机器配置免密登录,方便以后启动hadoop集群
ssh–keygen 一直回车直到看到一个图形为止;(注意中间没空格)
ssh-copy-id maltose01 #自己本身也要配免密登录
ssh-copy-id maltose02
ssh-copy-id maltose03
检查免密登录是否生效
ssh maltose02;
ssh maltose03;
5、上边的配置只是在一台机器上进行了配置,为了方便,我们直接将这些配置传给hadoop集群的其他机器
scp -r /usr/local/hadoop maltose02:/usr/local/
scp -r /usr/local/hadoop maltose03:/usr/local/
6、在集群里各台机器的环境变量里添加hadoop的配置
vi /etc/profile #开始编辑
export HADOOP_HOME=/home/hadoop/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile #使上边的配置生效
7、如果是hadoop3.0以上版本还要配置如下信息
hadoop安装目录下的sbin目录下
vi start-dfs.sh #添加如下代码 (stop-dfs.sh也是加下边这些配置)
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
vi start-yarn.sh #添加下边的配置 (stop-yarn.sh也是加下边这些配置)
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
开始启动hadoop集群
1、格式化,生成数据临时目录
hadoop namenode –format
2、启动namenode
进入hadoop目录执行如下命令
./sbin/hadoop-daemon.sh start namenode
3、启动datanode
进入其他机器里的hadoop目录,执行如下命令
./sbin/hadoop-daemon.sh start datanode
4、查看namenode/datamode是否启动
jps
查看到有namenode或datanode进程的话说明启动成功了
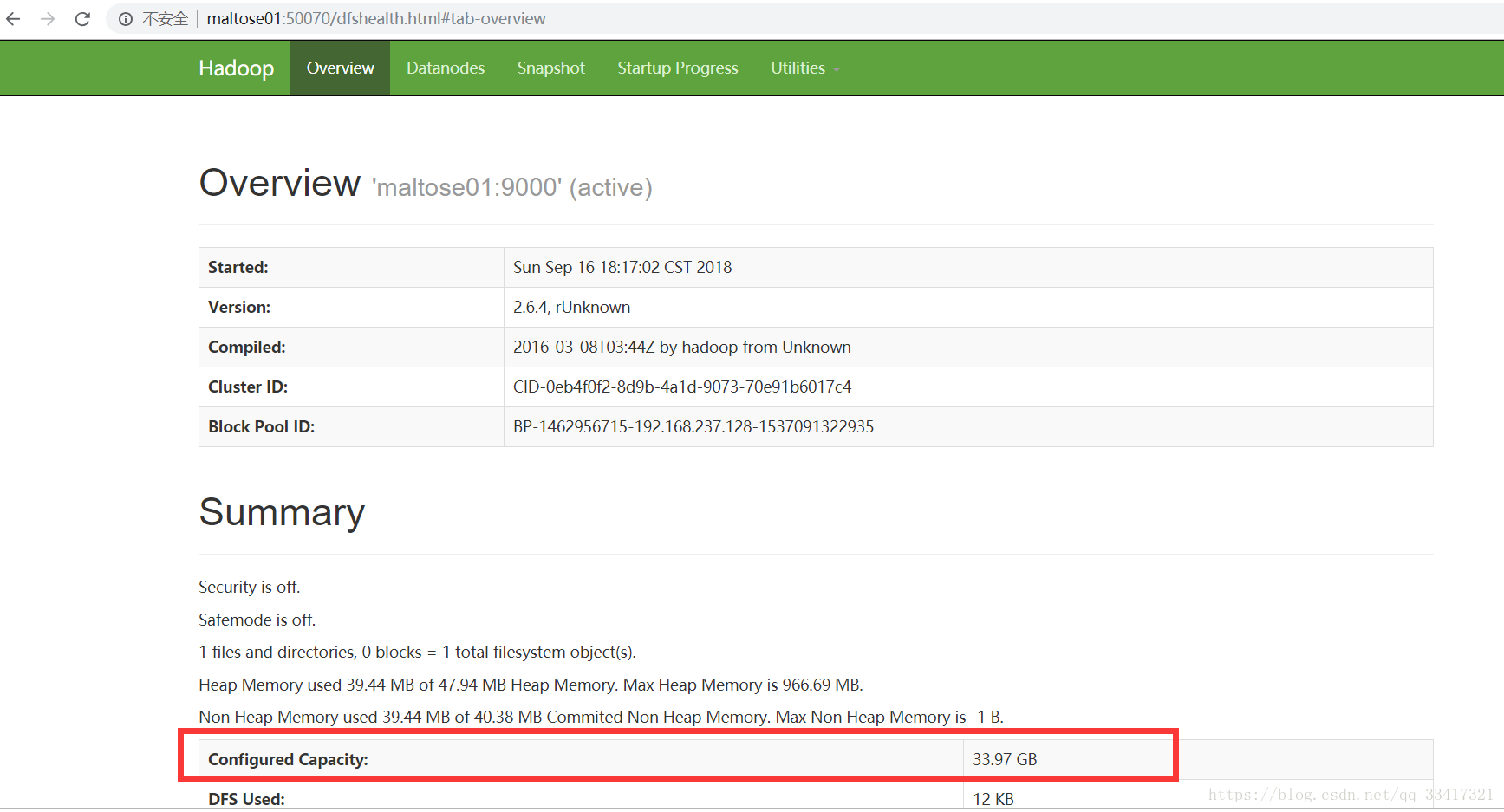
5、在浏览器查看hdfs文件系统的客户端
在地址栏直接输入:http:maltose01:50070 即可查看
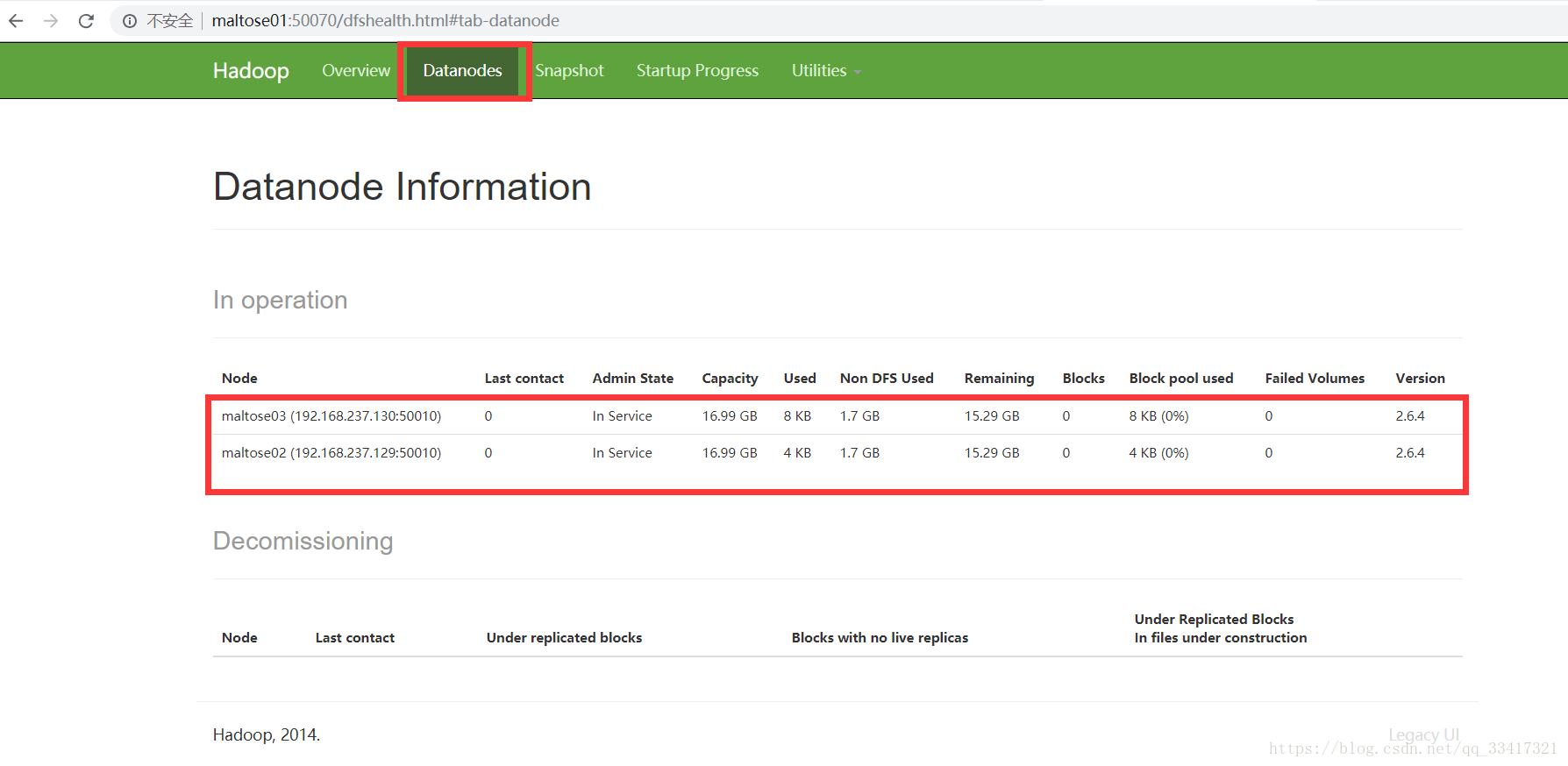
切换到datanode可查看datanode的信息:
6、在namedode所在机器停掉所有的datanode
进入/usr/local/hadoop/sbin执行如下命令
stop-dfs.sh
7、启动hdfs集群
在/usr/local/hadoop/执行命令:
sbin/start-dfs.sh
8、启动yarn集群
sbin/start-yarn.sh
9、同时启动hdfs和yarn集群
在/usr/local/hadoop/sbin里执行如下命令
start-all.sh
10、hdfs想要扩容的话,直接添加一台机器即可
操作hdfs文件系统
一、将文件上传到hdfs文件系统
1、随便创建一个文件
echo hello > haha.avi #新建haha.avi文件,文件内容是hello
2、上传文件
hadoop fs –put haha.avi #上传文件到hdfs根目录
3、查看该文件
hadoop fs –ls /
也可以在浏览器里查看刚上传的文件(地址:http:maltose01:50070):
查看该文件内容:
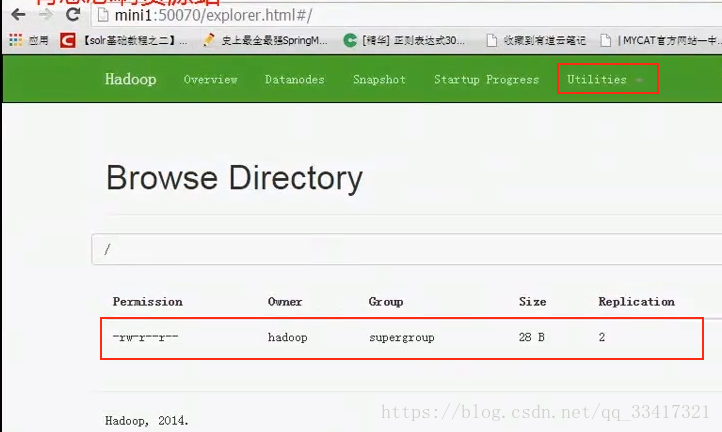
hadoop fs –cat /haha.avi
4、该文件所在本地目录
前边的目录是之前配置的临时数据目录(core-site.xml里配置的)
home/hadoop/hdpdata/dfs/data/current/BP76../current/finalized/subdir0/subdir0
二、hdfs文件系统初步理解
1、上传上去的文件的解释
上传的文件大于128M的话,文件会被切为两份,上传文件的那台机器自己两份都有;但是备份的两份,在不同的机器,这两个不同机器的两份加起来才是一份完整的文件;将这个被分开成两份的文件手动拼起来是可以解压的
cat blk_10732426 >> tmp.file
cat blk_10732427 >> tmp.file
