@Author : Spinach | GHB
@Link : http://blog.csdn.net/bocai8058起源
Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase 中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。
虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而获得很好的性能提升。
于是,HBase在0.92之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
两种类型:Observer和Endpoint
Observer
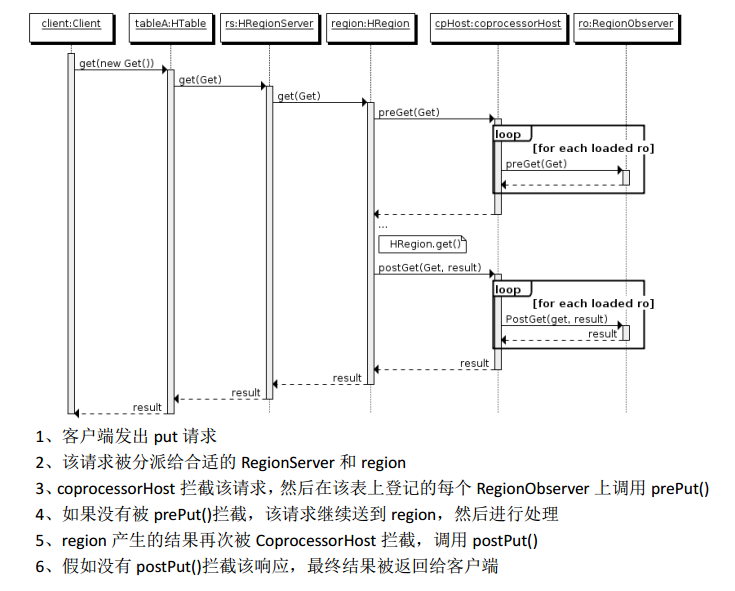
Observer类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server端调用。Observer Coprocessor就是一些散布在HBase Server端代码中的hook钩子,在固定的事件发生时被调用。
比如:put操作之前有钩子函数prePut,该函数在put操作执行前会被Region Server调用;在put操作之后则有postPut钩子函数。
以HBase0.92版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan 等。
- WALObserver:提供WAL相关操作钩子。
- MasterObserver:提供DDL类型的操作钩子。如创建、删除、修改数据表等。到0.96版本又新增一个RegionServerObserver。
下图是以RegionObserver为例子讲解Observer这种协处理器的原理:
Endpoint
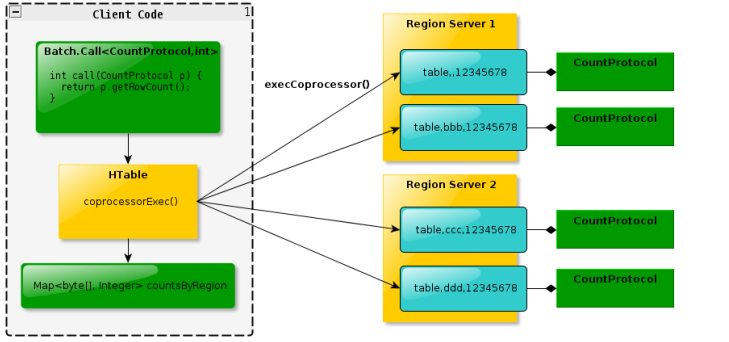
Endpoint协处理器类似传统数据库中的存储过程,客户端可以调用这些Endpoint协处 理器执行一段Server端代码,并将Server端代码的结果返回给客户端进一步处理,最常 见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即max聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到Client端统一执行,势必效率低下。利用Coprocessor,用户可以将求最大值的代码部署到HBase Server端,HBase将利用底层cluster的多个节点并发执行求最大值的操作。即在每个Region范围内执行求最大值的代码,将每个Region的最大值在Region Server端计算出,仅仅将该max值返回给客户端。在客户端进一步将多个Region的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。
下图是 EndPoint 的工作原理:
协处理器加载方式
协处理器的加载方式有两种,我们称之为静态加载方式(Static Load) 和动态加载方式(Dynamic Load)。 静态加载的协处理器称之为 System Coprocessor,动态加载的协处理器称 之为 Table Coprocessor
静态加载方式(Static Load)
//修改hbase-site.xml文件
//启动全局aggregation,能过操纵所有的表上的数据。只需要添加如下代码:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>动态加载方式(Dynamic Load)
//启用表aggregation,只对特定的表生效。通过HBase Shell来实现。
//disable指定表。
hbase> disable 'mytable'
//添加aggregation
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
# 解释:coprocessor的四个参数,分别用‘|’隔开
1. 你的协处理器jar包所在hdfs上的路径
2. 协处理器类全限定名
3. 协处理器加载顺序
4. 传参
//重启指定表
hbase> enable 'mytable'//卸载需要以下三步:
disable 'mytable'
alter 'mytable', METHOD =>'table_att', NAME => 'coprocessor$1'
enable 'mytable'二级索引案例
row key在HBase中是以B+ tree结构化有序存储的,所以scan起来会比较效率。单表以row key存储索引,column value存储id值或其他数据,这就是Hbase索引表的结构。
由于 HBase 本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到 RowKey中,这是HBase开发中极为常见的做法
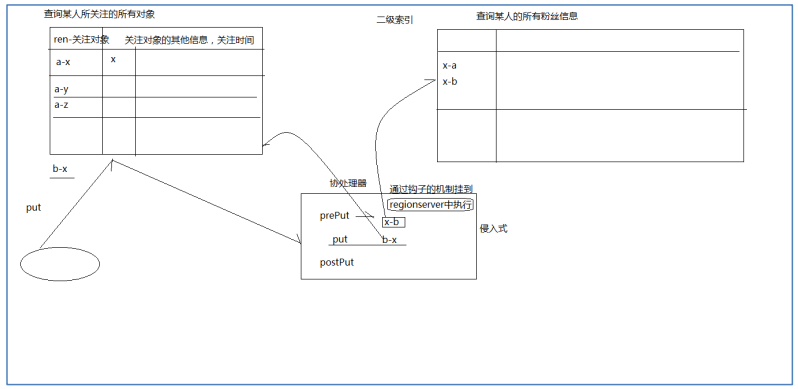
在社交类应用中,经常需要快速检索各用户的关注列表guanzhu,同时,又需要反向检索各 种户的粉丝列表fensi,为了实现这个需求,最佳实践是建立两张互为反向的表:
//一个表为正向索引关注表:“guanzhu”
Rowkey : a
f1:from b
//另一个表为反向索引粉丝表:“fensi”
Rowkey : b
f1:from a插入一条关注信息时,为了减轻应用端维护反向索引表的负担,可用 Observer 协处理器实 现:
总结
- Observer 允许集群在正常的客户端操作过程中可以有不同的行为表现;
- Endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令;
- Observer 类似于RDBMS中的触发器,主要在服务端工作;
- Endpoint 类似于RDBMS中的存储过程,主要在client端工作;
- Observer 可以实现权限管理、优先级设置、监控、ddl 控制、二级索引等功能;
- Endpoint 可以实现min、max、avg、sum、distinct、group by等功能;
引用:https://www.cnblogs.com/liuwei6/p/6837674.html