HBase客户端查询存在的问题
- Scan
用Get/Scan查询数据, - Filter
用Filter查询特定数据
以上情况只适合几千行数据以及不是很多的列的“小数据”。
当表扩展为亿万行及百万列时,在通过网络传递移动大量的数据导致网络拥堵,且客户端需要足够多内存来处理这么大量数据的计算操作,另外,客户端代码也会变的大而复杂。
解决方案
移动计算比移动数据更划算
Coprocessor将运算移动到数据所处的节点。
什么是Coprocessor?
简单来说,Coprocessor是一个框架,这个框架可以让你很容易地在Region Server运行你的业务逻辑代码。
Coprocessor类比
- Triggers and Stored Procedure
- Observer Coprocessor –> RDBMS 中的触发器
- EndPoint Coprocessor –> RDBMS中的存储过程
- MapReduce
MapReduce 和 Coprocessor有一样的操作原则,计算向数据靠拢。
- AOP
类似面向切面编程,Coprocessor就像应用Advice,在传递请求到最终的目的地之前,通过拦截一个请求后运行相同的代码。
Coprocessor分类
Observer Coprocessor
在一个特定的事件发生前或发生后触发。
- 在事件发生前触发的Coprocessor需要重写以pre作为前缀的方法,比如prePut。
- 在事件发生后触发的Coprocessor使用方法以post作为前缀,比如postPut。
Endpoint
是一个远程rpc调用,类似于webservice形式调用,但他不适用xml,而是使用的序列化框架是protobuf(序列化后数据更小).
区别:Observer像是个触发器,到某个条件Region就去执行用户代码,用户从主观来说是无法控制的;EndPoint就是远程调用,用户可以在客户端远程调用执行自己的代码。
Observer Coprocessor使用场景与实现
Observer Coprocessor的使用场景如下:
安全性:在执行Get或Put操作前,通过preGet或prePut方法检查是否允许该操作;
引用完整性约束:HBase并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是我们可以使用Coprocessor增强这种约束。比如根据业务需要,我们每次写入user表的同时也要向user_daily_attendance表中插入一条相应的记录,此时我们可以实现一个Coprocessor,在prePut方法中添加相应的代码实现这种业务需求。
二级索引:可以使用Coprocessor来维持一个二级索引。这里暂不展开,有时间会单独说明。
Observer在Hbase中主要分为四类,均继承Coprocessor接口:
- RegionObserver 针对于Region的观察者(Region打开、关闭、刷新、合并等工作)
- RegionServerObserver 针对RegionServer的观察者(Region合并、分裂、日志回滚等)
- MasterObserver 针对Master的观察者(表创建、删除、Region移动、拆分等工作)
- WALObserver 针对WAL的观察者(日志写)
EndPoint使用场景与实现
Endpoint允许定义自己的动态RPC协议,用于客户端与region servers通讯。Coprocessor 与region server在相同的进程空间中,因此您可以在region端定义自己的方法(endpoint),将计算放到region端,减少网络开销,常用于提升hbase的功能,如:count,sum等。
工作过程如下图所示过程:
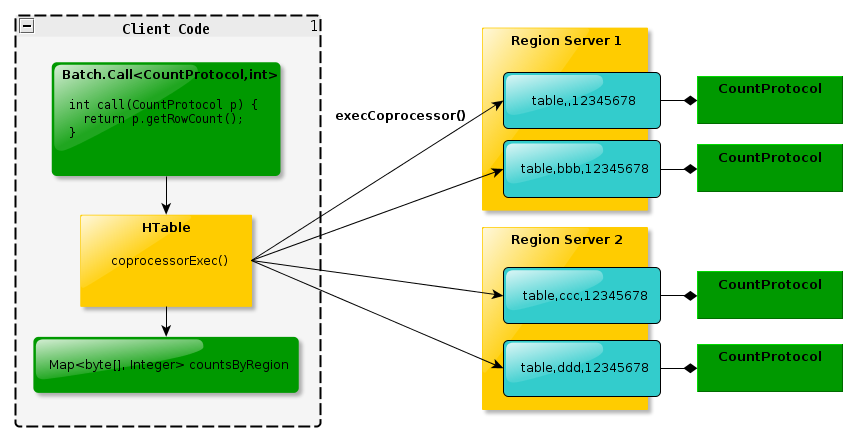
- 不管是通过配置还是表描述加载了EndPoint协处理器
- 在Client执行CoprocessorExec()调用对应的RPC方法
- 在对应的每个region中都会执行该方法后返回结果
- EndPoint实现
- 创建一个“.proto”文件定义服务
- 执行protoc命令,通过“.proto”文件生成Java代码
- 编写一个Coprocessor类,实现Coprocessor和CoprocessorService两个接口,并实现接口中定义的方法:
- 加载Coprocessor
- 编写客户端代码调用Coprocessor
装载Coprocessor
装载Coprocessor分为静态装载和动态装载。
静态装载Coprocessor
- 静态装载过程:
-
- hbase-site.xml中创建记录
-
- 将代码放到HBase的类路径下。一个简单的方法是将封装好的jar(包括代码和依赖)放到HBase安装路径下的/lib目录中。
-
- 重启HBase。
- 静态卸载的步骤如下:
- 移除在hbase-site.xml中的配置。
- 重启HBase。
- 这一步是可选的,将上传到HBase类路径下的jar包移除。
动态装载Coprocessor
动态装载Coprocessor的一个优势就是不需要重启HBase。不过动态装载的Coprocessor只是针对某个表有效。因此,动态装载的Coprocessor又被称为表级Coprocessor。
此外,动态装载Coprocessor是对表的一次schema级别的调整,因此在动态装载Coprocessor时,目标表需要离线。
动态装载Coprocessor有两种方式:通过HBase Shell和通过Java API。
- 通过HBase Shell动态装载
- 使用Java API动态装载和卸载
http://www.zhyea.com/2017/04/13/using-hbase-coprocessor.html#Observer-Coprocessors
达摩克利斯之剑
Coprocessor是HBase的高级功能,本来是只为HBase系统开发人员准备的。因为Coprocessor的代码直接在RegionServer上运行,并直接接触数据,这样就带来了数据破坏的风险,比如“中间人攻击(Man-in-the-MiddleAttack,简称“MITM攻击”,见百度词条)”以及其他类型的恶意入侵。目前还没有任何机制来屏蔽Coprocessor导致的数据破坏。此外,因为没有资源隔离,一个即使不是恶意设计的但表现不佳的Coprocessor也会严重影响集群的性能和稳定性。
其他公司实践
二级索引设计
Phoenix的Salting功能非常有效,但对延迟影响较大,因此若延迟要求较高,那么Salting则并不合适,所以这里在主表与索引表中不使用Salting功能,而是采用reverse将主键列散列。索引中使用Function Index和Function Index减少查询延迟。