tar –zxvf tmp.file #可以解压
2、下载hdfs上的文件
hadoop fs –get /aa.tar.gz
3、上传下载大体流程
客户端向hdfs写文件之前,先找到namenode,在namenode记录下来文件写在了哪些datanode里了,然后才开始写文件;下次任意客户端读文件的时候,也先去找namenode,找文件保存在哪个datanode里了,然后去下载文件;
三、hdfs的一些命令
| 命令 | 示例 | 功能 | 备注 |
|---|---|---|---|
| hadoop fs -help | 无 | 输出这个命令参数手册 | 无 |
| hadoop fs -ls | hadoop fs -ls hdfs://hadoop-server01:9000/ | 输出这个命令参数手册 | 这些参数中,所有的hdfs路径都可以简写,hadoop fs -ls / 等同于上前边命令的效果 |
| hadoop fs -mkdir | hadoop fs -mkdir -p /aaa/bbb/cc/dd | 在hdfs上创建目录 | 无 |
| hadoop fs -moveFromLocal | hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd | 从本地剪切粘贴到hdfs | 无 |
| hadoop fs -moveToLocal | hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt | 从hdfs剪切粘贴到本地 | 无 |
| hadoop fs --appendToFilel | hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt | 追加一个文件到已经存在的文件末尾 | 可以简写为:Hadoop fs -appendToFile ./hello.txt /hello.txt |
| hadoop fs -cat | hadoop fs -cat /hello.txt | 显示文件内容 | 无 |
| hadoop fs -tail | hadoop fs -tail /weblog/access_log.1 | 显示一个文件的末尾 | 无 |
| hadoop fs -text | hadoop fs -text /weblog/access_log.1 | 以字符形式打印一个文件的内容 | 无 |
| hadoop fs -chgrp | hadoop fs -chmod 666 /hello.txt | linux文件系统中的用法一样,对文件所属权限 | -chmod、-chown同理 |
| hadoop fs -copyFromLocal | hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ | 从本地文件系统中拷贝文件到hdfs路径去 | 无 |
| hadoop fs -copyToLocal | hadoop fs -copyToLocal /aaa/jdk.tar.gz | 从hdfs拷贝到本地 | 无 |
| hadoop fs -cp | hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 | 从hdfs的一个路径拷贝hdfs的另一个路径 | 无 |
| hadoop fs -mv | hadoop fs -mv /aaa/jdk.tar.gz / | 在hdfs目录中移动文件 | 无 |
| hadoop fs -get | hadoop fs -get /aaa/jdk.tar.gz / | 等同于copyToLocal,就是从hdfs下载文件到本地 | 无 |
| hadoop fs -getmerge | 比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…hadoop fs -getmerge /aaa/log.* ./log.sum | 合并下载多个文件(下载下来多个文件,并且合并在一起) | 无 |
| hadoop fs -put | hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 | 等同于copyFromLocal | 无 |
| hadoop fs -put | hadoop fs -rm /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 | 删除文件或文件夹 | 无 |
| hadoop fs -rmdir | hadoop fs -rmdir /aaa/bbb/ccc | 删除空目录 | 无 |
| hadoop fs -df | hadoop fs -df -h / | 统计文件系统的可用空间信息 | 无 |
| hadoop fs -du | hadoop fs -du -s -h /aaa/* | 统计文件夹的大小信息 | 无 |
| hadoop fs -count | hadoop fs -count /aaa/ /aaa/* | 统计一个指定目录下的文件节点数量 | 无 |
| hadoop fs -setrep | hadoop fs -setrep 3 /aaa/jdk.tar.gz | 设置hdfs中文件的副本数量 | <这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量> 设置完毕后可以在网页查看副本数量,显示的是元数据的副本数量,不是真实的副本数量 (比如显示的时是10,但是集群里只有5台机器,当集群里添加机器后才会真实的增加副本数量);如果显示的是10,集群里机器大于等于10的时候,这时真实的就是10个副本; |
四、使用java的API操作hdfs文件系统
使用java来对hadoop的hdfs文件系统做一些简单的增删改查
/**
*
* 客户端去操作hdfs时,是有一个用户身份的
* 默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=hadoop
*
* 也可以在构造客户端fs对象时,通过参数传递进去
* @author
*
*/
public class HdfsClientDemo {
FileSystem fs = null;
Configuration conf = null;
@Before
public void init() throws Exception{
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
//拿到一个文件系统操作的客户端实例对象
/*fs = FileSystem.get(conf);*/
//可以直接传入 uri和用户身份
fs = FileSystem.get(new URI("hdfs://master:9000"),conf,"hadoop"); //最后一个参数为用户名
}
@Test
public void testUpload() throws Exception {
//Thread.sleep(2000);
fs.copyFromLocalFile(new Path("G:/access.log"), new Path("/access.log.copy"));
fs.close();
}
@Test
public void testDownload() throws Exception {
fs.copyToLocalFile(new Path("/access.log.copy"), new Path("d:/"));
fs.close();
}
@Test
public void testConf(){
Iterator<Entry<String, String>> iterator = conf.iterator();
while (iterator.hasNext()) {
Entry<String, String> entry = iterator.next();
System.out.println(entry.getValue() + "--" + entry.getValue());//conf加载的内容
}
}
/**
* 创建目录
*/
@Test
public void makdirTest() throws Exception {
boolean mkdirs = fs.mkdirs(new Path("/aaa/bbb"));
System.out.println(mkdirs);
}
/**
* 删除
*/
@Test
public void deleteTest() throws Exception{
boolean delete = fs.delete(new Path("/aaa"), true);//true, 递归删除
System.out.println(delete);
}
@Test
public void listTest() throws Exception{
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
System.err.println(fileStatus.getPath()+"================="+fileStatus.toString());
}
//会递归找到所有的文件
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus next = listFiles.next();
String name = next.getPath().getName();
Path path = next.getPath();
System.out.println(name + "---" + path.toString());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
//拿到一个文件系统操作的客户端实例对象
FileSystem fs = FileSystem.get(conf);
fs.copyFromLocalFile(new Path("G:/access.log"), new Path("/access.log.copy"));
fs.close();
}
}
HDFS工作机制
一、整体流程概括
- HDFS集群分为两大角色:NameNode、DataNode
- NameNode负责管理整个文件系统的元数据(记录各个文件存放在哪个datanode下)
- DataNode 负责管理用户的文件数据块(不负责切块)
- 文件会按照固定的大小128M(blocksize)切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
hdfs不支持更改已经存在的某一行内容,只允许在文件后追加新内容;
二、文件上传流程
- 客户端向namenode通信请求上传文件,namenode在元数据里检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求(rpc请求)上传一个 block(0-128M),请求返回几个datanode给自己使用,具体返回几个datanode由客户端决定(该传输到哪些datanode服务器上)
- namenode返回3个datanode服务器ABC给客户端;(namenode选择要使用的datanode的原则:考虑各个datanode空间的大小,还有到各个datanode距离的大小,距离是根据网络跳转次数决定的,同一个路由器下的话,跳转一次即可;选择第一个datanode的时候选择距离近的,选第二台datanode的时候选择距离远的,这是为了安全考虑,挂了一个还有一个;第三台与第一个距离一样;)
- client请求3台ddtanode中的一台A上传数据(本质上是一个RPC调用,建立pipeline管道),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端(C应答B,B应答A,A应答给客户端)
- client开始往A上传第一个block(128M,先从磁盘读取数据放到一个本地内存缓存),以小的packet(64k)为单位进行传递,A收到一个packet就会传给B,B传给C(并不是写完整个block后才向后传);A每传一个packet会放入一个应答队列等待应答;只要成功上传到一个datanode就返回成功给客户端;校验数据是不是对的,不是以packet为单位的,而是以chunk(512Byte,每上传512字节就校验一次)为单位的
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
三、客户端读取流程
- 客户端跟namenode通信查询元数据,在元数据里找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,先在本地缓存,然后写入目标文件
- 找另一个datanode里的block…
四、secondary namenode简介
1、介绍
除了namenode与datanode外,还有secondary namenode,当元数据更新或新增时先更新内存里的数据(即元数据在内存里),记录操作日志到日志文件edits(只要元数据有变化,就在日志文件里追加记录);
旧的数据存在fsimage镜像文件里,新的文件日志存在日志文件edits里,当机器挂机后,重启时将这两个文件合并后重新计算即可恢复数据;如果机器运行很久了,则edits会很多,这样的话重启时需要加载很久,所以应该是定期将edits与fsimage合并形成新的fsfsimage,这么做的话edits就会少许多,加载就会更快;合并(checkpoint)的操作交给secondary namenode来做;
2、触发secondary namenode的条件
配置文件里会配置secondary namenode触发事件,当触发时就会执行checkpoint来合并edits与fsimage镜像生成新的fsimage;触发条件是edits里的记录数量达到一定值的时候就会触发该事件;合并后再上传到namenode,将之前的fsimage覆盖掉;
3、checkpoint附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据;
五、namenode工作机制详解
1、namenode职责
负责客户端请求的响应
元数据的管理(查询,修改)(namenode服务器一般64G或128G够用了)
2、备份多份namenode
让namenode工作目录放在多个磁盘,edits也就有多份(这是为了安全起见),修改hadoop/etc/hadoop下的hdfs-site.xml配置文件即可:
<property>
<name>dfs.name.dir </name>
<!--这里写多个目录即可-->
<value>/home/hadoop/name1, /home/hadoop/name2 </value>
</property>
配置完毕后需要重新初始化目录:
hadoop name –format #重新初始化文件目录,如果不改配置的话,该命令只执行一次即可,以后不用再执行了,多次执行会出错(找不到datanode)
MapReduce
一、简介
- Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
- Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
- 分布式的运算程序往往至少需要分成2个阶段,第一阶段的task任务实例互不相干,各做各的事情,完全并行;第二阶段的task任务实例任然互不相干,但是他们的数据可能依赖上一个阶段task并发实例的全局(上一个task所有实例)输出;
- MapReduce就是只有这两个阶段,如果程序复杂,通过这两个阶段搞不定的话就在来一个MapReduce;MapReduce编程模型只能包含一个map阶段和一个reduce阶段;上边说的第一阶段就是map阶段(运行的实例就是map task阶段),第二阶段是reduce(运行的实例就是reduce task实例)
二、案例
1、统计一个文件里每个单词出现的次数
统计过程梳理:
- 读数据
- 按行来处理
- 按空格切分行内单词
- 定义HashMap(单词,value+1)
- 等分给自己的数据片全部读完后,将hashmap按照首字母范围分成3个hashmap(比如a-g,h-o,p-z三个阶段),遍历hashmap,分别将其放入对应的三个hashmap里;
- 然后将三个hashmap分别传给三个reduce task
- 三个map task同时都在做这个事情,假如有4个MapReduce,每个reduce task都会收到4个map task
mr application master:
上边map task与reduce task之间的通信逻辑很复杂,此时就需要有主管来管理,即mr application master;
map阶段:
/**
*四个泛型解释:
* KEYIN: 默认情况下,是mr框架所读到的一行文本的起始偏移量,Long类型,(一行一行读,每读一行,就将起始偏移量传到KEYIN里了)
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
*
* VALUEIN:默认情况下,是mr框架所读到的一行文本的内容,String类型;同上,使用hadoop自己的接口,用Text
*
* KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String,同上,用Text
* VALUEOUT:是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,同上,用IntWritable
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**
* map阶段的业务逻辑就写在自定义的map()方法中 (后边还有reduce阶段),多个maptask都可以调用这里的map方法
* maptask会对每一行输入数据调用一次我们自定义的map()方法;mapTask程序调这里的业务方法时,每读一行调一次(一次只传一行数据进来)
*将输入数据传进来,放在这个方法的三个参数里
*参数一:输进来数据里,每一行的起始偏移量
*参数二:每一行的内容
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将maptask传给我们的一行文本内容先转换成String
String line = value.toString();
//根据空格将这一行内容切分成单词
String[] words = line.split(" ");
//将单词输出为<单词,1> 即将数据保存为map集合的形式,键是单词,值是数字1
for(String word:words){
//将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
//比如读到三个hello,则就会有三个<hello,1>集合;根据reduce机制(假设按首字母),这三个<hello,1>后来会存在同一个reduce里,在reduce里进行相同单词的汇总
context.write(new Text(word), new IntWritable(1));
}
}
reduce阶段(由reduce task来调该代码):
/**
*泛型参数一与二: KEYIN, VALUEIN(输入类型) 对应 mapper输出的KEYOUT,VALUEOUT类型
*
*参数三与四: KEYOUT, VALUEOUT 是自定义reduce逻辑处理结果的输出数据类型(单词与总次数),即:
* KEYOUT是单词
* VLAUEOUT是总次数
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* 进来的参数是这种格式的:
* <angelababy,1><angelababy,1><angelababy,1><angelababy,1><angelababy,1> key就是angelababy,把所有的1加起来就是angelababy这个单词的总次数(传key的时候传的是这个组里的第一个angelababy)
* <hello,1><hello,1><hello,1><hello,1><hello,1><hello,1> key就是hello,把所有的1加起来就是hello这个单词的总次数,key是第一个hello
* <banana,1><banana,1><banana,1><banana,1><banana,1><banana,1> key就是banana,把所有的1加起来就是banana这个单词的总次数,key是第一个banana
* 入参key(参数1),是一组相同单词kv对的key
*参数二:key对应的value的迭代器,即一组value
*这个方法要做的就是把每个组里的value累加起来得到每个单词的总次数
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
/*Iterator<IntWritable> iterator = values.iterator();
while(iterator.hasNext()){
count += iterator.next().get();
}*/
for(IntWritable value:values){
count += value.get();
}
/*得到某一个单词(key)的总个数(count)
默认将结果写到在hdfs里的多个文件中,每一个文件里只包含一部分单词,文件所在目录在程序里配置
*/
context.write(key, new IntWritable(count));
}
}
封装mapReduce:
/**
* 相当于一个yarn集群的客户端(yarn去分配运算资源)
* 需要在此封装我们的mr程序的相关运行参数,指定jar包
* 最后提交给yarn(yarn在集群里运算程序)
*
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
if (args == null || args.length == 0) {
args = new String[2];
args[0] = "hdfs://master:9000/wordcount/input/wordcount.txt";
args[1] = "hdfs://master:9000/wordcount/output8";
}
Configuration conf = new Configuration();
//设置的没有用! ??????
// conf.set("HADOOP_USER_NAME", "hadoop");
// conf.set("dfs.permissions.enabled", "false");
/*conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "mini1");*/
Job job = Job.getInstance(conf);
/*job.setJar("/home/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径(这样写,无论jar包在哪,都可以获取到jar包路径)
job.setJarByClass(WordcountDriver.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job的输入原始文件所在目录,可以传多个文件路径(路径在hdfs里),以逗号分隔
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录(hdfs目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
/*
上边的提交方式,提交后这个类就运行完了,但是集群还在运行,而我们不知道集群是否正常运行,所以
用下边这种提交方式:
集群运行时,这里阻塞等待集群的运行,以便获取集群运行的进度信息,集群那边返回结果后这里才退出
*/
boolean res = job.waitForCompletion(true);//参数true代表将集群里的信息打印出来
System.exit(res?0:1);
}
}
打包上传:
- 将上边三个类所在的项目打成jar包(怎么打包自己百度,假设打包后的名字是wordcount.jar);注意,打包后,生成的jar文件只有本地的程序,而本地程序引用到的其他jar没有打进去,但是我们打的这个jar还是可以运行的,因为hadoop里已经存在了其他需要的jar包;
- 在hadoop目录里创建文件夹:
hadoop fs mkdir -p /wordcount/input - 将hadoop之前已经存在的三个文件放入该目录:
hadoop -fs -put NOTICE.txt README.txt LICENSE.TXT /wordcount/input - 将前边打好的jar包传在任意一台linux上(可以是namenode所在的机器,也可以是datanode所在机器)
- 执行打包的程序:
java -cp wordcount.jar com.maltose.bigdata.WordCountDriver /wordcount/input /wordcount/output - 不出意外的话上边命令会报错,就是因为找不到wordcount.jar里依赖的其他jar文件,将上边命令换成下边的即可:
hadoop jar wordcount.jar com.maltose.bigdata.WordCountDriver /wordcount/input /wordcount/output
在浏览器查看yarn:
查看输出目录:
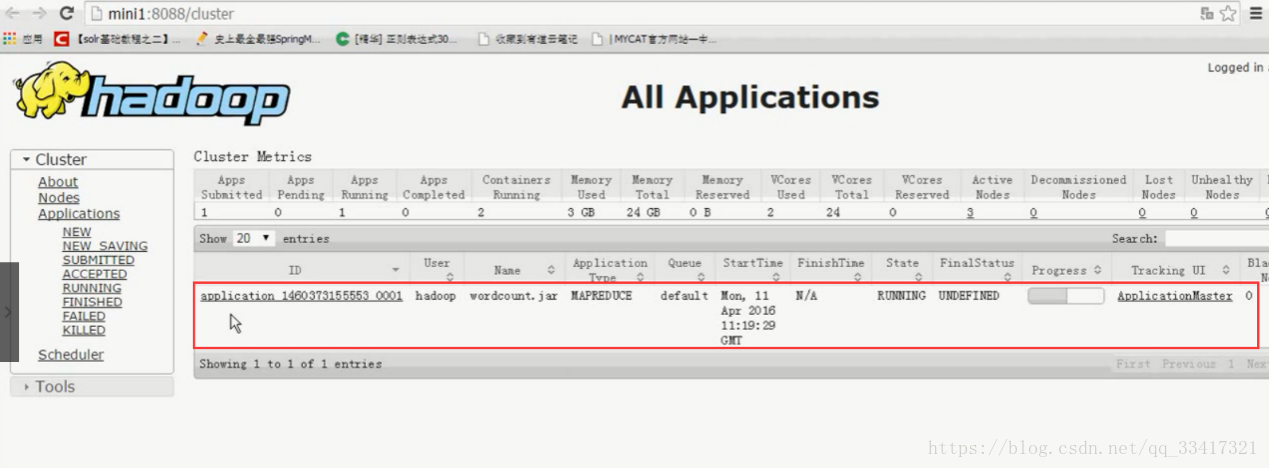
hadoop fs -ls /wordcount/output
只看到一个文件,因为reduce task默认只有一个;
查看该文件:

hadoop fs -cat /wordcount/output/part-r-00000 | more
可以看到单词个数统计结果;

上边程序解释
编程规范:
- 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
- Mapper的输入数据是KV对的形式(KV的类型可自定义)
- Mapper的输出数据是KV对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- map()方法(maptask进程)对每一个K/V调用一次
- Reducer的输入数据类型对应Mapper的输出数据类型,也是K/V
- Reducer的业务逻辑写在reduce()方法中
- Reducetask进程对每一组相同k的k/v组调用一次reduce()方法
- 用户自定义的Mapper和Reducer都要继承各自的父类
- 整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
source /etc/profile
流程:
/wordcount/input目录下有若干个文件(a.txt,b.txt,c.txt…),每个文件里都有许多单词;将上边的三部分代码写完后,yarn启动一个mr appmaster,mr appmaster绝地启动一些maprask来做这件事情,mr appmaster怎么知道启动几个maptask去做?
WordcountDriver类客户端,在最后一步提submit的时候,会去hdfs查看,得到有多少待统计的文件以及每个文件的大小,根据这些得到的参数形成一个任务分配的规划,规划里的内容大致内容就是:a.txt里的0-128M分配一个maptask,128-256M分配一个maptask,b.txt里0-128M分配一个maptask,128-256M分配一个maptask等等;这个规划写在一个配置文件里job.split(job的切片),job还有个jar包wc.jar,job里还有个配置参数job.xml,submit就是把job这些文件提交给yarn,yarn会根据job的jar包以及配置文件把mr appmaster启动起来,此时mr appmaster会得到job的所有参数,拿上这些参数去判断应该启动几个map task进程,假设启动三个;maptask读数据是通过hdfs的api去读的;maptask通过InputFormat里的方法读数据,一次读一行,得到key/value,key是起始偏移量,value是读到的文本内容,将这个key/value交给我们自定义的WordCountMapper类的map(key,value)方法,方法最后输出context.write(key,value),将输出的context.write(key,value)再交给map task的组件outputCollector输出收集器,将每一行的数据收集起来,存在本机的一个文件上,这个文件是分区且排序的,根据后边有几个reduce task就分为几个区(每个区最后给不同的reduce task去处理),三个map task都会生成这个文件;mr appmaster再启动reduce task,reduce task与map task可能在同一个机器运行,reduce task要等待map task都处理完后才开始处理,否则拿到的数据不全;
前边三个map task分别生成三个文件,假如每个文件有三个区,每个文件的第一个区给reduce task1,每个文件的第二个区给reduce task2,每个文件的第三个区给reduce task3,reduce task1得到的数据:<hello,1><hello,1><banana,1><banana,1><banana,1>,
reduce task2得到的数据:<good,1>< good,1>< good,1><tail,1>< tail,1>,
reduce task2得到的数据:<tom,1>< tom,1>< jack,1><jack,1>< lele,1>,
reduce task1拿上一组数据<hello,1><hello,1>去调用自定义的类WordcountReducer的reduce(key,it-values)方法,其中参数里的key就是第一和hello,参数二是迭代器,方法最后输出contex.write(key,value),调用outputFormat组件里的方法,将数据不断追加到hdfs里的文件里,该文件默认名字是part-r-00000,part-r-00001,part-r-00002…;
上边的map task到reduce task之间有很多细节,即SHUFFLE;